【ICLR2023】PatchDCT: Patch Refinement for High Quality Instance Segmentation
【本文贡献】
本文是对论文《DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation》的改进,提出了PatchDCT,这是目前已知的第一个基于压缩向量的多级细化检测器,用于预测高质量的掩码,相比DCTMask有了很大的性能提升。
【网络结构】
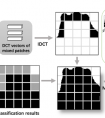
PatchDCT将mask分为很多独立的patch,对每个patch进行精炼,每个patch的mask可以通过DCT转换为向量。
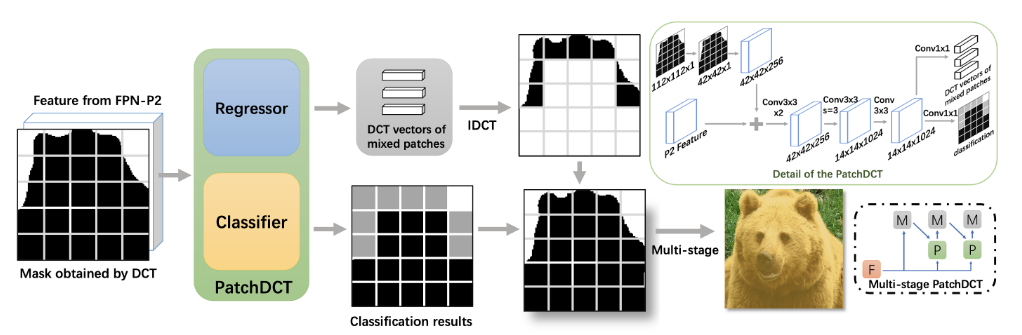
网络分为回归器regressor和分类器classifier两个分支,classifier是个三分类器,使用卷积层来区分前景、背景和前景与背景的融合部分;regressor是个边界关注模块,对每个融合部分的patch预测一个n维的DCT向量,再将处理好的融合部分叠加到classifier生成的结果中。PtachDCT的输入和输出尺寸相同,可以使用多个PatchDCT模块进行多阶段精炼,右下的示意图中的F是从FPN-P2裁剪出来的feature map,M是高分辨率掩码,P是PatchDCT模块。
【心得体会】
DCT掩码聚合度高,复杂度低,可以运用到基于像素的图像处理任务中,获得更紧凑的编码,提高效率。
提取特征时可以在高分辨率的图上使用DCT进行编码。
【ICLR2023】SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation
【本文贡献】
提出了一种新的挤压增强轴向变压器(SeaFormer)框架,用于移动端的语义分割。
设计了一种以挤压轴向和细节增强为特征的通用注意块。
除了语义分割之外,进一步将提出的SeaFormer架构应用于图像分类问题。
【网络结构】
该网络先对图像进行1/2、1/4和1/8的下采样,再分别用两个分支进行处理,红色的是上下文分支,蓝色的是空间分支,上下文分支交替使用了MobileNetV2(MV2)和SeaFormer Layers,中间使用Fusion block对两个分支进行融合,使用卷积和sigmoid提取权重信息,再将权重信息与空间分支相乘,连续迭代三次后使用Light segmentation head进行处理。
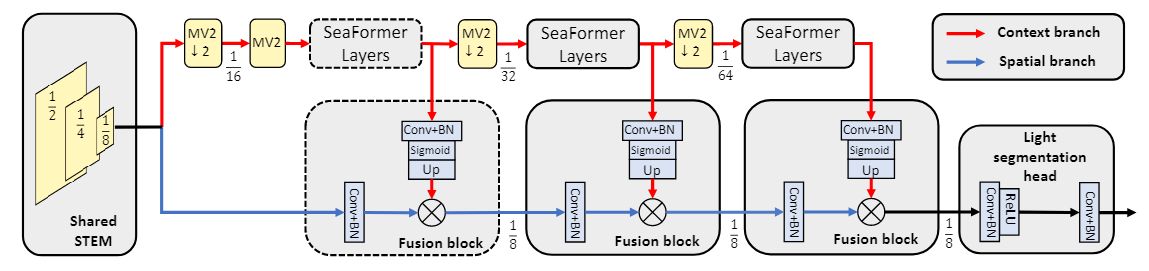
SeaFormer采用了轴向注意力机制,先对q,k,v分别进行池化,再转换维度,分别使用横向压缩和纵向压缩得到H*1*Cp和1*W*Cp的两个向量,对这两个向量分别计算多头自注意力,再将得到的结果进行广播,将两个结果扩大为相同的维度再进行相加。
为了增强细节信息,SeaFormer中使用了Detail enhancement kernel,通过该kernel得到的结果与压缩的轴向注意力的计算结果进行相乘,得到最终的注意力。
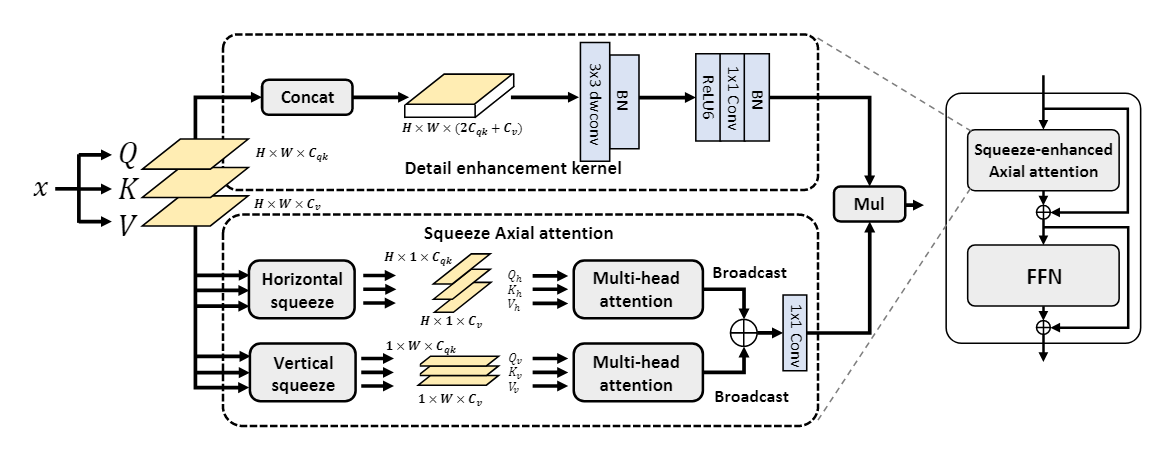
【心得体会】
可以尝试使用拆分的方式搭建注意力模块,比如本文中的将轴向注意力拆分为横向和纵向,多使用一个分支来补充轴向注意力欠缺的局部信息。
【TMM2023】DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition
【本文贡献】
提出了一种滑动窗口扩展注意力(SWDA),在周围区域中稀疏选择的patch中计算自注意力。
提出了多尺度扩展注意力(MSDA),同时捕获不同尺度的语义依赖,进一步利用被关注的接受域内的信息。
采用金字塔架构设计了多尺度膨胀Transformer(DilateFormer),在浅层阶段堆叠MSDA以捕获低层次信息,在较深层次阶段堆叠全局多头自注意力以模拟高级交互,在计算复杂度和参与的接受域大小之间寻求更好的平衡。
【网络结构】
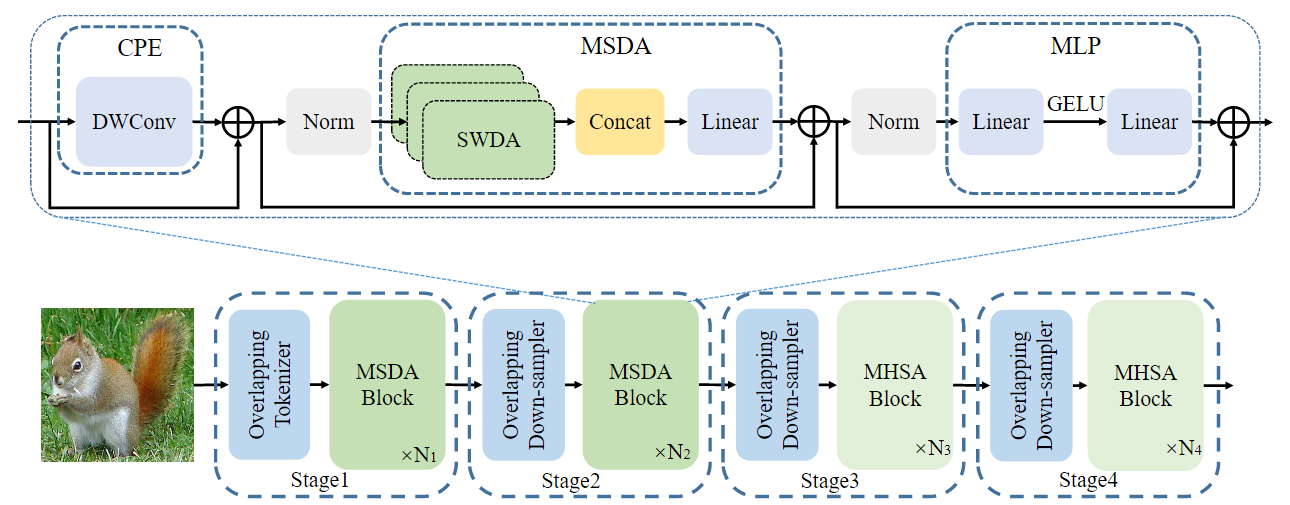
该网络主要是融合了多尺度和空洞卷积,增大了感受野,改善了全局依赖。网络整体为金字塔架构,主要创新点为MSDA以及MSDA中包含的SWDA。
SWDA即Sliding Window Dilated Attention,它以一个原始的像素点作为一个token,按照膨胀系数r选取周围的8个像素点进行计算。这里为每一个head设置了不同的膨胀系数,有利于聚合多尺度信息。
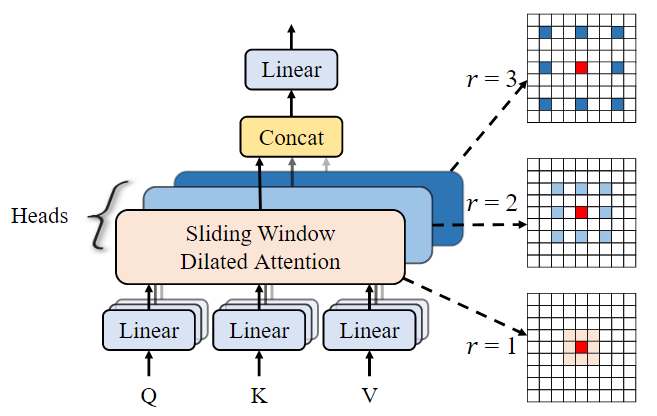
【心得体会】
可以通过多尺度信息的引入来改进Attention的结构,比如在多头自注意力部分引入多尺度信息,并且在消融实验中说明引入的多尺度信息是否有效、多尺度信息的相关参数如何设置能达到较好的效果。
【CVPR2022】MixFormer: End-to-End Tracking with Iterative Mixed Attention
【本文贡献】
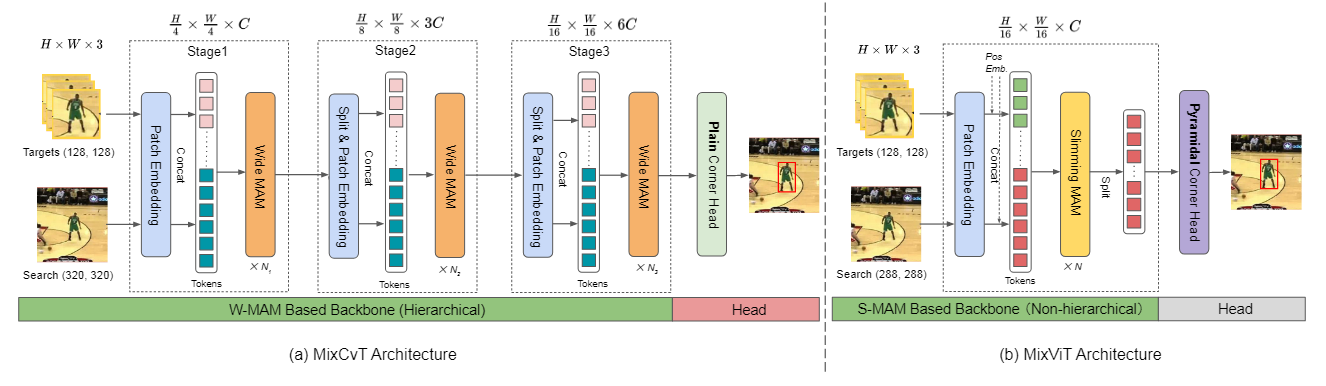
提出了一个基于混合注意力模块(MAM)的紧凑的端到端跟踪框架,称为MixFormer,MAM允许同时提取目标特定特征和目标与搜索之间的广泛联系。
实例化了两种类型的 MixFormer跟踪器,一种是具有渐进下采样和深度卷积投影的分层跟踪器(与 MixCvT 一致),另一种是建立在普通ViT基础上的非分层跟踪器(称为 MixVT),并为MixVT 设计了一个金字塔角头,补充多尺度信息,实现准确的目标定位。
【网络结构】
本文将图像跟踪网络中的特征提取、目标集成两个模块整合到了一个Transformer上,构建出了MixFormer。该网络对来自每个序列本身的token进行自注意力计算,从自身中提取特征,并同时对来自两个序列的token之间进行交叉注意力计算,实现目标和搜索之间的通信,以上功能是通过MixFormer中的MAM模块实现的。
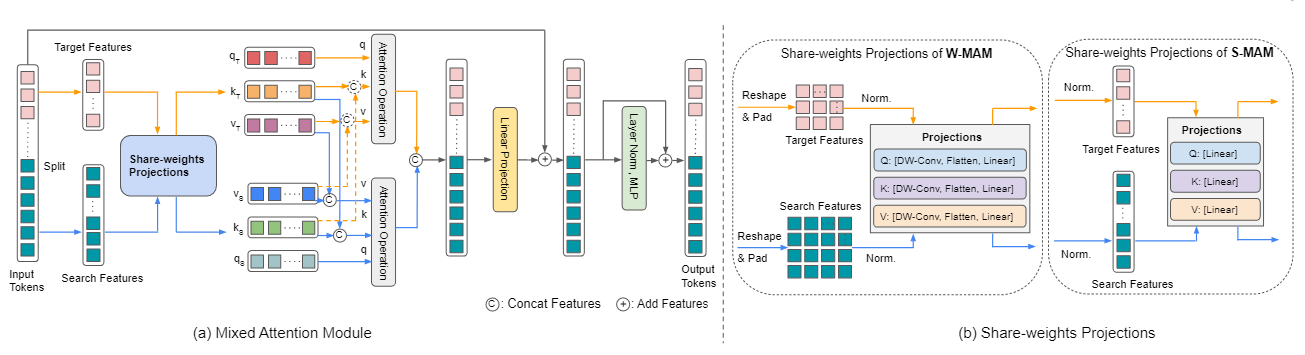
MixFormer是对MAM的堆叠。
【心得体会】
今后的工作中可以尝试对特征进行拼接融合。
【AAAI2023】ShadowFormer: Global Context Helps Image Shadow Removal
【本文贡献】
引入了一种基于Retinex的阴影模型,提出了一种新的基于多尺度通道注意力框架的阴影去除Transformer(ShadowFormer)。
【网络结构】
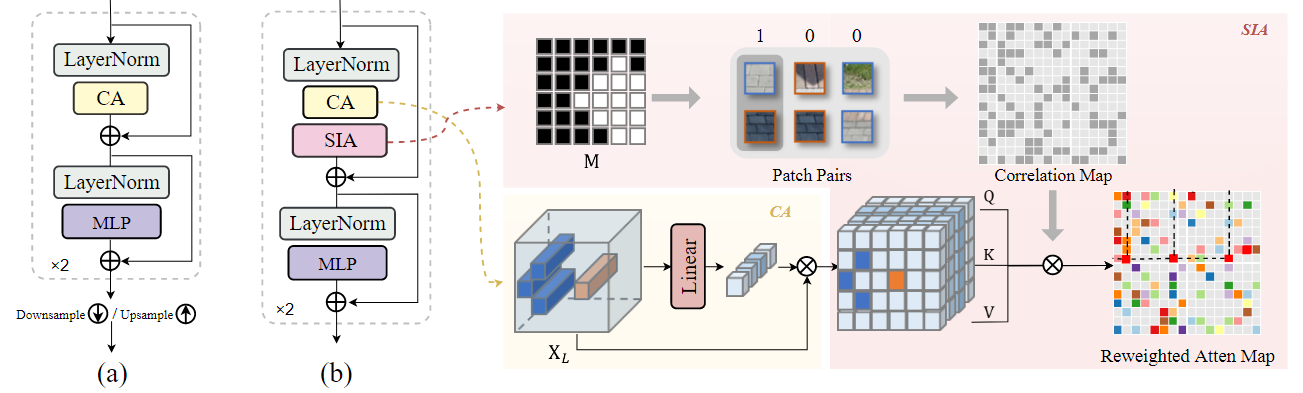
本文考虑了阴影部分与非阴影部分的全局相关性,并且提出了阴影部分与非阴影部分在光照等方面存在联系,设计了Shadow-Interaction Attention,总体架构是一个Encoder-Decoder的结构,在Encoder和Decoder都堆叠使用通道注意力来获得多尺度特征。同时在中间使用提出的Shadow-Interaction Module,每次特征图大小缩小到一半,通道数扩大一倍。

Shadow-Interaction Module模块中采用了类似窗口注意力的架构,使用池化操作减少了计算量,使用了异或操作来帮助获得更显著的权重。
【心得体会】
本文的mask是给定的,本文提出的ShadowFormer不仅适用于阴影去除,也适用于有先验的情况下的图像修复。
【TMI2022】MISSFormer: An Effective Medical Image Segmentation Transformer
【本文贡献】
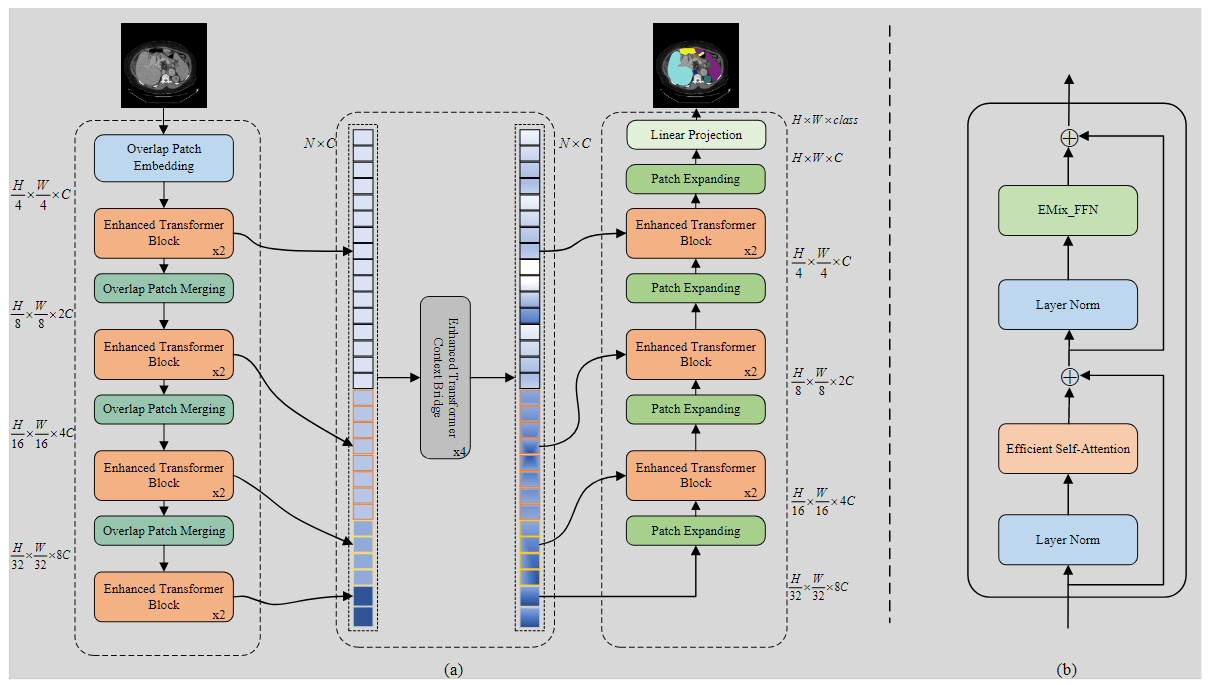
提出了MISSFormer,这是一个位置无关的分层U-Net,用于医学影像分割。
设计了一个强大的前馈网络,Enhanced Mix-FFN,并对其进行扩展,得到了Enhanced Transformer Block以增强特征表示能力。
基于Enhanced Transformer Block,设计出了Enhanced Transformer Context Bridge,用于捕获分层多尺度特征的局部和全局相关性信息。
【网络结构】
该网络为U形结构,采用了encoder-decoder架构,并在encoder和decoder之间添加了增强的Transformer上下文桥接模块。对输入的图片,先划分为4*4的重叠的patch来保持与卷积层的局部连续性,在把这些patch输入到encoder,产生多尺度特征,再将多尺度特征通过增强的Transformer上下文桥接模块来获取不同尺度特征的局部和全局相关性。decoder部分主要由增强的Transformer和patch扩展层组成,patch扩展层对相邻特征进行上采样,最后通过Linear Projection输出经过分割的图像。
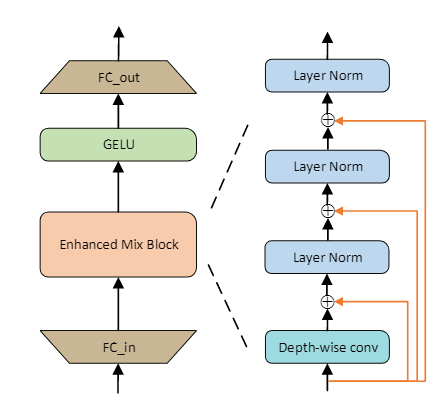
该网络重新设计了Mix-FFN的结构,在dw卷积之前添加跳跃连接,在跳跃连接后使用Layer Norm,实现了特征对齐。
增强的Transformer上下文桥接模块结构如下,先对分层encoder生成多级特征在空间维度上展开,保持相同的通道深度,再在空间维度上进行拼接,将连接的token输入到增强的Transformer中,构建长期依赖和局部上下文相关性。

【心得体会】
可以通过在U-Net中的encoder和decoder之间添加适当的上下文桥接模块来改善特征提取能力。
【CVPR2022】FMCNet: Feature-Level Modality Compensation for Visible-Infrared Person Re-Identification
【本文贡献】
提出了FMCNet,为VI-ReID提出了特征级而不是图像级特定模式的信息补偿,有助于生成一些特定模式的特性。
【网络结构】
FMCNet中对于rgb图像和红外图像的处理是对称的,都是先经过SFD模块生成各自的特定特征+共享特征,再对二者的共享特征进行融合,通过FMC模块中的生成对抗网络生成相对于各自模块的模态特定特征,再使用SFF模块将原本的模态特定特征和FMC模块生成的模态特定特征进行相加,再和共享特征进行concat。
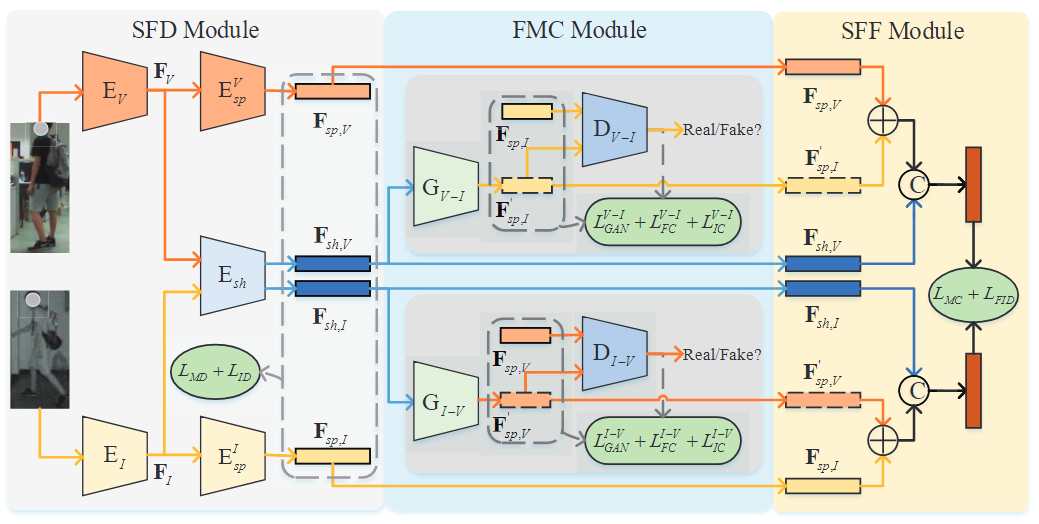
【心得体会】
对于在RGB图和红外图之间做匹配的VI-ReID任务,可以尝试在特征范围内步长模态的特定信息。