【论文阅读】基于多实例学习的网络威胁情报行为提取 SeqMask: Behavior Extraction Over Cyber Threat Intelligence Via Multi-Instance Learning
写在最前面1. 摘要原有局限性提出新方法 2. 创新点3. 方法论3.1. SeqMask 概述3.2. 文本表示3.3. 信息提取3.4. TTPs 可能性预测3.5. 提取评估3.5.1. 专家评估3.5.2. 置信度评估

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
论文涉及7位专家的评估,不方便模仿成文,因此只阅读了前面一部分。
图表很好看,后续写论文时可以回顾学习。
Wenhan Ge, Junfeng Wang的论文
SeqMask: Behavior Extraction Over Cyber Threat Intelligence Via Multi-Instance Learning
基于多实例学习的网络威胁情报行为提取
论文地址:https://academic.oup.com/comjnl/article/67/1/253/6852690?login=true#436465905
论文代码:https://github.com/MuscleFish/SeqMask
1. 摘要
原有局限性
虽然上述方法可以定位或识别CTI中的一些TTPs信息,但需要解决以下问题。基于机器学习的方法由于其黑盒性质而难以有效定位 TTP,导致无法形成 TTP 实体。信息提取方法的局限性可分为三点。
(1)数据不足:信息提取的核心是实现对SVO/VO行为短语的提取,这将过滤非SVO/VO信息,使部分证据丢失。识别的结果只能判断行为的归属,但很难定位和推理预测。
(2)验证不完全:信息提取擅长区分行为短语之间的相似性,但不能区分短语中单个单词的贡献。识别方法只能确定分类的准确性,因此难以理解输入文本导致结果的原因或方式。
(3)流程复杂:以前的信息提取框架对NLP技术的依赖性极强,使其工程复制和部署需要苛刻的环境。为了提高准确性,识别方法的神经网络往往又深又大,消耗过多的计算或存储资源。
总而言之,一种简单而全面的分析TTP的方法值得研究。这种方法需要数据解释和高准确性,以获得TTP标签和证据的完整情况。
提出新方法
为了方便有效地处理TTP,该文提出了一种基于多实例学习(MIL)的深度学习框架SeqMask。SeqMask认为“关键词与局部向量空间中所有词的平均值相去甚远”[19],因此对n-gram词/短语使用语义注意机制来过滤行为信息并识别TTP。 与SVO/VO等方法相比,SeqMask不需要对文本进行词性(POS)操作,这不仅简化了流程,而且减少了对关键词来源的限制,区分了信息的相对重要性。
2. 创新点
本文的新颖性和贡献如下。
(1)弱监督行为抽取。与手动开发的过滤模型不同,我们使用 MIL 从 CTI 中提取 TTP 信息。SeqMask是一种弱监督学习场景[20],旨在通过不精确的学习来阐明单词或短语对CTI中TTP的贡献,没有确定的地面实况筛选分数。
(2)多角度信息有效性指标。为了证明SeqMask提取的关键词的有效性,提出了两种质量评估方法。其中一项评估了专家筛选的关键字与通过Jaccard Similarity筛选的模型之间的差异。另一个通过掩盖高分信息来“破坏”原始模型,并记录分类性能的下降。
(3)更多的识别任务验证。本文不仅对短文本CTI的TTPs提取实验进行了TTPs识别实验,还对全尺寸CTI和恶意软件进行了TTPs识别实验。实验结果充分验证了SeqMask的兼容性和扩展性。
在结构上,本文分为以下几个顺序:
第2节介绍了目前CTI识别和关键词提取的方法。
第 3 节讨论了 SeqMask 的功能工作原理或原理。
第4节汇编了实验细节和验证。
第5节总结了全文,并介绍了今后的工作。
最后,第 6 部分是本文的数据可用性声明。
3. 方法论
3.1. SeqMask 概述
为了实现“一种简单而全面的TTP信息识别和提取方法”,该文构建了基于MIL的SeqMask框架。SeqMask 的主要目的是解决计算机自发阅读、理解和概括文本含义的过程。
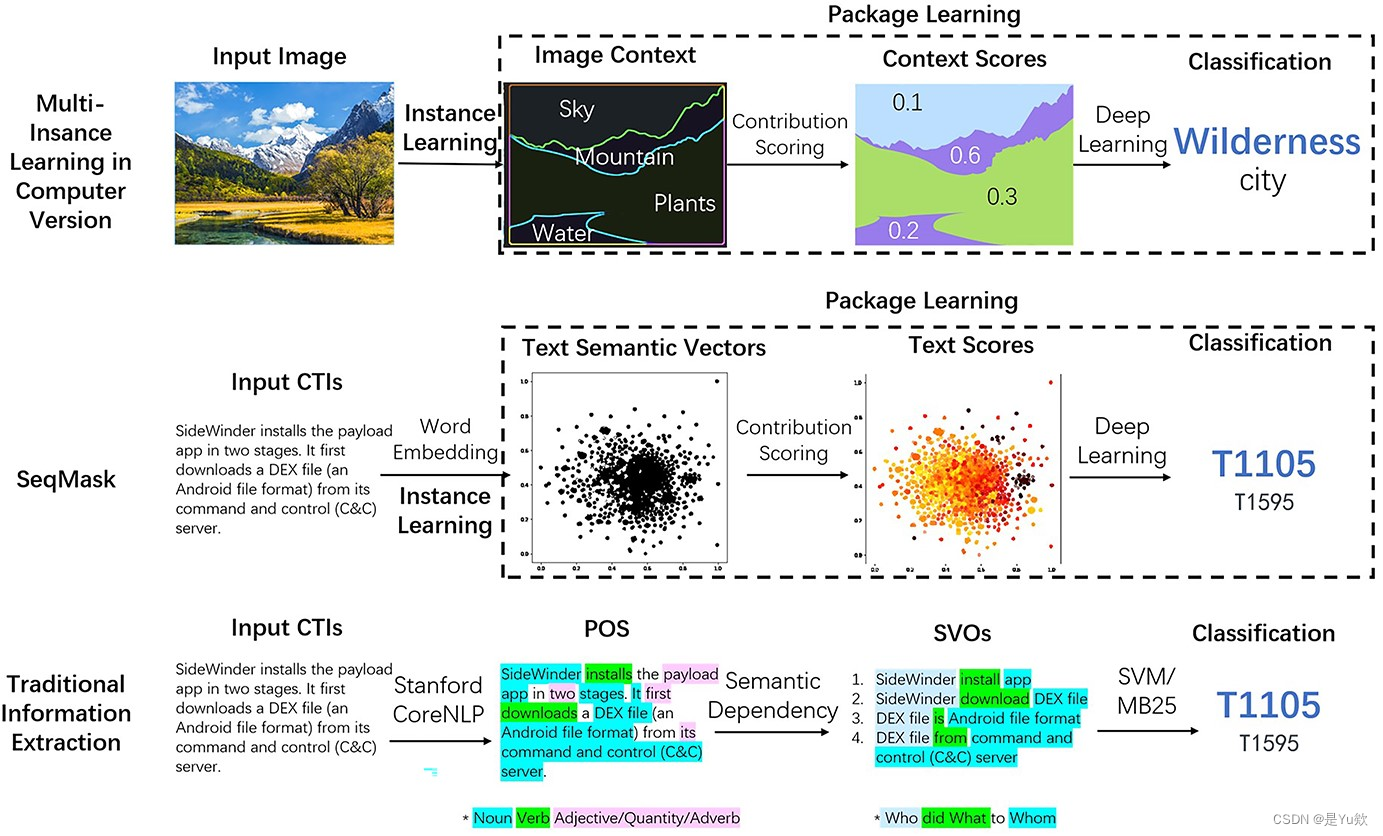
图 1 显示了 SeqMask 与传统信息提取方法的不同之处。
经典的信息提取方法一次删除非 SVO/VO 词,并留下有限的区域来完成行为识别。
然而,SeqMask则根据其对语义的理解,对文本的向量空间进行评分和推荐,并通过组合将关键点映射到相应的语义标签中。因此,SeqMask在处理信息过滤时不会丢弃全局视图和内容,并且可以满足“信息完整性”的基本要求。
为了回答“语义影响TTP标签的内容和方式”,SeqMask需要解决语义分布的规则组合问题。通过深度学习方法,如注意力机制,这种组合可以归纳为三个主要任务:(1)文本表示:如何将CTI文本转换为深度学习可以处理的向量特征;(2)信息抽取:如何对CTI向量特征的语义分布进行划分,(3)TTPs可能性预测:如何利用语义分布实现行为的确定。此外,为了证明SeqMask提取的信息是可用的,提出了一套提取评估方法作为关键字完整性和必要性的度量。以上四个步骤将在后续章节中介绍。
3.2. 文本表示
当 CTI 的文本输入到 SeqMask 中时,它们将按语句进行拆分,以避免不必要的冗余参数。此外,为了防止由于单词失真和大小写问题而不必要地添加到字典中,我们实施了词形缩减、小写和数据清理的正则化方法。
例如,当输入语句“TA459 已利用 Microsoft Word 漏洞 CVE-2017-0199 执行”时,文本预处理方法将首先恢复“已利用”的词法性质,并替换或删除数字,例如将“CVE-2017-0199”替换为“漏洞”,将“TA459”替换为“TA”。然后,所有大写符号都将转换为小写。最后,上面的语句将被转换为单词的集合:“利用 Microsoft Word 漏洞执行漏洞”。
由于SeqMask是一种典型的深度学习方法,因此需要将CTI文本转换为连续分布的词嵌入向量进行训练。为了完全解决 OOV 问题,我们从 Dark Reading、Kerbs on Security 和其他网站的 15 000 多个网络安全博客中训练了一个 FastText [45] 词嵌入表达式。

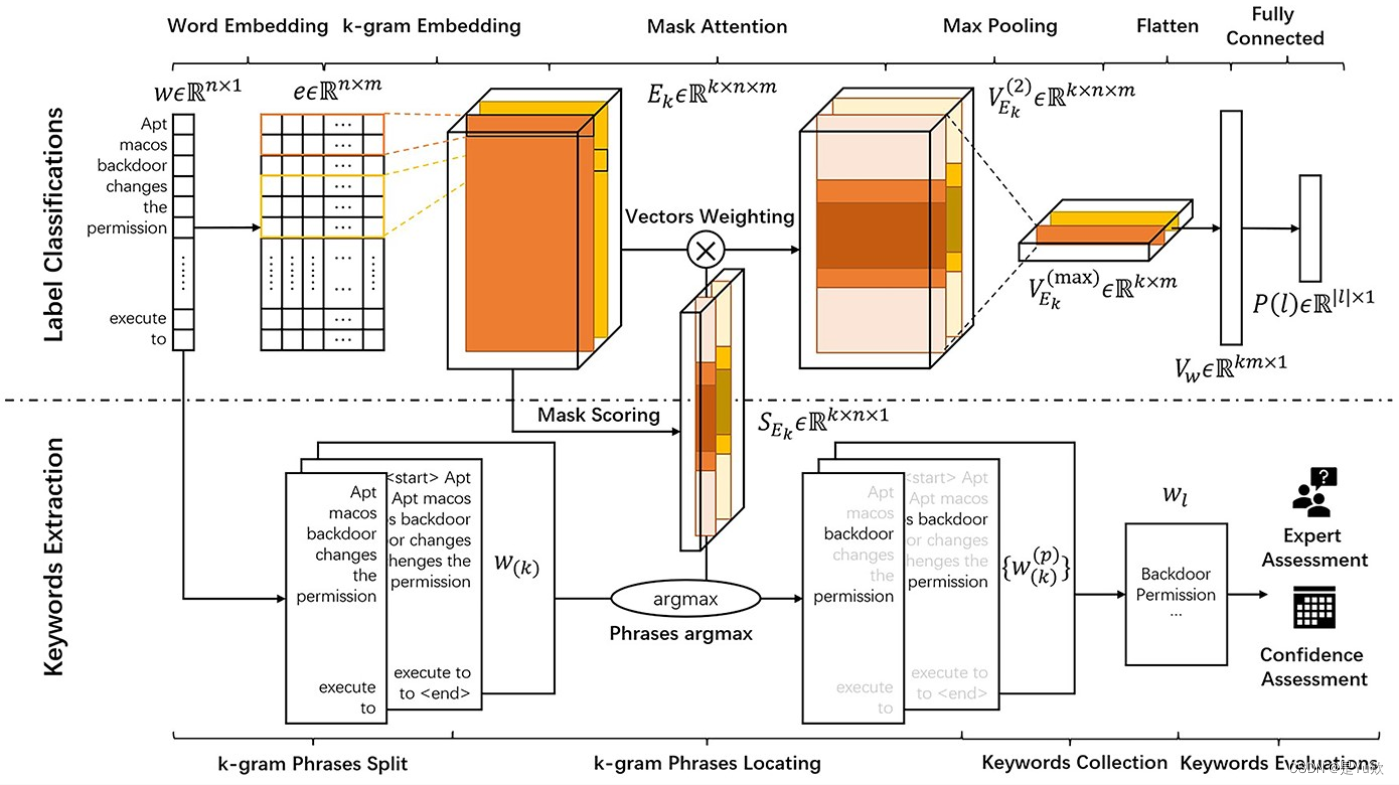
3.3. 信息提取



3.4. TTPs 可能性预测

3.5. 提取评估
由于战术和技术关键信息没有标准答案,因此为关键字质量检查设计了两个特殊评估。一种是专家评估(EA),比较人工和机器生成的关键字相似性。另一个是置信度评估(CA),它按单词重要性的倒序覆盖原始序列,并留下不相关的信息来检测标签推断是否已损坏。
3.5.1. 专家评估


3.5.2. 置信度评估