一、赛题说明
数据格式
本次大赛数据集包含数千份高危患者的低剂量肺部CT影像(mhd格式)数据,每个影像包含一系列胸腔的多个轴向切片。每个影像包含的切片数量会随着扫描机器、扫描层厚和患者的不同而有差异。原始图像为三维图像。这个三维图像由不同数量的二维图像组成。其二维图像数量可以基于不同因素变化,比如扫描机器、患者。Mhd文件具有包含关于患者ID的必要信息的头部,以及诸如切片厚度的扫描参数。
数据由大赛合作医院授权提供,全部是肺部CT影像(mhd格式)数据。主办方为医院开发了专业的脱敏软件,所有CT影像数据严格按照国际通行的医疗信息脱敏标准,由医院进行脱敏处理,脱敏信息包括:医院信息、患者信息和标注医师信息,所有数据不可溯,切实保障数据安全。
训练集和验证集的所有数据全部都有结节,除了进行病理分析的结节外,其它结节都由三位医生进行标记确认。csv文件标注了结节的位置和大小,具体示例如下:
------------------------------------------------
Seriesuid,coordX,cordY,coordZ,diameter_mm
LKDS_00001,-100.56,67.26,-231.81,6.44
------------------------------------------------
参赛者提交一个CSV文件,第一行标记每一列的名称,一共五列,分别为图像ID号,坐标和概率。从第二行之后的每一行都标记一个检测到的结节,坐标为检测到的结节的中心坐标x, y, z的数值。例如:
------------------------------------------------
seriesuid,coordX,coordY,coordZ,probability
LKDS-00012,75.5,56.0,-194.254518072,6.5243e-05
LKDS-00022,-35.5999634723,78.000078755,-13.3814265714,0.00269234
LKDS-00049,80.2837837838,198.881575673,-572.700012,0.00186072
LKDS-00056,-98.8499883785,33.6429184312,-99.7736607907,0.00035473
LKDS-00057,98.0667072477,-46.4666486536,-141.421980179,0.000256219
------------------------------------------------
字段定义:
------------------------------------------------
列名 类型 含义
seriesuid string 患者ID
coordX float X方向位置
coordY float Y方向位置
coordZ float Z方向位置
diameter_mm float 结节大小
probability float 预测为结节的概率
------------------------------------------------
二、赛题解读
这是一个目标检测(object detection)的问题,在3D的CT图像中找到结节的位置。
目前在目标检测做的最好的是Kaiming He团队提出的RCNN系列结构(2D)。我们进行了code编写,但是效果不理想。主要的原因在于:
1. Faster RCNN开销特别大,导致我们只能实现2D版本的,但2D版本丢失了3D的context信息,导致我们的模型得出的结果并不好。
2. 如果切换到3D版本,Faster RCNN由于需要先提proposal,再做detection,时间开销巨大。
放弃Faster RCNN之后,我们参考了以直接预测著称的SSD、YOLO系列,最后决定采用3D版本的YOLO。做出来以后,效果得到了飞速提升。
三、数据预处理—肺部区域提取
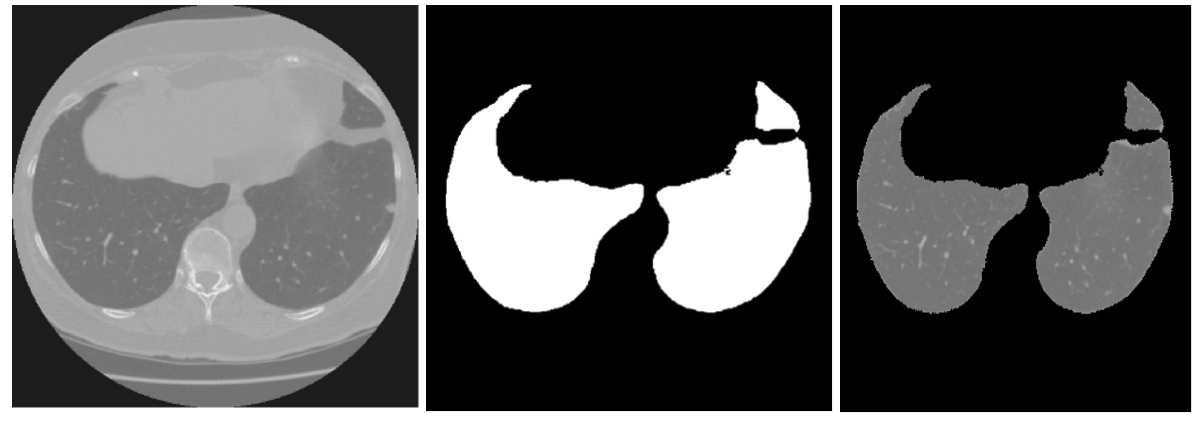
根据以往比赛的经验,肺结节检测需要先把肺部区域提取出来。我们的实战经验发现,这一点很重要。提取肺部区域的好处也很明显:主要体现在减少了无关区域对model的影响,使model在更小的区域规模进行预测。
由于之前有类似比赛,我们综合了前面比赛的一些经验,实现了我们的肺部区域提取代码。大致的流程如下:
1. 根据图形学信息进行label标注,使相邻区域有相同的label。这一过程需要注意,由于实际影像没有严格的区域的划分,导致存在一些很小的区域,这些小区域包含在更大的区域里面,单从label层面讲,他们属于小区域,但它们真正的label其实是和大区域一致的。具体的实现就是参考周围区域的label,进行区域label扩散。可参考scipy.ndimage.binary_dilation函数
2. 提取面积最大的两个label区域,这两个区域就是两个肺结节
3. 由于不同影像的拍摄参数一样,导致影响的origin、spacing等信息也不一样。所以数据重采样是必须的,主要是通过插值把图像的分辨率统一起来。
4. 进行相应的坐标变换,并进行元信息保存。坐标变换需要注意,除去根据origin、spacing进行世界坐标转换外,还需要根据肺部区域,从新更新ground truth的位置信息。
还有一些特殊的影像,依靠上面的步骤很难提取出肺部区域。此时,我们需要进行一些统计分析,总结出这类影像的分布规律,直接对原始影像进行处理。
这部分由于用到了很多图形学知识,很难进行详细说明。我们也是参考了很多前人的实现,所以,想了解更多的可以直接参考我们的实现。
四、模型构建
模型构建就是3D版本的yolo,大家可以去看看yolo相关的文章。Yolo v2获得 cvpr最佳论文提名。需要注意的是,我们的基础网络架构与原paper的有两点重要不同。
1. 基本网络结构我们采用了类似Unet的形式,它的好处是使网络的receptive filed 变得很大,使网络可以同时融合深层网络的语义信息以及浅层网络的context信息。网络结构如下。
2. 我们把采样的数据在原始图形的位置信息利用起来,融入我们的网络。我们认为位置信息有助于肺结节检测。
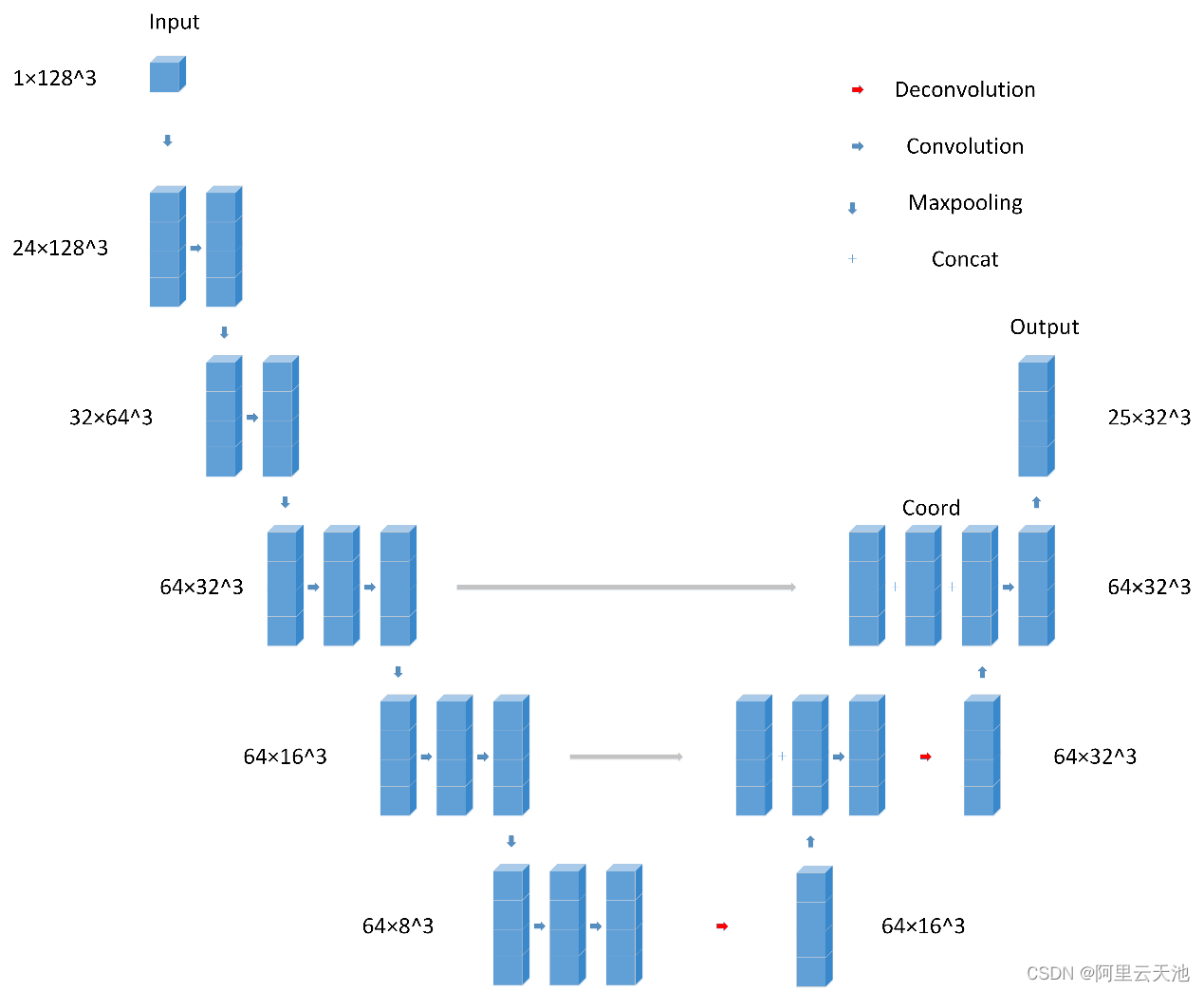
我们的网络结构如图所示,整体来说先做4次卷积操作和pooling操作,然后做2次反卷积(deconvolution),最后得到的输出比原图要小。最后再做一次卷积,num_output为5*5,第一个5表示有5种结节anchor大小,第二个5代表对每一个bounding box预测5个数字,分别代表该bounding box的xyz方向的偏移量、直径大小偏移量、肺结节概率。卷积操作都用了2-3层的ResNet结构(图中没有展示细节),以及BatchNorm操作和ReLU激活函数,每一次反卷积都会先和前面卷积时候对应大小中间结果连接(concat),第二次连接还加入了Coord(大小为[3,32,32,32]),这表示对应每一个点在原图中的xyz坐标。
其他需要注意的有:
1. Online data sample:由于每一个患者的图像大小都不同,每一次获取数据的时候会以结节位置为中心随机crop图像的一部分,大小为128*128*128,这样不仅能提高训练速度,也能增加数据多样性。此外,我们也对crop后的图像做augmetation的操作,随机地翻转、旋转、放大缩小图像。在sample的时候,会控制crop的图像位置,使得70%的crop图像都包含肺结节,剩下30%的图像可能没有肺结节。
2. Hard mining:Kaiming研究组在最新的研究(Focal Loss for Dense Object Detection)中指出。影响物体检测的关键因素是负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。文中提出了focal loss解决这一问题。由于时间原因,我们没有采用focal loss,但是这篇论文揭示了hard mining的重要性。它告诉我们,网络应该关注于那些不容易分类的样本。
3. 结节大小的影响。结节的大小也对网络的构建有很重要的参考意义。小结节(直径为5-10mm)的比例在初赛为50%,复赛为70%。大部分结节都是小结节,因此对预测结果影响极大。而小结节在神经网络中经过几次pooling之后可能就消失了,而大结节不存在这个问题,所以大结节能加速模型的训练。因此在训练过程中要有效地平衡大结节和小结节的数量。
4. NMS(Non-Maximum Suppression):为了丰富肺结节检测的位置分布,我们采用了业界通用的NMS。
5. 模型融合(model ensemble):由于肺结节大小分布的不均匀,导致很难用一个模型或者一个模型的一组参数照顾到所有的肺结节。所以,我们最终的结果集成了多个model/多组参数的结果。做法很简单,做nms的时候同时在多组预测上做。这一点是从google学来的,可参考paper :Speed/accuracy trade-offs for modern convolutional object detectors。