大家在训练完YOLOv5、v8模型时,输出的结果中会有如图1所示。
confusion matrix.png
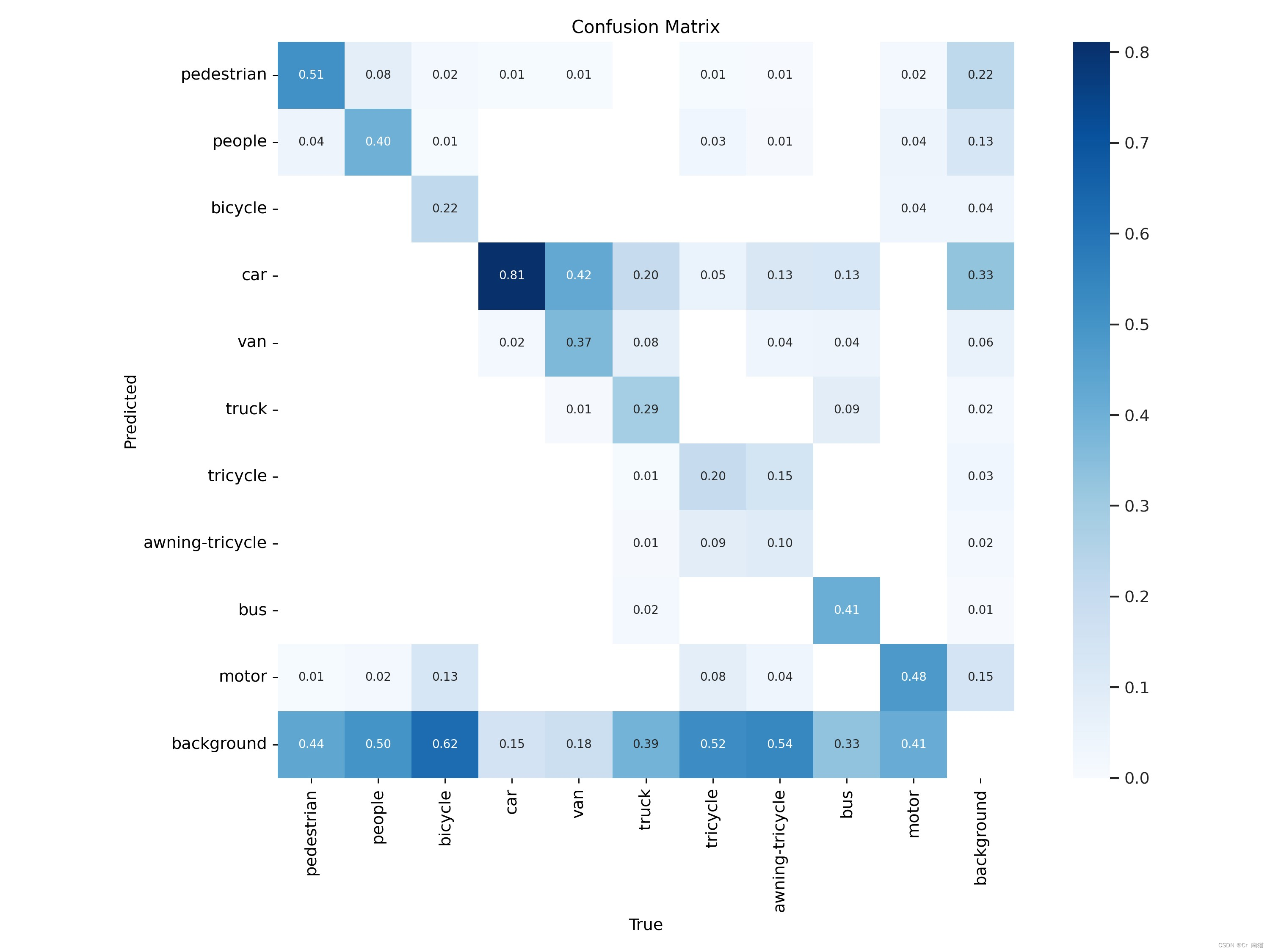
图1 训练结果中的混淆矩阵
那么这个图应该怎么看呢,请看下面的讲解。希望对你有帮助。
一、混淆矩阵
首先,先介绍一下什么是混淆矩阵。
混淆矩阵是一种将算法性能可视化的表现形式,矩阵的每一行代表一个真实的类别,每一列代表的是预测的类别。其实由上图就可以看出,横坐标是True,纵坐标是Precision。
(1)在矩阵中主对角线上的元素属于正确检测的样本数量(TP);
(2)左下三角区域属于模型漏检的样本数量,也称为假阴性(FN),表示模型未能正确检测到真实存在的样本,导致该目标未能被识别或错误分类成其他的类别;
(3)右上三角区域属于模型误检的样本数量,也称为假阳性(FP),表示模型将背景或其他类别分类成当前类别。
此外,当右上三角区域的数值较高时,就表明模型可能存在较多的误检,即模型将当前样本识别成背景或者其他目标;当左下三角区域的数值较高时,表明模型在这些类别上存在漏检问题,即模型没有正确检测到真实存在的目标。
由图中的每一格数字就能算出TP、FP、FN和TN,然后可以衍生出其他更多的评价指标,如P、R、F1等。
二、TP、FP与FN的回顾
目标检测中的混淆矩阵与分类非常相近,但是区别就在于分类任务是一张张图片,而检测任务是包含定位与分类两个任务,并且检测的对象是图像中目标类别。
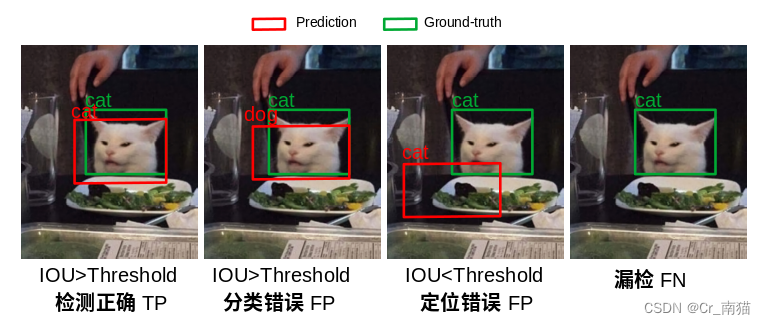
图2 类别的判别类型
目前最常用的判断一个检测结果是否正确的方式就是计算检测框与真实框的IOU,然后根据IOU去判别两个框是否匹配。以图2为例,红色的为模型预测的结果,绿色为真实标注框,两个框的IOU大于阈值,就被判定为匹配,同时两个框对应的类别也相同,那么此为正确的检测结果(TP)。
图2中的第二张图虽然IOU大于了阈值,但是由于类别不正确,所以被判定为误检(FP)。第三张图的检测框IOU小于阈值,没有与真实的标注框匹配,所以被判定为背景的误检。第四张图没有检测框,因此属于漏检(FN)。
三、目标检测中的混淆矩阵
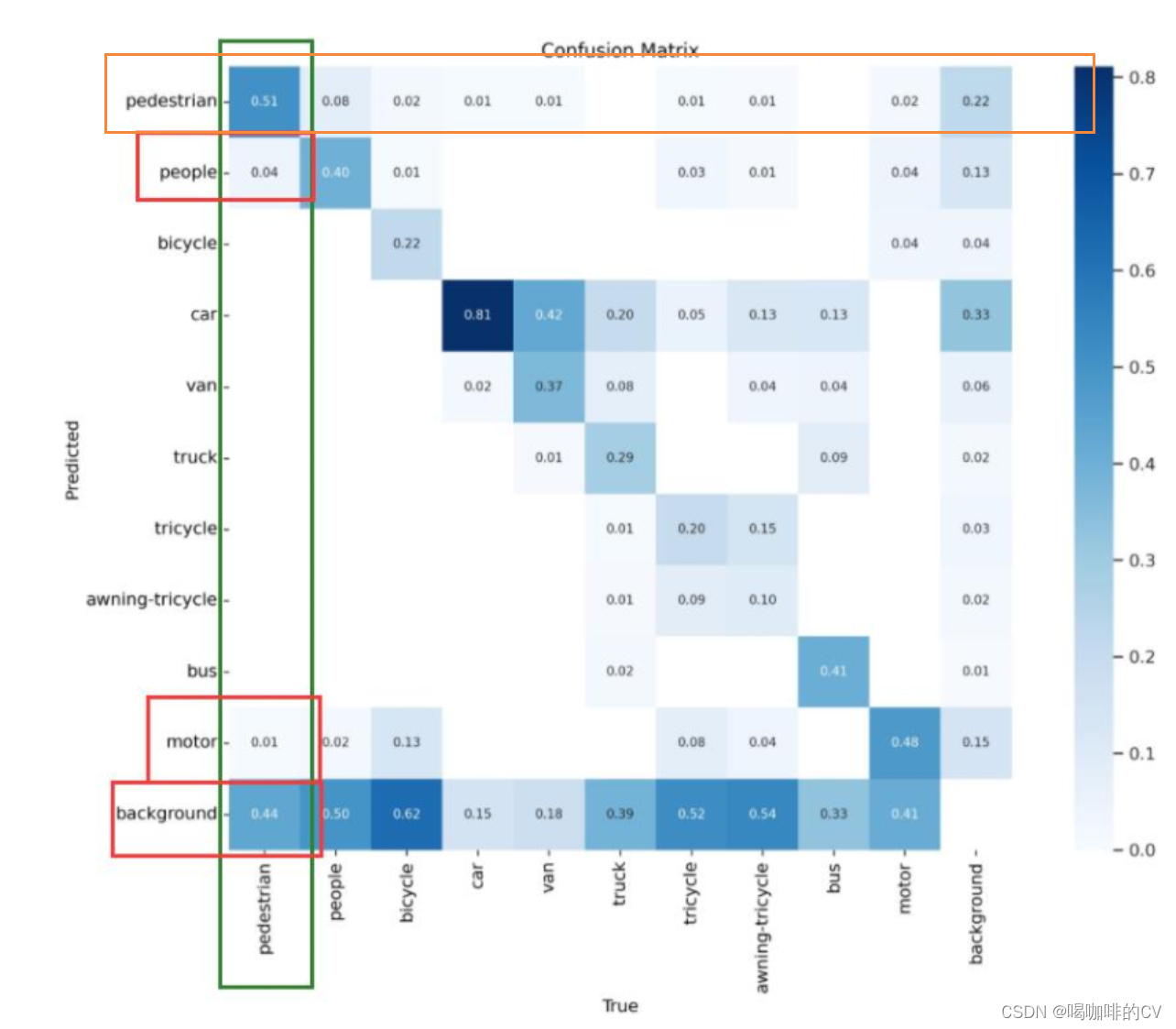
图3
以类别pedestrian为例。
在图3中,绿框(列)与红框(行)相交的格子为pedestrian预测成别的类别的概率(people0.04,motor0.01,background0.44),这类预测叫作假阴性(漏检/FN),错误地把当前目标匪类成其他类别。
而pedestrian类别正确预测(TP)的概率为0.51。
橙色框(第一行),从横坐标上看people0.08,bicycle0.02,car0.01,van0.01,tricycle0.01,motor0.02,background0.22。如people0.08,表示这类别true为people,但是predict成了pedestrian,就属于假阳性(误检/FP)。表示模型错误地将pedestrian类别分类为people类别。
更新时间:2024.4.8
如有其他错误,欢迎提出,共同进步!
-------------------------------今天不学习,明天变废物!------------------------------------