
写在前面
在本文中,我们利用Nixtla的NeuralForecast框架,实现多种基于Transformer的时序预测模型,包括:Transformer, Informer, Autoformer, FEDformer和PatchTST模型,并且实现将它们应用于股票价格预测的简单例子。
1
NeuralForecast
neuralforecast 是一个旨在为时间序列预测提供一个丰富的、高度可用和鲁棒的神经网络模型集合的工具库。这个库集成了从传统的多层感知器(MLP)和递归神经网络(RNN)到最新的模型如N-BEATS、N-HiTS、TFT,以及其他高级架构,以适应多样化的预测需求。它的关键功能包括对静态、历史和未来的外生变量的支持,提高了模型在实际应用中的灵活性。库中的模型提供了良好的预测可解释性,允许用户绘制趋势、季节性以及外生预测组件。neuralforecast 还实现了概率预测,通过简单的适配器支持量化损失和参数分布,增加了预测结果的置信度。此外,它提供了自动模型选择功能,通过并行自动超参数调整来高效确定最优的模型配置。库的简洁接口设计与SKLearn兼容,确保了易用性,并且训练和评估损失的计算能够适应不同的比例,这为不同规模的数据集提供了灵活性。最后,neuralforecast 包含了一个广泛的模型集合,包括但不限于LSTM、RNN、TCN、N-BEATS、N-HiTS、ESRNN以及各种基于Transformer的预测模型等,都是以即插即用的方式实现,方便用户直接应用于各种时间序列预测场景。这些特性使得neuralforecast 成为那些寻求高效、精确且可解释时间序列预测模型的研究人员和实践者的有力工具。本文将利用neuralforecast 实现各种Transformer模型,并展示将它们应用于股票价格预测的简单例子。
2
环境配置
本地环境:
Python 3.8IDE:Pycharm库版本:
Pandas version: 2.0.3Matplotlib version: 3.7.1Neuralforecast version: 1.6.4为了使用最新的其他模型,也可以直接fork neuralforecast的源码:
git clone https://github.com/Nixtla/neuralforecast.gitcd neuralforecastpip install -e .3
代码实现
步骤 1: 导入所需的库
导入库:首先,导入处理数据所需的 pandas 库,绘图所需的 matplotlib.pyplot 库,以及 neuralforecast 中的多个模块。这些模块包括各种预测模型和评估指标函数。
import pandas as pdfrom neuralforecast.models import VanillaTransformer, Informer, Autoformer, FEDformer, PatchTSTfrom neuralforecast.core import NeuralForecastimport matplotlib.pyplot as pltfrom neuralforecast.losses.numpy import mae, rmse, mse步骤 2: 数据准备
读取数据:使用 pandas从 CSV 文件加载数据。这个数据集包含股票的每日收盘价。
数据预处理:重命名列以符合模型的输入要求(例如,将日期列重命名为 'ds',将收盘价列重命名为 'y')。此外,将日期列转换为日期时间格式,并为数据集添加一个唯一标识符,这对于使用neuralforecast进行时间序列预测是必要的。
df = pd.read_csv('./000001_Daily_Close.csv')df['unique_id'] = 1df = df.rename(columns={'date': 'ds', 'Close': 'y'})df['ds'] = pd.to_datetime(df['ds'])步骤 3: 定义预测模型
初始化模型:定义一个模型列表,每个模型都是 neuralforecast 库中的一个类的实例。对于每个模型,指定预测范围(horizon)、输入窗口大小(input_size)以及其他训练参数(如 max_steps, val_check_steps)。
模型配置:这些参数决定了模型的训练方式,包括训练持续时间、评估频率和早停机制等。每个模型都有一些公共的参数以及它们自身的参数可以调整,这里均使用它们默认的参数进行模型初始化。
models = [VanillaTransformer(h=horizon, input_size=input_size, max_steps=train_steps, val_check_steps=check_steps, early_stop_patience_steps=3, scaler_type='standard'), Informer(h=horizon, # Forecasting horizon input_size=input_size, # Input size max_steps=train_steps, # Number of training iterations val_check_steps=check_steps, # Compute validation loss every 100 steps early_stop_patience_steps=3, # Number of validation iterations before early stopping scaler_type='standard'), # Stop training if validation loss does not improve FEDformer(h=horizon, input_size=input_size, max_steps=train_steps, val_check_steps=check_steps, early_stop_patience_steps=3), Autoformer(h=horizon, input_size=input_size, max_steps=train_steps, val_check_steps=check_steps, early_stop_patience_steps=3), PatchTST(h=horizon, input_size=input_size, max_steps=train_steps, val_check_steps=check_steps, early_stop_patience_steps=3), ]步骤 4: 模型训练与交叉验证
创建 NeuralForecast 实例:使用 NeuralForecast 类整合所有的模型。这个类提供了一个统一的接口来训练和评估多个模型。
执行交叉验证:使用 cross_validation 方法对每个模型进行训练和评估。这个方法自动进行时间序列的交叉验证,分割数据集并评估模型在不同时间窗口上的性能。
nf = NeuralForecast( models=models, freq='B')Y_hat_df = nf.cross_validation(df=df, val_size=100, test_size=100, n_windows=None)步骤 5: 数据筛选
筛选数据点:通过选择特定的“cutoff”点来过滤 Y_hat_df 中的预测。这种筛选基于预测范围 horizon,确保评估是在均匀间隔的时间点上进行。
Y_plot = Y_hat_dfcutoffs = Y_hat_df['cutoff'].unique()[::horizon]Y_plot = Y_plot[Y_hat_df['cutoff'].isin(cutoffs)]步骤 6: 绘图与性能评估
绘制预测结果:使用 matplotlib 绘制真实数据与每个模型的预测结果。这有助于直观地比较不同模型的预测准确性。
计算评估指标:对每个模型,计算和打印均方根误差(RMSE)、平均绝对误差(MAE)和均方误差(MSE)等性能指标。这些指标提供了量化模型性能的方式。
plt.figure(figsize=(20, 5))plt.plot(Y_plot['ds'], Y_plot['y'], label='True')for model in models: plt.plot(Y_plot['ds'], Y_plot[model], label=model) rmse_value = rmse(Y_hat_df['y'], Y_hat_df[model]) mae_value = mae(Y_hat_df['y'], Y_hat_df[model]) mse_value = mse(Y_hat_df['y'], Y_hat_df[model]) print(f'{model}: rmse {rmse_value:.4f} mae {mae_value:.4f} mse {mse_value:.4f}')plt.xlabel('Datestamp')plt.ylabel('Close')plt.grid()plt.legend()plt.show()步骤 7: 结果展示
展示图表:最后,显示绘制的图表。图表展示了不同模型在整个时间序列上的预测表现,允许直观地评估和比较模型。
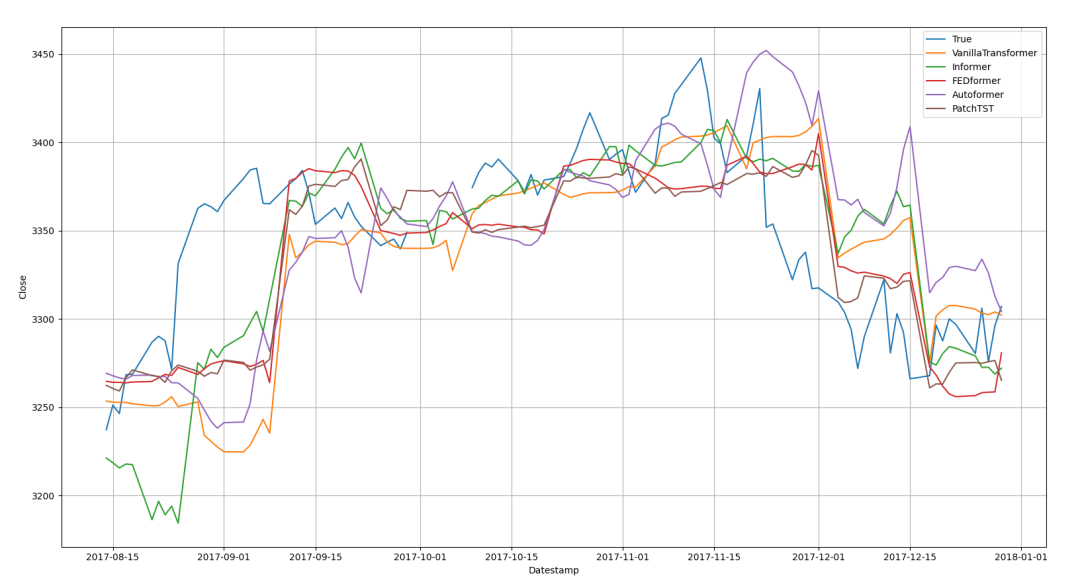
VanillaTransformer: rmse 56.5187 mae 38.8573 mse 3194.3650Informer: rmse 52.2324 mae 39.1110 mse 2728.2239FEDformer: rmse 48.9400 mae 35.9884 mse 2395.1237Autoformer: rmse 58.5010 mae 45.7157 mse 3422.3614PatchTST: rmse 48.5870 mae 36.1392 mse 2360.6968在对比基于 Transformer 的各种模型在股票价格预测任务上的表现时,从可视化以及评估结果中,我们发现 FEDformer 和 PatchTST 在所有评估指标(RMSE、MAE、MSE)上表现最为出色,这可能归因于它们在处理长期依赖关系和捕获时间序列数据中的复杂模式方面的优势。相较之下,虽然 Informer 显示了合理的性能,但其表现略逊于 FEDformer 和 PatchTST。VanillaTransformer 和 Autoformer 的性能相对较差。这些结果强调了根据特定任务的需求选择合适的模型架构的重要性,同时也表明了在实际应用中进行模型选择时需要考虑到模型的特定优势和潜在的局限性。
4
总结
本文展示了如何使用 neuralforecast 实现多种 Transformer 模型(包括 Informer, Autoformer, FEDformer 和 PatchTST),并将它们应用于股票价格预测的简单示例。通过这个演示,我们可以看到 Transformer 模型在处理时间序列数据方面的潜力和灵活性。虽然我们的实验是初步的,但它为进一步的研究和应用提供了一个基础。读者可以在此基础上进行更深入的模型调优、特征工程和超参数实验,以提升预测性能。此外,这些模型的应用不限于股票价格预测,还可以扩展到其他领域的时间序列分析。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
获取完整代码与数据以及其他历史文章完整源码与数据可加入《人工智能量化实验室》知识星球。
往期推荐阅读
WWW 2023 | 量化交易相关论文(附论文链接)
IJCAI 2023 | 量化交易相关论文(附论文链接)
KDD 2023 | 量化交易相关论文(附论文链接)
AAAI 2022 | 量化交易相关论文(附论文链接)
IJCAI 2022 | 量化交易相关论文(附论文链接)
WWW 2022 | 量化交易相关论文(附论文链接)
KDD 2022 | 量化交易相关论文(附论文链接)
解读:ChatGPT在股票市场预测方面的应用
解读:通过挖掘概念间共享信息,实现股票趋势预测的图模型框架
解读:机器学习预测收益模型应该采取哪种度量指标
解读:基于订单流、技术分析与神经网络的期货短期走势预测模型
【python量化】挖掘股价中的图关系:基于图注意力网络的股价预测模型
【python量化】基于backtrader的深度学习模型量化回测框架
【python量化】将Transformer模型用于股票价格预测
【python量化】搭建一个CNN-LSTM模型用于股票价格预测
【python量化】用python搭建一个股票舆情分析系统
【python量化】将Informer用于股价预测
【python量化】将DeepAR用于股票价格多步概率预测

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。





 ';
$username = getcvar('mlusername');
$userid=getcvar('mluserid');
$rnd = getcvar('mlrnd');
if($username&&$userid&&$rnd){
$user_r = sys_ShowMemberInfo($userid,'ui.userpic');
$userpic=$user_r[userpic]?$user_r[userpic]:$public_r[newsurl].'e/extend/lgyPl/assets/nouserpic.gif';
$userpiclink = '
';
$username = getcvar('mlusername');
$userid=getcvar('mluserid');
$rnd = getcvar('mlrnd');
if($username&&$userid&&$rnd){
$user_r = sys_ShowMemberInfo($userid,'ui.userpic');
$userpic=$user_r[userpic]?$user_r[userpic]:$public_r[newsurl].'e/extend/lgyPl/assets/nouserpic.gif';
$userpiclink = '