🔖墨香寄清辞:空谷幽篁风动,梦中仙鹤月明。 辗转千秋豪情在,乘风翱翔志不移。


目录
1. 编译原理之词法分析概念
1.1 编译原理
1.2 词法分析
2. 词法分析
2.1 实验目的
2.2 实验要求
2.3 实验理论依据
2.3.1 识别各种单词符号
2.3.2 超前搜索方法
2.3.3 预处理
2.3.4 参考代码
2.4 实验内容
2.4.1 解决代码
2.4.2 运行结果
2.5 功能扩展
2.5.1 第1处
2.5.2 第2-4处
2.5.3 第5处
2.5.4 第6-8处
2.5.5 第9-10处
2.5.6 第11处
2.6 实验心得
1. 编译原理之词法分析概念
1.1 编译原理
编译原理是计算机科学领域的一个重要分支,它研究如何将高级编程语言的源代码转化成计算机能够执行的机器代码或中间代码的过程。编译原理涵盖了编译器的设计和实现,其中编译器是一种将源代码翻译成目标代码的软件工具。编译器的主要任务包括语法分析、词法分析、语义分析、优化和代码生成等环节。
1.2 词法分析
词法分析是编译过程中的第一个阶段,其主要目标是将源代码分割成称为“词法单元”的基本单元,例如标识符、关键字、操作符、常量等。词法分析器(也称为词法扫描器)负责识别源代码中的这些词法单元,并将它们转化为一系列标记(tokens),通常以数据结构的形式存储,供后续阶段的语法分析器使用
🔥 资源获取:关注公众号【科创视野】回复 词法分析源码
🔥 相关博文:编译原理之LL(1)分析法:C/C++实现(附源码+详解!)
2. 词法分析
2.1 实验目的
(1)编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类;
(2)依次输出各个单词的内部编码及单词符号自身值。
2.2 实验要求
源程序为C语言,输入如下一段:
main(){int a=-5,b=4,j;if(a>=b)j=a-b;else j=b-a;}要求输出结果如下:
("main",1,1) ("(",5) (")",5)("{",5) ("int",1,2) ("a",2)("=",4) ("-5",3) (",",5)("b",2) ("=",4) ("4",3)(",",5) ("j",2) (";",5)("if",1,3) ("(",5) ("a",2)(">=",4) ("b",2) (")",5)("j",2) ("=",4) ("a",2)("-",4) ("b",2) (";",5)("else",1,4)("j",2) ("=",4)("b",2) ("-",4) ("a",2)(";",5) ("}",5)
2.3 实验理论依据
2.3.1 识别各种单词符号
1、 程序语言的单词符号一般分为五种:
(1) 关键字(保留字/ 基本字)if 、while 、begin…
(2) 标识符:常量名、变量名…
(3) 常数:34 、56.78 、true 、‘a’ 、…
(4) 运算符:+ 、- 、* 、/ 、〈 、and 、or 、….
(5) 界限符:, ; ( ) { } /*…
2、 识别单词:掌握单词的构成规则很重要
(1) 标识符的识别:字母| 下划线+( 字母/ 数字/ 下划线)
(2) 关键字的识别:与标识符相同,最后查表
(3) 常数的识别
(4) 界符和算符的识别
3、 大多数程序设计语言的单词符号都可以用转换图来识别,如下:

4、 词法分析器输出的单词符号常常表示为二元式:(单词种别,单词符号的属性值)
(1) 单词种别通常用整数编码,如1 代表关键字,2 代表标识符等
(2) 关键字可视其全体为一种,也可以一字一种。采用一字一种得分法实际处理起来较为方便。
(3) 标识符一般统归为一种
(4) 常数按类型(整、实、布尔等)分种
(5) 运算符可采用一符一种的方法。
(6) 界符一般一符一种的分法。
2.3.2 超前搜索方法
词法分析时,常常会用到超前搜索方法:
如当前待分析字符串为“a>+” ,当前字符为“>” ,此时,分析器倒底是将其分析为大于关系运算符还是大于等于关系运算符呢?
显然,只有知道下一个字符是什么才能下结论。于是分析器读入下一个字符’+’ ,这时可知应将’>’ 解释为大于运算符。但此时,超前读了一个字符’+’ ,所以要回退一个字符,词法分析器才能正常运行。又比如:‘+’ 分析为正号还是加法符号
2.3.3 预处理
预处理工作包括对空白符、跳格符、回车符和换行符等编辑性字符的处理,及删除注解等。由一个预处理子程序来完成。
词法分析器的设计
1、 设计方法:
(1) 写出该语言的词法规则。
(2) 把词法规则转换为相应的状态转换图。
(3) 把各转换图的初态连在一起,构成识别该语言的自动机
(4) 设计扫描器
2、 把扫描器作为语法分析的一个过程,当语法分析需要一个单词时,就调用扫描器。
扫描器从初态出发,当识别一个单词后便进入终态,送出二元式。
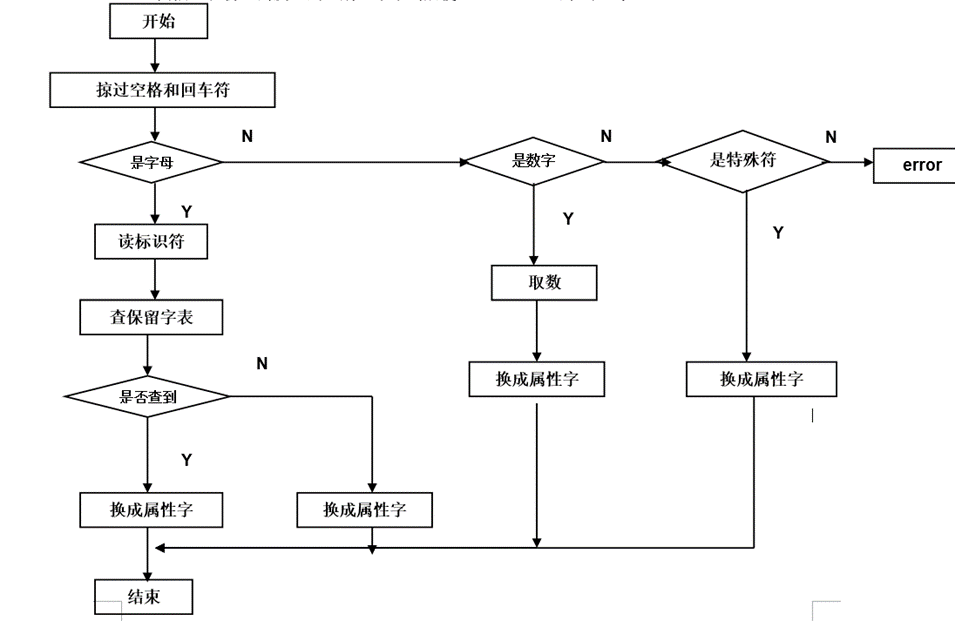
2.3.4 参考代码
参考代码(不完整):
void main(){ if ((fp=fopen("example.c", "r")) == NULL) /* 只读方式打开一个文件 */ printf("error"); else { cbuffer = fgetc(fp); /* fgetc( )函数:从磁盘文件读取一个字符 */ while (cbuffer != EOF) { if (cbuffer == ' ' || cbuffer == '\n') /* 掠过空格和回车符 */ cbuffer = fgetc(fp); else { if (isalpha(cbuffer)) cbuffer = alphaprocess(cbuffer); else if (isdigit(cbuffer)) cbuffer = digitprocess(cbuffer); else cbuffer = otherprocess(cbuffer); } } }}char alphaprocess(char buffer){ int atype; /* 保留字数组中的位置 */ int i = -1; char alphatp[20]; while (isalpha(buffer) || isdigit(buffer) || buffer == '_') { alphatp[++i] = buffer; } alphatp[i + 1] = '\0'; atype = search(alphatp, 1); /* 对此单词调用search函数判断类型 */ if (atype != 0) { printf("%s, (1,%d)\n", alphatp, atype - 1); id = 1; } else { printf("(%s, 2)\n", alphatp); id = 2; }}FILE *fp;char cbuffer;char *key[9] = { "main", "if", "else", "for", "while", "do", "return", "break", "continue" };int atype, id = 4;int search(char searchchar[], int wordtype) /* 判断单词是保留字还是标识符 */{ int i = 0; int p; switch (wordtype) { case 1: for (i = 0; i <= 7; i++) { if (strcmp(key[i], searchchar) == 0) { p = i + 1; break; } /* 是保留字则p为非0且不重复的整数 */ else { p = 0; } /* 不是保留字则用于返回的p=0 */ } return p; }}char digitprocess(char buffer){ int i = -1; char digittp[20]; while (isdigit(buffer)) { digittp[++i] = buffer; buffer = fgetc(fp); } digittp[i + 1] = '\0'; printf("(%s, 3)\n", digittp); id = 3; return buffer;}char otherprocess(char buffer){ char ch[20]; ch[0] = buffer; ch[1] = '\0'; if (ch[0] == ',' || ch[0] == ';' || ch[0] == '{' || ch[0] == '}' || ch[0] == '(' || ch[0] == ')') { printf("(%s, 5)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '*' || ch[0] == '/') { printf("(%s, 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '=' || ch[0] == '!' || ch[0] == '<' || ch[0] == '>') { buffer = fgetc(fp); if (buffer == '=') { ch[1] = buffer; ch[2] = '\0'; printf("(%s, 4)\n", ch); } else { printf("(%s, 4)\n", ch); id = 4; return buffer; } buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '+' || ch[0] == '-') { if (id == 4) /* 在当前符号以前是运算符,则此时为正负号 */ { buffer = fgetc(fp); ch[1] = buffer; ch[2] = '\0'; printf("(%s, 3)\n", ch); id = 3; buffer = fgetc(fp); return buffer; } ch[1] = '\0'; printf("(%s, 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; }}
2.4 实验内容
2.4.1 解决代码
首先在与实验解决代码的同一级目录下创建example.c文件,其内容如下;
main(){ int a=-5,b=4,j; if(a>=b) j=a-b; else j=b-a;}根据参考代码修改如下:
// 添加头文件#include <stdio.h>#include <stddef.h>#include <ctype.h>#include <string.h>// 变量声明FILE *fp;char cbuffer, cbuffer_next; // cbuffer_next记录下一字符const char *key[29] = {"main", "int", "if", "else", "for", "while", "do", "return", "break", "continue", "float", "double", "char", "void", "long", "short", "switch", "case", "default", "goto", "auto", "static", "register", "extern", "struct", "union", "enum", "typedef", "sizeof"}; // 1.加入其他关键字int atype, id = 4;const char *space_word_table[11] = {",", ";", "(", ")", "[", "]", "{", "}", ".", "\"", "#"}; // 2.加入界限符const char *maths_calcu_table[12] = {"+", "-", "*", "/", "++", "--", "+=", "-=", "*=", "/=", "<<", ">>"}; // 3.加入运算符const char *relation_calcu_table[7] = {"<", "<=", ">", ">=", "=", "<>", "=="}; // 4.加入关系符// 函数声明char alphaprocess(char buffer);int search(char searchchar[], int wordtype);char digitprocess(char buffer);char otherprocess(char buffer);int isKeyWord(char *buffer);char operatorProcess(char buffer);bool isOperator(char buffer);char calcuProcess(char buffer);bool isCalcu(char buffer);// void 改intint main(){ // fopen函数需要加入#include<stdio.h> if ((fp = fopen("example.c", "r")) == NULL) printf("error"); // NULL宏没有被声明 else { cbuffer = fgetc(fp); // 从指定的文件流中读取一个字符 while (cbuffer != EOF) { if (cbuffer == ' ' || cbuffer == '\n' || cbuffer == '\t') // 5.忽略空格、制表符(新加)和换行符 cbuffer = fgetc(fp); else if (isalpha(cbuffer)) // 处理标识符和关键字 cbuffer = alphaprocess(cbuffer); else if (isdigit(cbuffer)) // 处理常数 cbuffer = digitprocess(cbuffer); else if (isOperator(cbuffer)) // 处理关系运算符 cbuffer = operatorProcess(cbuffer); else if (isCalcu(cbuffer)) // 处理算术运算符 cbuffer = calcuProcess(cbuffer); else // 处理分隔符和其他符号 cbuffer = otherprocess(cbuffer); } } fclose(fp); // return 0;}// 判断关键字,是返回1和i(i是key位置,从1开始),否则标识符则返回2char alphaprocess(char buffer){ int atype; /*保留字数组中的位置*/ int i = -1; char alphatp[20]; while (isalpha(buffer) || isdigit(buffer) || buffer == '_') // 如果buffer是字母数字or下划线,则放入 alphatp字符数组 { alphatp[++i] = buffer; buffer = fgetc(fp); // 从指定的文件流中读取一个字符 } alphatp[i + 1] = '\0'; // alphatp字符数组结尾加空字符,确保单词在被正确识别。 atype = search(alphatp, 1); /*对此单词调用search函数判断类型*/ if (atype != 0) { printf("(\"%s\", 1, %d)\n", alphatp, atype); id = 1; } else { printf("(\"%s\", 2)\n", alphatp); id = 2; } return buffer; // 返回buffer值}// 该函数的返回值为整型变量p,用于表示判断结果。// 关键字顺序key返回1,2,3...,否则返回0int search(char searchchar[], int wordtype){ int i = 0; int p; switch (wordtype) { case 1: for (i = 0; i <= 28; i++) { if (strcmp(key[i], searchchar) == 0) { p = i + 1; break; } else p = 0; } return (p); }}// 输出数字类,3char digitprocess(char buffer){ int i = -1, flag = 0; char digittp[20]; if (buffer == '+' || buffer == '-') { // 6.判断正负数 digittp[++i] = buffer; buffer = fgetc(fp); } while (isdigit(buffer) || buffer == '.' || buffer == 'e' || buffer == 'E' || buffer == '+' || buffer == '-') { // 7. 科学计数法 if (buffer == '.' || buffer == 'e' || buffer == 'E) { // 8.浮点数 flag = 1; digittp[++i] = buffer; } else if (buffer == '+' || buffer == '-') { if (flag == 1) { digittp[++i] = buffer; } } else { digittp[++i] = buffer; } buffer = fgetc(fp); } digittp[i + 1] = '\0'; if (flag == 1) { printf("(\"%s\", 3)\n", digittp); id = 3; } else { printf("(\"%s\", 3)\n", digittp); id = 3; } return buffer;}// 输出标识符char otherprocess(char buffer){ char ch[20]; ch[0] = buffer; ch[1] = '\0'; // 9.限界符加入[],:,# if (ch[0] == ',' || ch[0] == ';' || ch[0] == '{' || ch[0] == '}' || ch[0] == '(' || ch[0] == ')' || ch[0] == '[' || ch[0] == ']' || ch[0] == '#' || ch[0] == ':') { printf("(\"%s\", 5)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } // 10.加入取余+%|^& ch[0]=='+'||ch[0]=='-'|| if (ch[0] == '*' || ch[0] == '/' || ch[0] == '%' || ch[0] == '|' || ch[0] == '&' || ch[0] == '~' || ch[0] == '^) { printf("(\"%s\", 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '=' || ch[0] == '!' || ch[0] == '<' || ch[0] == '>') { buffer = fgetc(fp); if (buffer == '=') // 小于等于,大于等于 { ch[1] = buffer; ch[2] = '\0'; printf("(\"%s\", 4)\n", ch); } else { printf("(\"%s\", 4)\n", ch); id = 4; return buffer; } buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '+' || ch[0] == '-') { if (id == 4) /*在当前符号以前是运算符,则此时为正负号*/ { buffer = fgetc(fp); ch[1] = buffer; ch[2] = '\0'; printf("(\"%s\", 3)\n", ch); id = 3; buffer = fgetc(fp); return buffer; } ch[1] = '\0'; printf("(\"%s\", 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; }} // 增加"}"char operatorProcess(char buffer){ char operate[10]; for (int i = 0; i < 10; i++) { operate[i] = '\0'; } int j = 0; while ((isOperator(buffer))) { //假如后面都是关系运算符,则一直加入,直到后面不是关系运算符为止 operate[j] = buffer; j++; buffer = fgetc(fp); } //检查该操作符是否在预设的符号之中 for (int i = 0; i < 7; i++) { if (strcmp(operate, relation_calcu_table[i]) == 0) { printf("(\"%s\" ,关系运算符)\n", operate); //如果是关系符,就输出 return buffer; } } return buffer;}bool isOperator(char buffer){ return buffer == '>' || buffer == '<' || buffer == '=';}bool isCalcu(char buffer){ return buffer == '+' || buffer == '-' || buffer == '*' || buffer == '/' || buffer == '=';}char calcuProcess(char buffer){ //用来处理算术运算符 char calcu[5]; //首先清除数组的内容 for (int i = 0; i < 5; i++) { calcu[i] = '\0'; } int i = 0; while ((isCalcu(buffer))) { //假如后面都是算术运算符,则一直加入,直到后面不是算术运算符为止 calcu[i] = buffer; i++; buffer = fgetc(fp); } // 11.检查是否是注释 int flag = true; for (int i = 0; i < 2; i++) { //如果calcu的前两位都是 //,说明从buffer开头的字符到最近的一个换行符内,都是注释 if (calcu[i] != '/') { flag = false; } } if (flag) { //说明是注释 char note[50]; //支持的最长长度为50 for (int i = 0; i < 50; i++) { //首先将note数组全部置为'\0' note[i] = '\0'; } int i = 0; while (buffer != '\n') { note[i] = buffer; i++; buffer = fgetc(fp); } printf("(\"%s\",注释) \n", note); return buffer; } //检查该操作符是否在预设的符号之中 for (int i = 0; i < 10; i++) { if (strcmp(calcu, maths_calcu_table[i]) == 0) { printf("(\"%s\" ,算术运算符)\n", calcu); //如果是算术符,就输出 return buffer; } } return buffer;}2.4.2 运行结果
导入实验指定的内容运行结果为:
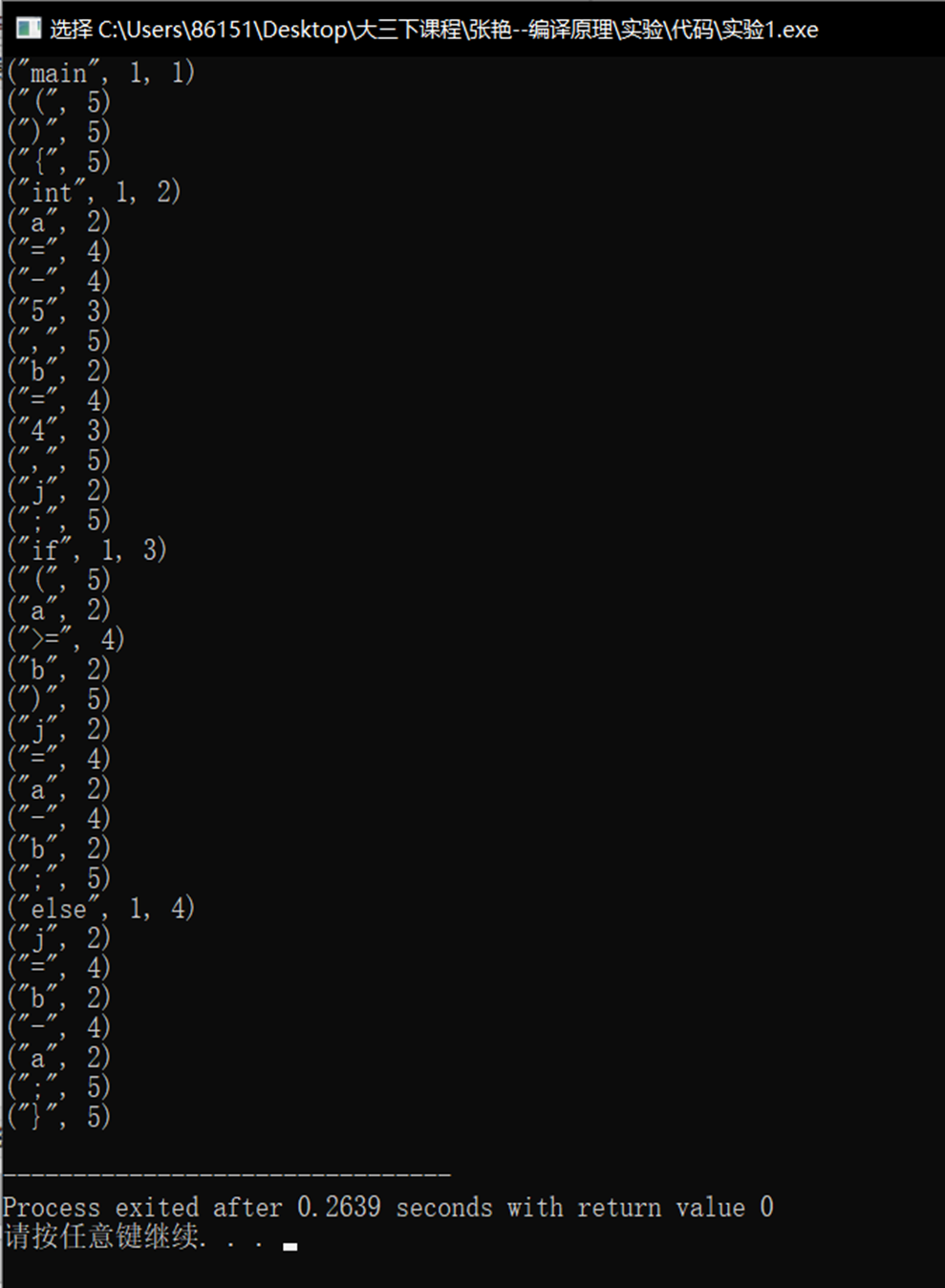
2.5 功能扩展
在这次实验代码中,我新增加了11处地方,以便完善词法分析的功能。这些新增内容涵盖了所有的保留字、运算符和分隔符。首先,在头文件语句中,我对单词进行了详细的分析,以确保正确识别它们。此外,对包含scanf和printf语句的代码段进行了改进,使其能够准确地分析各类单词。
在处理常数方面,我考虑了小数、科学计数法和正负多位数的情况。这样,词法分析器就能够正确地识别这些常数,并将它们归类为数字类型。另外,我对指针及其运算符进行了处理。这意味着词法分析器能够正确地识别指针类型,并对与之相关的运算符进行适当的分类。此外,我引入了结构体和共用体的识别。这样词法分析器就能够准确地将它们识别为特定的数据类型,并将其与其他关键字区分开。
除了以上新增内容外,我还对其他部分进行了相应的补充与改进,如在原有的代码中,只有文件的打开操作,并未包含关闭文件的步骤。为了确保代码的完整性和安全性,我添加了fclose(fp)语句,用以关闭已打开的文件;引入正确的库以确保函数调用成功;设置正确的变量类型确保后续操作的进行等等。
对于小数、科学计数法以及其他运算符设计输入为:
main(){ int a = -5, b = 4, j; if (a >= b) j = a - b; else j = b - a; a++; b--; a = 1e+500; b = 1.50; struct a { int a; float b; double c; string d; };}上述测试程序的运行结果为:
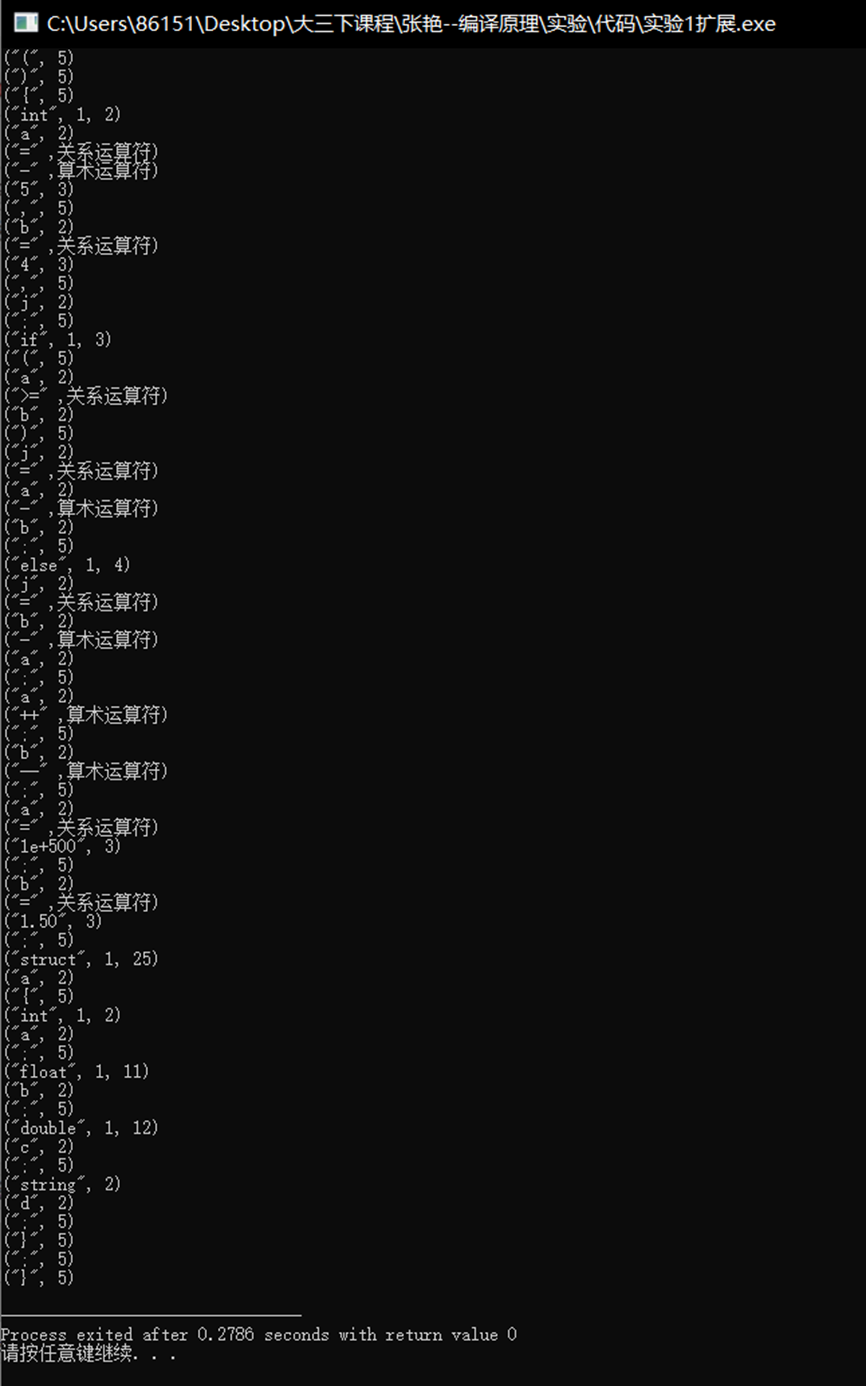
代码的总体分析:
代码实现了一个简单的词法分析器,用于对C语言代码进行词法分析。词法分析是编译过程中的第一个阶段,用于将源代码分解成一个个的词法单元,例如标识符、关键字、运算符和界定符等。
1.在主函数main()中,首先打开名为example2.c的文件,并进行判断,如果文件打开失败,输出错误信息;否则,开始进行词法分析。
2.接下来,通过循环读取文件中的字符,直到遇到文件结尾(EOF)。在循环中,按照以下规则对字符进行处理:
3.如果字符是空格、制表符(\t)或换行符(\n),则忽略该字符,继续读取下一个字符。
4.如果字符是字母,调用alphaprocess函数处理标识符和关键字。
5.如果字符是数字,调用digitprocess函数处理常数。
6.如果字符是关系运算符(如 <, <=, >, >=, =, <>, ==),调用operatorProcess函数处理关系运算符。
7.如果字符是算术运算符(如 +, -, *, /, +=, -=, *=, /=, <<, >>),调用calcuProcess函数处理算术运算符。
8.如果字符是分隔符或其他符号(如 ,, ;, (, ), [, ], {, }, ., ", #),调用otherprocess函数处理。这些处理函数会根据字符的类型输出相应的词法单元,并返回下一个字符用于继续词法分析。
9.在处理标识符和关键字时,alphaprocess函数将连续的字母、数字和下划线组成的字符串放入字符数组alphatp中,并调用search函数判断该字符串的类型(关键字或标识符)。如果是关键字,则输出对应的关键字和类型;如果是标识符,则只输出标识符。然后返回下一个字符继续词法分析。
10.在处理常数时,digitprocess函数根据常数的规则将连续的数字、小数点、指数符号(e或E)和正负号组成的字符串放入字符数组digittp中。根据是否包含小数点,输出不同类型的常数。然后返回下一个字符继续词法分析。
11.1在处理关系运算符时,operatorProcess函数会检查连续的字符是否是关系运算符,并输出相应的词法单元。
12.在处理算术运算符时,calcuProcess函数会检查连续的字符是否是算术运算符,并输出相应的词法单元。在处理算术运算符之前,还会检查是否是注释(以//开头的注释),如果是注释,则将注释内容读取并输出注释的词法单元。
13.在处理分隔符和其他符号时,otherprocess函数会根据字符的类型输出相应的词法单元。
14.在循环结束后,关闭文件,并输出词法分析结束的提示信息。
以下是对新增内容的详细说明:
2.5.1 第1处
*key[29]={"main","int","if","else","for","while","do","return","break","continue","float","double","char","void","long","short","switch","case","default","goto","auto","static","register","extern","struct","union","enum","typedef","sizeof"}; //1.加入其他关键字这里较为简单,通过定义了一个字符串数组 key,长度为 29。数组中存储了一些关键字,用于词法分析程序中判断标识符是否为关键字,包括
"main", "int", "if", "else", "for", "while", "do", "return", "break", "continue", "float", "double", "char", "void", "long", "short", "switch", "case", "default", "goto", "auto", "static", "register", "extern", "struct", "union", "enum", "typedef", "sizeof"
通过定义该字符串数组,词法分析程序可以在处理标识符时,将其与这些关键字进行比较,以确定标识符是否为关键字。如果标识符与数组中的任何一个关键字匹配,那么该标识符将被识别为关键字,否则将被视为普通的标识符。
2.5.2 第2-4处
const char* space_word_table[11] = { ",",";","(",")","[","]","{","}",".","\"","#"}; //2.加入界限符const char* maths_calcu_table[12] = { "+","-","*","/","++","--","+=","-=","*=","/=","<<",">>"}; //3.加入运算符const char* relation_calcu_table[7] = {"<","<=",">",">=","=","<>","=="}; //4.加入关系符这里定义了三个字符指针数组 space_word_table、maths_calcu_table 和 relation_calcu_table,分别用于存储不同类型的符号。
space_word_table 存储了一些界限符,用于词法分析程序中识别和处理源代码中的界限符。这些界限符包括
",", ";", "(", ")", "[", "]", "{", "}", ".", "\"" 和 "#"
maths_calcu_table 存储了一些算术运算符,用于词法分析程序中识别和处理源代码中的算术运算符。这些算术运算符包括
"+", "-", "*", "/", "++", "--", "+=", "-=", "*=", "/=", "<<" 和 ">>"
relation_calcu_table 存储了一些关系运算符,用于词法分析程序中识别和处理源代码中的关系运算符。这些关系运算符包括
"<", "<=", ">", ">=", "=", "<>" 和 "=="
通过定义这些字符指针数组,词法分析程序可以根据需要将源代码中的符号进行分类处理,以便后续的语法分析和语义分析阶段可以正确解析和处理代码。
2.5.3 第5处
int main(){ // fopen函数需要加入#include<stdio.h> if ((fp = fopen("example2.c", "r")) == NULL) printf("error"); // NULL宏没有被声明 else { cbuffer = fgetc(fp); // 从指定的文件流中读取一个字符 while (cbuffer != EOF) { if (cbuffer == ' ' || cbuffer == '\n' || cbuffer == '\t') // 5.忽略空格、制表符(新加)和换行符 cbuffer = fgetc(fp); else if (isalpha(cbuffer)) // 处理标识符和关键字 cbuffer = alphaprocess(cbuffer); else if (isdigit(cbuffer)) // 处理常数 cbuffer = digitprocess(cbuffer); else if (isOperator(cbuffer)) // 处理关系运算符 cbuffer = operatorProcess(cbuffer); else if (isCalcu(cbuffer)) // 处理算术运算符 cbuffer = calcuProcess(cbuffer); else // 处理分隔符和其他符号 cbuffer = otherprocess(cbuffer); } } fclose(fp); // return 0;}#include<stdio.h>:这行代码是一个预处理指令,用于包含 <stdio.h> 头文,该头文件中定义了输入输出函数,如 fopen 和 printf。
int main():这是程序的入口函数,程序从这里开始执行。int 表示函数返回值的类型为整数,main 是函数名,括号内为空,表示没有参数传递给 main 函数。
if ((fp=fopen("example2.c","r"))==NULL):这是一个条件语句,用于判断是否成功打开文件 "example2.c"。fopen 函数用于打开文件,"r" 表示以只读方式打开文件。fp 是文件指针,== NULL 则表示打开文件失败,即文件指针为空。
printf("error");:如果打开文件失败,将输出字符串 "error"。
else:如果打开文件成功,则执行 else 代码块中的内容。
cbuffer = fgetc(fp);:从打开的文件流中读取一个字符,并将其赋值给变量 cbuffer。
while (cbuffer!=EOF):循环执行以下代码块,直到读取到文件流的结尾(End of File,EOF)。
if (cbuffer==' '||cbuffer=='\n'||cbuffer== '\t'):判断读取到的字符是否为空格、换行符或制表符,如果是,则继续读取下一个字符。
else if (isalpha(cbuffer)):如果读取到的字符是字母,调用 alphaprocess 函数对标识符和关键字进行处理。
else if (isdigit(cbuffer)):如果读取到的字符是数字,调用 digitprocess 函数对常数进行处理。
else if (isOperator(cbuffer)):如果读取到的字符是关系运算符,调用 operatorProcess 函数进行处理。
else if (isCalcu(cbuffer)):如果读取到的字符是算术运算符,调用 calcuProcess 函数进行处理。
else:如果读取到的字符是分隔符或其他符号,则调用 otherprocess 函数进行处理。
fclose(fp);:关闭打开的文件流。
return 0;:程序执行完毕,返回整数值 0,表示程序正常结束。
该代码的主要功能是打开文件 "example2.c",逐个读取文件中的字符,并根据字符的类型进行不同的处理,包括处理空格、制表符、换行符,处理标识符和关键字,处理常数,处理关系运算符,处理算术运算符,处理分隔符和其他符号。这是一个简化的词法分析器的基本框架,用于对源代码进行词法分析,将不同类型的字符进行分类和处理。具体的处理方式需要根据函数 alphaprocess、digitprocess、operatorProcess、calcuProcess 和 otherprocess 的实现来确定,这些函数可能包含了对标识符、关键字、常数、运算符和其他符号的解析和处理逻辑。
2.5.4 第6-8处
char digitprocess(char buffer){ int i = -1, flag = 0; char digittp[20]; if (buffer == '+' || buffer == '-') { // 6.判断正负数 digittp[++i] = buffer; buffer = fgetc(fp); } while (isdigit(buffer) || buffer == '.' || buffer == 'e' || buffer == 'E' || buffer == '+' || buffer == '-') { // 7. 科学计数法 if (buffer == '.' || buffer == 'e' || buffer == 'E') { // 8.浮点数 flag = 1; digittp[++i] = buffer; } else if (buffer == '+' || buffer == '-') { if (flag == 1) { digittp[++i] = buffer; } } else { digittp[++i] = buffer; } buffer = fgetc(fp); } digittp[i + 1] = '\0'; if (flag == 1) { printf("(\"%s\", 3)\n", digittp); id = 3; } else { printf("(\"%s\", 3)\n", digittp); id = 3; } return buffer;}上述代码实现了对数字类的处理逻辑,用于识别和输出数字类型的词法单元。以下是对代码的解释:
1.首先,定义了一个名为 digitprocess 的函数,它的参数是一个字符 buffer,表示当前要处理的字符。
2.在函数内部,声明了一些变量用于辅助处理,包括整型变量 i(用于索引 digittp 数组)、整型变量 flag(用于标识是否为浮点数)、字符数组 digittp(用于存储识别到的数字)。
3.如果当前字符是加号或减号(即判断正负数),将该字符存入 digittp 数组,并读取下一个字符。
4.进入循环,判断当前字符是否是数字、小数点、科学计数法中的 e 或 E、加号或减号。
5.如果是小数点、科学计数法中的 e 或 E,则将 flag 设置为 1,表示识别到浮点数,并将该字符存入 digittp 数组。
6.如果是加号或减号,需要判断是否在浮点数中出现。如果 flag 为 1,表示在浮点数中,将该字符存入 digittp 数组。
7.如果是数字,将该字符存入 digittp 数组。
8.读取下一个字符,继续循环,直到遇到不再属于数字类的字符。
9.将 digittp 数组的最后一个元素设为字符串结束符 \0。
10.根据 flag 的值判断识别到的数字是整数还是浮点数。如果 flag 为 1,表示识别到浮点数,使用 printf 函数输出识别结果,格式为 ("数字", 3),其中数字是识别到的数字字符串,3 表示数字类型的标识符。如果 flag 不为 1,表示识别到整数,同样输出识别结果。
11.将全局变量 id 的值设为 3,表示当前词法单元为数字类型。
12.返回读取到的下一个字符,以便继续词法分析。
通过检测数字类的特征,包括整数、浮点数、正负数、科学计数法等,将识别到的数字存储起来,并输出对应的词法单元类型和字符串值。
2.5.5 第9-10处
char otherprocess(char buffer){ char ch[20]; ch[0] = buffer; ch[1] = '\0'; // 9. 限界符加入[],:,# if (ch[0] == ',' || ch[0] == ';' || ch[0] == '{' || ch[0] == '}' || ch[0] == '(' || ch[0] == ')' || ch[0] == '[' || ch[0] == ']' || ch[0] == '#' || ch[0] == ':') { printf("(\"%s\", 5)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } // 10. 加入取余+-%|^& ch[0]=='+'||ch[0]=='-'|| if (ch[0] == '*' || ch[0] == '/' || ch[0] == '%' || ch[0] == '|' || ch[0] == '&' || ch[0] == '~' || ch[0] == '^') { printf("(\"%s\", 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '=' || ch[0] == '!' || ch[0] == '<' || ch[0] == '>') { buffer = fgetc(fp); if (buffer == '=') // 小于等于,大于等于 { ch[1] = buffer; ch[2] = '\0'; printf("(\"%s\", 4)\n", ch); } else { printf("(\"%s\", 4)\n", ch); id = 4; return buffer; } buffer = fgetc(fp); id = 4; return buffer; } if (ch[0] == '+' || ch[0] == '-') { if (id == 4) /*在当前符号以前是运算符,则此时为正负号*/ { buffer = fgetc(fp); ch[1] = buffer; ch[2] = '\0'; printf("(\"%s\", 3)\n", ch); id = 3; buffer = fgetc(fp); return buffer; } ch[1] = '\0'; printf("(\"%s\", 4)\n", ch); buffer = fgetc(fp); id = 4; return buffer; }}该代码实现了对标识符的处理逻辑,用于识别和输出标识符类型的词法单元。
1.首先,定义了一个名为 otherprocess 的函数,它的参数是一个字符 buffer,表示当前要处理的字符。
2.在函数内部,声明了一个字符数组 ch,用于存储识别到的标识符。将当前字符存入 ch 数组的第一个位置,并在第二个位置设置字符串结束符 \0。检查当前字符是否属于限界符(界定符),包括逗号、分号、大括号、圆括号、方括号、井号和冒号。
3.如果是限界符,使用 printf 函数输出识别结果,格式为 ("标识符", 5),其中标识符是识别到的限界符字符串,5 表示标识符类型的标识符。然后读取下一个字符,将全局变量 id 的值设为 4(表示当前词法单元为标识符类型),并返回读取到的下一个字符。
4.检查当前字符是否属于取余运算符、加减乘除运算符、位运算符等。
5.如果是运算符,同样使用 printf 函数输出识别结果,格式为 ("标识符", 4),然后读取下一个字符,将全局变量 id 的值设为 4,并返回读取到的下一个字符。
6.检查当前字符是否属于关系运算符,包括等于、不等于、小于、大于等。
7.如果是关系运算符,读取下一个字符,并检查是否与当前字符形成双字符的关系运算符(如小于等于、大于等于)。
8.如果是双字符的关系运算符,则使用 printf 函数输出识别结果,格式为 ("标识符", 4)。
9.如果不是双字符的关系运算符,则使用 printf 函数输出识别结果,格式为 ("标识符", 4),将全局变量 id 的值设为 4,并返回读取到的下一个字符。
10.检查当前字符是否属于正号或负号。
11.如果前一个词法单元是运算符,则当前字符是正负号,将读取到的下一个字符存入 ch 数组的第二个位置,并使用 printf 函数输出识别结果,格式为 ("标识符", 3),其中标识符是识别到的正负号字符串,3 表示标识符类型的标识符。
12.如果前一个词法单元不是运算符,则当前字符是运算符,将 ch 数组的第二个位置设为字符串结束符 \0,使用 printf 函数输出识别结果。
2.5.6 第11处
char calcuProcess(char buffer){ // 用来处理算术运算符 char calcu[5]; // 首先清除数组的内容 for (int i = 0; i < 5; i++) { calcu[i] = '\0'; } int i = 0; while (isCalcu(buffer)) { // 假如后面都是算术运算符,则一直加入,直到后面不是算术运算符为止 calcu[i] = buffer; i++; buffer = fgetc(fp); } // 11. 检查是否是注释 int flag = 1; for (int i = 0; i < 2; i++) { // 如果calcu的前两位都是//,说明从buffer开头的字符到最近的一个换行符内,都是注释 if (calcu[i] != '/') { flag = 0; } } if (flag) { // 说明是注释 char note[50]; // 支持的最长长度为50 for (int i = 0; i < 50; i++) { // 首先将note数组全部置为'\0' note[i] = '\0'; } int i = 0; while (buffer != '\n') { note[i] = buffer; i++; buffer = fgetc(fp); } printf("(\"%s\",注释) \n", note); return buffer; } // 检查该操作符是否在预设的符号之中 for (int i = 0; i < 10; i++) { if (strcmp(calcu, maths_calcu_table[i]) == 0) { printf("(\"%s\" ,算术运算符)\n", calcu); // 如果是算术符,就输出 return buffer; } } return buffer;}该代码实现了对算术运算符的处理逻辑,具体解释如下:
1.我定义了一个名为 calcuProcess 的函数,它的参数是一个字符 buffer,表示当前要处理的字符。在函数内部,声明了一个字符数组 calcu,用于存储识别到的算术运算符。使用 for 循环将 calcu 数组的内容清空,将数组的每个元素都设置为字符串结束符 \0。声明了一个整型变量 i,用于记录当前要存入 calcu 数组的位置。
2.通过while 循环,条件是当前字符是算术运算符(使用 isCalcu 函数进行判断)。在循环内部,将当前字符存入 calcu 数组的第 i 个位置,并将 i 自增。读取下一个字符并赋值给 buffer。循环结束后,会得到一个识别到的算术运算符存储在 calcu 数组中。
3.接下来,进行注释检查的逻辑。声明一个整型变量 flag 并初始化为 true,用于标识是否是注释。进入一个 for 循环,遍历 calcu 数组的前两个元素。如果 calcu 数组的前两个元素不是 '/',则将 flag 设置为 false,表示不是注释。如果 flag 为 true,说明 calcu 的前两个元素都是 '/',即可能是注释。声明一个字符数组 note,用于存储注释内容。
4.使用 for 循环将 note 数组的内容清空,将数组的每个元素都设置为字符串结束符 \0。声明一个整型变量 i,用于记录当前要存入 note 数组的位置。
5.进入一个 while 循环,条件是当前字符不是换行符 '\n'。在循环内部,将当前字符存入 note 数组的第 i 个位置,并将 i 自增。读取下一个字符并赋值给 buffer。循环结束后,会得到一个识别到的注释内容存储在 note 数组中。使用 printf 函数输出注释的识别结果,格式为 ("注释内容", 注释),其中注释内容是 note 数组的值。
6.返回读取到的下一个字符。如果不是注释,继续执行后续逻辑。
7.使用 for 循环遍历预设的符号表 maths_calcu_table。在循环内部,使用 strcmp 函数比较 calcu如果找到了匹配的算术运算符,即 strcmp(calcu, maths_calcu_table[i]) 的返回值为0,表示 calcu 与预设的符号表中的某个算术运算符相匹配。使用 printf 函数输出识别结果,格式为 ("算术运算符", calcu),其中算术运算符是 calcu 数组的值。返回读取到的下一个字符。如果没有找到匹配的算术运算符,则执行默认的返回语句,返回读取到的下一个字符。
2.6 实验心得
通过这次实验,我深入了解了词法分析的过程和原理,并体会到了其在编译过程中的重要性和作用。在这个过程中,我遇到了一些困难,但也获得了宝贵的经验和收获。
首先,词法分析是编译过程中的第一个阶段,负责将源代码转换为一个个的单词或符号,作为后续语法分析的输入。通过对C语言的词法分析实验,我学会了如何识别关键字、标识符、常数、运算符和界限符等不同类型的单词,并将其分类和输出相应的词法单元。
其次,我在实验中学到了如何设计和实现词法分析器的基本框架和算法,并且了解了正则表达式的基本规则和常用操作符,以及如何使用正则表达式定义词法规则,从而构建词法分析器。
在实验过程中,我遇到了困难包括:理解和分析编程语言的词法规则。不同的编程语言有不同的规则和约定,需要仔细研究和理解语言的规范文档才能正确地进行词法分析;其次是处理边界情况和错误处理。在实际的代码中,可能会出现不规范或错误的输入,如拼写错误、缺少分号等,需要在词法分析器中进行适当的错误处理,保证词法分析的准确性和健壮性。
这次实验不仅使我掌握了词法分析的基本原理和方法,还提高了自己的编程能力和逻辑思维能力,在编写词法分析器需要对源代码进行逐个字符的分析和处理,需要仔细观察和检查每个字符的类型和状态,这使得我在编写代码的过程中保持细心和耐心,避免出现疏漏和错误。