秘塔 AI 搜索:颠覆搜索的常态体验,强大+惊艳
AI 搜索对比秘塔360 搜索Google 搜索KimiGPTs万亿Moe大模型Step百川 3文心一言 3.5自己搞的 langchain + 联网搜索 秘塔 AI 搜索 对比 Google 搜索
AI 搜索对比
秘塔:https://metaso.cn/
360 AI 搜索:https://so.360.com/
先说结论,目前全网最强就 2 款:秘塔、360 AI 搜索。
秘塔在最新内容、学术论文上比 360 更强,使用了多专家混合模型提速和提高效果
比如,今天是 4.8 号,ta引用了4.7号的数据,刚发的婚姻司法解释,这真的牛逼了。
学术论文上还有根据期刊的权威度做一个搜索排名,论文搜索的更精确
我查找视网膜数据集,输入 fundus database,输出:12种类别,共100多万张百万量级的视网膜数据。
这是什么概念,我自己找、以及全网搞视网膜研究的同行,大家找的数据集都是 10 万级别,而且种类和质量还没这个好和丰富。
以后找论文再也不用我一篇篇的看了,输入几个关键词就是你想要的论文。
不像以前只能模糊搜索,然后一篇篇找是不是,免去 99.99% 无用功。
以下是我搜索结果的测试:
秘塔
完全正确 + 证据来源 + 清晰的逻辑

很惊艳。
360 搜索
完全正确 + 证据来源 + 清晰的逻辑

很惊艳。
Google 搜索
Google 搜索,搜索 【YOLO v8 主干网络】,翻了几页,都是说替换主干网络,没说原始网络是啥。
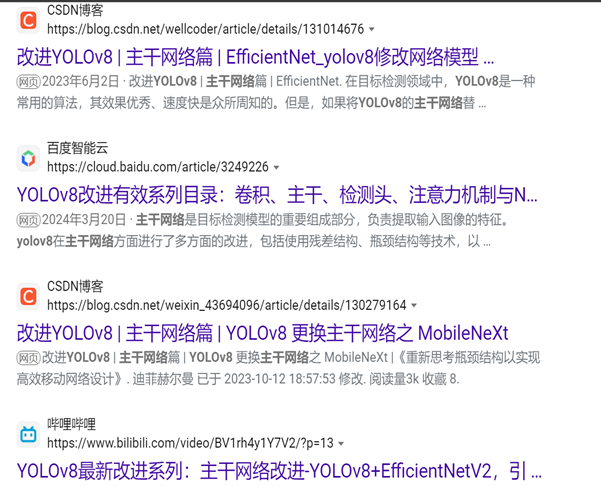
Kimi
一直回答主干网络这个名词的介绍,改成【YOLOv8主干网络是什么】,还是回答笼统介绍。
Kimi说1000字,和没说一样,都是笼统介绍
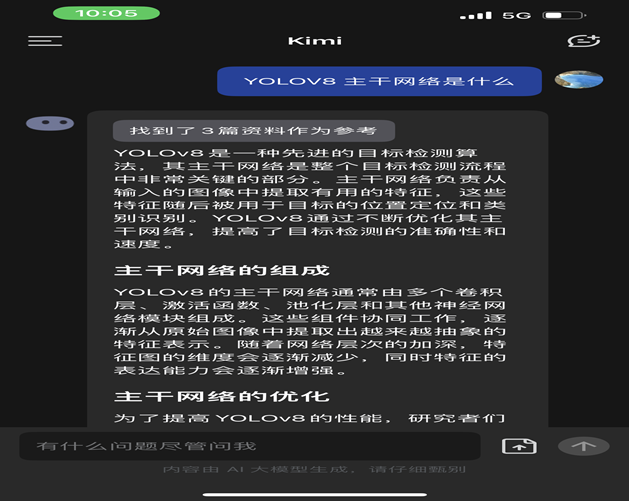
GPTs
正确,但也不敢信,没证据逻辑
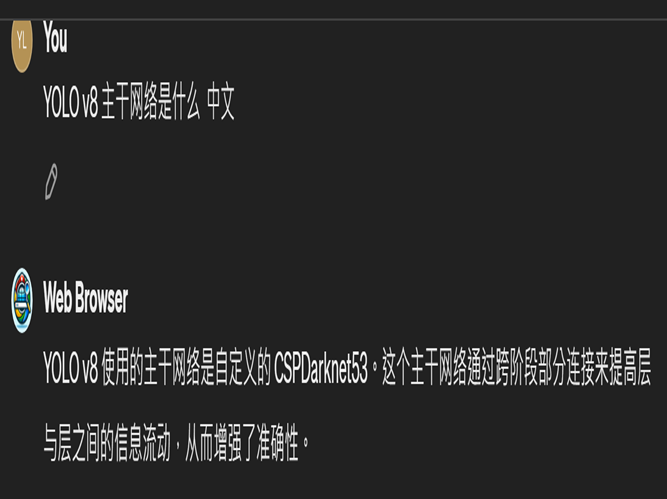
万亿Moe大模型Step

百川 3
百川 3 说,通常是 Darknet-53、 CSPDarknet-53

是自定义的 CSPDarknet-53。
文心一言 3.5
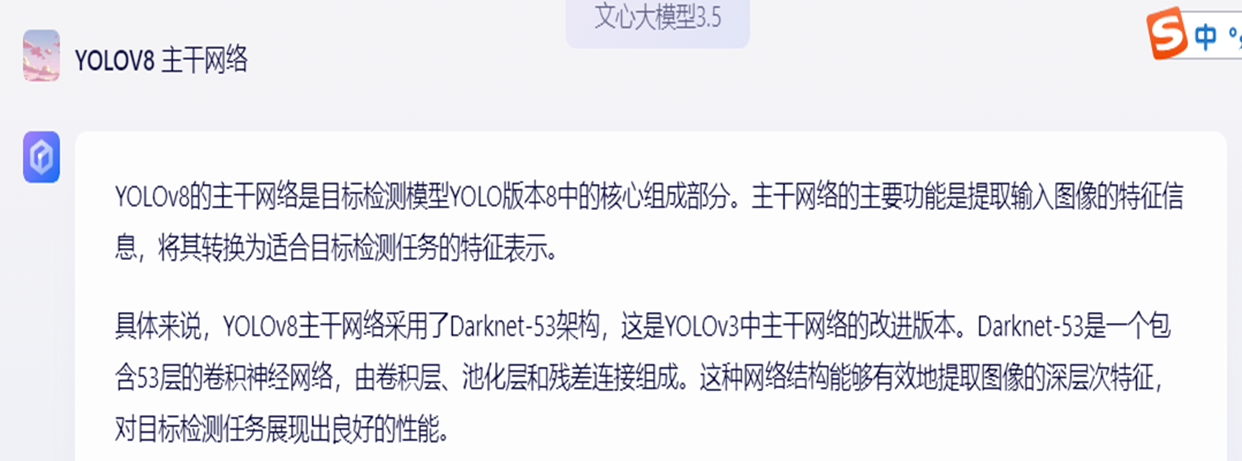
文心不知道怎么搜索的,自定义CSPDarknet-53 说成 Darknet-53。
自己搞的 langchain + 联网搜索
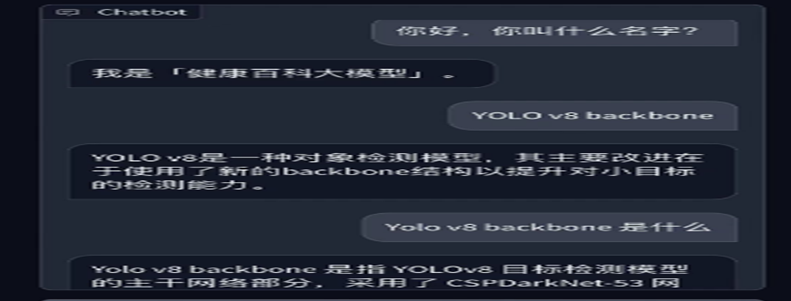
是自定义的 CSPDarknet-53,没说自定义。
秘塔 AI 搜索 对比 Google 搜索
AI 搜索(秘塔搜索)的优势:
只要你能给出一点蛛丝马迹,它就能自动联想,补全你需要来回翻找网页的信息。
支持口语化的表达。
以前搜索框里面都是按照关键词搜索,现在可以支持很复杂的口语化搜索,比如搜索Agent架构速度他太慢了,Moe会转成Agent架构优化等关键词搜索。
人本身就习惯用口语化搜索,但传统搜索引擎搜索的不精确。
给出的内容不亚于一篇专业的测评,而且还综合了其他博主的评测,让你知道最全面的消息,不知道你看了这个之后,还有没有所谓的“信息差”的概念,这是完全透明了。
在搜索页面输入问题后,它不会展示一系列的网页标题和链接,而是试着分析问题并在全网搜索最贴合的内容。最后整合信息之后,再生成一个清晰明了、重点突出的答案。
回答关联信息多,有知识衍生,并能统计/筛选。关联事件、人物、组织信息以表格形式直观呈现,在相关事件中点击“漏斗”图标,能依据事件感情、事件类型做进一步筛查。
汇总相关性强的链接供浏览。
核心不是“搜索+ai”本身,而是“结构化搜索”。
很多时候我们在搜索某块信息时,往往无法“一步到位”准确描述清楚自己想搜什么,是“探索式搜索”,逐步逼近想要的答案。
传统搜索引擎的结果是平铺的、零散的,需要我们自己去梳理,慢慢形成脉络,找到自己想要的信息或学到自己想学的知识。
而Moe一次性就能给你一个大致的、相对清晰的脉络,大幅提高效率。
相比之下,微软的new bing就是单纯的“搜索+ai”,很多时候还没有传统搜索引擎好用,但是这样的搜索方式,依然能让new bing访问量上升了15.8%。
Moe可以基于前文,深度理解用户(不断追问 + 个性化 + 支持复杂查询 + 精确回答)。
在学术论文搜索中更是无懈可击
如果用一个成语来形容就是 — 手眼通天。
穷尽一线科学家的最高理解,天就是当前科学的最高理解,手眼就是你个人的具体问题,你提一个问题,ta就能把俩者结合起来。
结论: 谷歌适合用来精确查找(YOLOv8 CSPDarknet-53),Moe用来“探索式搜索”(YOLOv8 主干网络),而且汇集所有链接,用逻辑串起来再给你。
相较于传统的基于查询关键字的检索方法,该模型引入了大模型,使得系统能够更好地理解用户的意图,从而提高了答案的质量。
当使用后,Moe就是成为你的默认搜索引擎,只有在给出的答案没那么好时,才会用传统搜索引擎再试试。