Mamba[1] 是一种先进的 state-space model (SSM),专为高效处理复杂的数据密集型序列而设计。它最近发表在由主要研究人员 Albert Gu 和 Tri Dao 撰写的论文“Mamba: Linear-Time Sequence Modeling with Selective State Spaces”中。

Mamba 因其在语言处理、基因组学和音频分析等各个领域的应用而脱颖而出。这种创新模型采用线性时间序列建模架构,该架构结合了选择性状态空间,可在不同模式(包括语言、音频和基因组学)中提供一流的性能。
这种突破性的模型代表了机器学习方法的重大转变,这可能会提高效率和性能。
Mamba 的主要优势之一是能够解决与传统 Transformer 在处理长序列时相关的计算挑战。通过将选择机制集成到其状态空间模型中,Mamba 可以根据序列中每个token的相关性有效地决定是传播还是丢弃信息。这种选择性方法可显着加快推理速度,吞吐率比标准 Transformer 高出五倍,并展示了随序列长度的线性缩放。值得注意的是,即使在序列扩展到一百万个元素的情况下,Mamba 的性能也会随着实际数据的不断提高而不断提高。

重要性
Mamba 由于其特殊功能(其组织良好的状态空间模型方法及其与强大的计算机硬件的兼容性)而在机器学习模型领域中独一无二。
首先,它以与其处理的数据长度相匹配的方式运行得更快。
这与其他型号不同。
其次,Mamba 的核心有一个特殊的层,可以在每一步中智能地选择关注或忽略哪些信息。
最后,它的设计灵感来自于 FlashAttention,这使得它非常适合我们现在拥有的功能强大的计算机。
这种功能组合帮助 Mamba 比许多现有模型表现得更好,包括基于Transformer方法的模型,这种方法在各种人工智能应用中很流行。

快速推理
Mamba 的优势之一是快速完成prompts,展现出其快速思考的能力。此外,它可以有效地处理大批量数据,保持较高的准确性和速度。
技术优势
要充分了解 Mamba 的特殊之处,您需要仔细查看其技术细节。它最适合在 Linux 计算机上与 NVIDIA 显卡配合使用。 Mamba 使用 PyTorch 1.12+ 和 CUDA 11.6+ 的功能来实现出色的效率和性能。此外,使用 pip 命令可以轻松安装 Mamba,这使得它对于广大受众(包括学术界和工业界人士)来说非常友好。
Benchmark
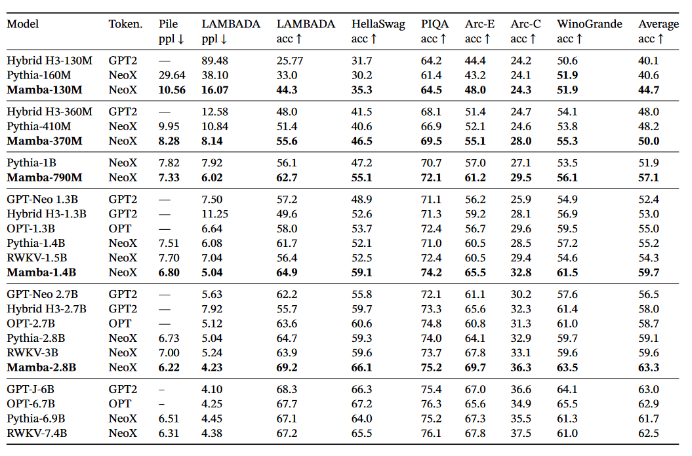
Mamba 在一系列流行的下游零分评估任务上的表现。将这些模型与最著名的开源模型进行比较,最重要的是 Pythia 和 RWKV,它们使用与我们的模型相同的token、数据集和训练长度(300B token)进行训练。 (请注意,Mamba 和 Pythia 的训练上下文长度为 2048,而 RWKV 的训练上下文长度为 1024)。
关键点
Mamba 模型将选择性结构化状态空间模型 (SSM) 集成到简化的端到端神经网络架构中,特别是缺乏传统的注意力机制。据说Mamba-3B模型的性能优于同尺寸的Transformer,在性能方面可与两倍尺寸的Transformer相媲美。与类似大小的 Transformer 相比,1.4B Mamba 语言模型的推理吞吐量是其 5 倍,其质量与两倍大小的 Transformer 相当。这种创新设计在语言建模任务中表现出了卓越的性能,无论是在预训练阶段还是在各种下游评估中,都超越了类似的 Transformer 模型。
Mamba 的一个突出特点是它能够随着上下文长度的增加逐步提高性能,有效管理多达一百万个元素的序列。这一功能强调了 Mamba 作为通用序列处理应用的基础模型的多功能性和潜力。它在需要处理长上下文序列的新兴领域(例如基因组学、音频和视频)具有特别的前景。其设计的核心是一种专为结构化状态空间模型量身定制的新颖选择机制,该机制使模型能够执行上下文相关的推理,同时保持序列长度的线性可扩展性。
Mamba 通过序列长度的线性缩放 (~O(N)) 改变了规则,这比传统 Transformer 的二次缩放 (~O(N²)) 有了巨大的改进。这意味着 Mamba 可以有效处理多达 100 万个元素的序列,这是当前 GPU 技术实现的壮举。
Mamba 通过有效利用更大的数据集和网络来产生更智能的结果而脱颖而出。它挑战了这样一种观念:仅仅拥有更多数据和更大的网络并不总是能带来更好的性能。
Mamba 在设计时考虑了现代 GPU 硬件,解决了常见的计算效率低下问题,为机器学习架构效率设立了新标准。
vs Transformers

展望
Mamba 进入人工智能领域引起了人们对其潜在影响的热议和好奇。凭借其轻松处理长序列和设定高性能标准的能力,Mamba 似乎有望成为塑造复杂人工智能系统未来的关键角色。
因此,它有望在人工智能技术的进步中发挥重要作用。其效率和性能为开发更复杂的模型和应用程序奠定了基础,有可能创造下一代人工智能突破。 Mamba 架构可以作为下一代尖端人工智能模型的基础。它可以彻底改变各个领域:

总结
Mamba 的到来标志着一个新的篇章,有限的序列长度和低计算效率正在成为过去。它还打破了“拥有更多数据和更大模型意味着更智能模型”的神话。
多年来,我们见证了从 RNN 到 Transformer 以及现在的 Mamba 的转变。这些飞跃使人工智能更接近于能够像人类一样处理信息和思考。 Mamba 的线性时间缩放和选择性状态空间方法体现了推动人工智能领域向前发展的创新精神。
尽管仅测试了 Mamba 3B 和 1.4B,但这引发了一个问题:该模型是否会在更大的模型中表现类似。另外,您认为较小的LLM模式会成为现在的趋势吗?您认为 Mamba 架构会影响 AGI 的开发及其实现的时间框架吗?
Source: https://medium.com/@jelkhoury880/what-is-mamba-845987734ffc
本文由 mdnice 多平台发布