目录
一、向量数据库是什么
(一)向量数据库发展历史
(二)向量是什么
二、向量数据库的应用场景
(一)向量数据库应用场景
(二)向量数据库产品
(三)向量数据库的搜索原理
(四)向量索引
三、向量数据库的使用
四、向量数据库的发展趋势
一、向量数据库是什么
(一)向量数据库发展历史
向量数据库的发展历程并非严格遵循时间线,而是随着向量检索需求的变化而发展。早期,向量检索的需求相对简单,主要是应用于推荐服务等相似性推荐方面。此时,向量数据库更多地被视为一种程序库,代表性的产品是Facebook开源的FAISS插件库。但是随着技术的进步和应用的不断拓展,向量数据库也逐渐向着更为复杂和多样化的方向发展。
随着不断地发展 ,一些标准化的数据库产品已经认识到了向量检索的重要性,开始在各自的产品中集成了一部分向量特性。这些特性使得它们可以进行一些简单的向量检索,但总体来说,其性能和适用场景仍有较大的局限性。在这其中,比较有代表性的包括像Elastic Search这样的全量检索数据库,还有像PostgreSQL以及Redis这样的数据库,它们都提供了一些向量的特性。
到了现在,随着去年ChatGPT的爆火,向量数据库从幕后正式走向了前台。实际上,向量数据库并不是今年或近两年才出现的新事物,它已经存在很长时间了,但去年ChatGPT的火爆让它真正被大家所了解。

一个完整的AI应用包含了4个重要的环节:
第一个环节是关于大语言模型(LLM),这是大家在AI体系中接触最多的部分;
第二个环节是与模型相关的Embedding;
第三个环节是向量数据库;
最后一个环节是Promote Engineer。
这些环节共同构成了开发一个完整的AI应用所必需的知识体系。
(二)向量是什么
我们首先探讨一下向量究竟是什么,为了更好地理解,这里我举一个简单的例子。对于从事开发或接触过计算机的朋友们来说,大家都知道颜色的表示法。我们都知道,基础颜色是红色、绿色和蓝色。任何一种颜色都可以通过这三种颜色的组合来得到,这就是一个非常经典的向量表示案例。
在这个例子中,我们看到了几个维度。首先,红、绿、蓝这三种颜色可以被视为一个基准维度,它们构成了一个三维坐标系。这个坐标系可以用来定位一个点。当我们混合这三种颜色时,我们实际上是在这个坐标系上从一个点移动到另一个点。这个移动的过程可以看作是一个向量。

我们再举一个复杂一些的例子,设想一下当我们使用向量来描述一个候选人时,我们可能会考虑几个重要的方面。包括候选人的基本信息,例如学历、工作经历、爱好和综合素质等。
当我们进一步细化这些信息时,我们就可以得到更具体的指标。例如,性别可以细分为男性或女性,年龄可以具体到岁数,而学历则可以包括最高学历以及毕业于哪个学校,工作经历也可以具体到工作年限,以及是否曾在知名公司工作过等等。
通过这些细化的指标,我们可以更全面地了解候选人的背景和特点,从而更准确地评估他们的适合程度和潜力。
假设我们选取了十几个维度来描述一个候选人,以编号为1的候选人小王为例,他的个人信息如下:
小王,男性,28岁,清华大学本科毕业。
我们可以通过这些指标对这个候选人进行抽象化的描述。
我们也可以用同样的方式来描述所有的候选人,将候选人的信息进行定量化表示,从而进行更精确的评估。
进一步地,我们可以将这些信息引入到数学模型中。比如,我们可以根据姓名的规则生成一个数字,使用哈希函数将姓名转换为一个数值。这样,我们就可以将候选人的信息表示为一个向量。
通过这种方式,我们将十几个维度通过数学方式表现出来,最终得到了一个简单的向量化的表示,也就是下图中的3。将候选人的信息进行数字化处理,从而更好地进行比较和分析。

向量数据库中存储的数据实际上是一堆浮点数,这些浮点数排列在一起就像一个数组。这些浮点数的个数在向量数据库中被称为维度。通过这些维度,向量数据库可以存储和检索海量的高维数据,支持复杂的查询和分析操作。
总结一下,向量数据库是一种特殊的数据库,它具备数据存储和读取的基础能力,同时也有一个特殊的查询操作,即向量检索。
向量检索是通过向量的匹配来找到最相似的数据,而不仅仅是简单地查出一行数据。除了这个特殊的功能,向量数据库还具备了数据库的基本特征:数据的改查。对于开发者来说,改查是最基本的需求,而向量数据库也必须具备这些基本功能。
此外,一些向量数据库产品还需要与结构化数据进行结合。在关系模型和关系数据库中,有些需求需要与向量进行结合才能更好地满足。且向量数据库还能够利用硬件特性来加速计算过程,例如使用CPU、GPU等显卡来提高计算效率。
对于一个成熟的数据库,特别是分布式产品,它还必须具备高可用性和分布式的弹性能力。因此,在选择和使用向量数据库时,我们需要考虑这些特点以及我们的具体需求,以便更好地实现我们的目标。
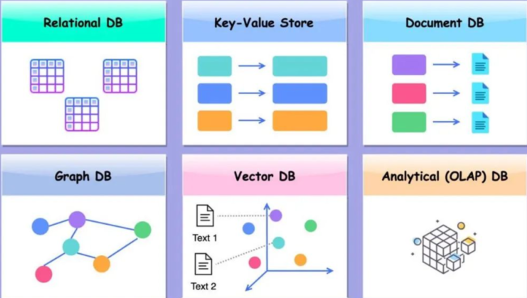
常见数据库类型
上图中展示了几种常见的数据库类型,对比一下平时使用较多的各种数据库:
●第一种就是关系型数据库,其表现特征为二维表格,行和列清晰分明;
●第二个是KV数据库,它以键值对的形式存储数据,且value可以是多种类型,如字符串、数字或二进制等;
●第三种是文档型数据库,如MongoDB,它是通过一对一的映射关系来存储数据;
●第四种是图数据库,以网状结构呈现数据;
●第五个就是向量数据库,在向量数据库中,我们看到了一个三维向量的图,每个向量的数据都可以映射到这个三维坐标系上的一个点;
●最后是分析型数据库,即OLAP数据库,它通常是列存数据库,是在实际应用中使用较多的一类数据库。
回到向量数据库,最终存储到数据库里的实际上是一堆浮点数字。通过将一张图片进行embedding处理,我们得到了它所对应的浮点数向量。这个向量的维度越高,说明转化后的精细度也越高,但相应的计算资源消耗和对硬件条件的要求也会随之增加。
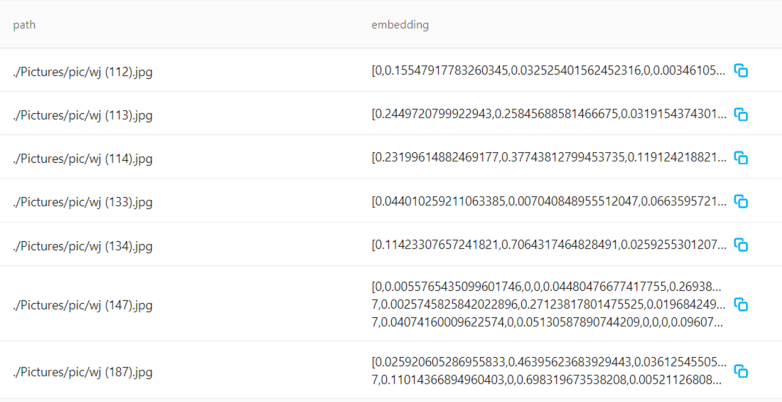
向量数据的结构
二、向量数据库的应用场景
(一)向量数据库应用场景
在初步了解向量数据后,我们来进一步看一下它的应用场景。基于现代数据库的向量检索特性,我们可以将向量数据应用在多个特定场景中。其中,推荐系统是我们日常最常见的应用之一。例如,在刷视频、新闻、购物等相关推荐时,向量数据可以发挥重要作用。
除此之外,图像检索也是向量数据的应用场景之一。相信大家应该都使用过图像搜索功能,现在许多电商APP都具备通过图片扫描产品直接进行搜索的功能,而无需我们自己手动输入产品名称。例如,我们想要购买一台电脑,只需用手机拍摄该电脑,APP即可帮助我们搜索同款产品。类似的,人脸识别、OCR技术用于识别图片中的某些信息等也是向量数据的应用场景。
除了上述举例的之外,许多非结构化数据也是向量数据库可以处理的。非结构化数据指的是那些不能单纯使用传统关系模型描述的数据,如音频、视频、图像等。通过转化处理,这些非结构化数据可以得到相应的数据库,再进行关键性分析。
//一个以图搜图的具体过程示范:
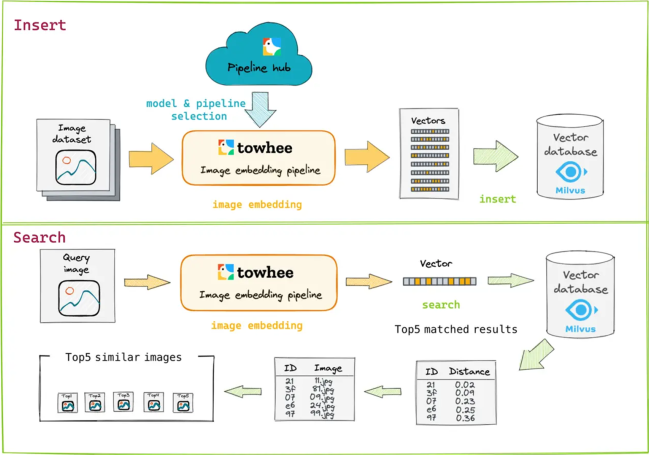
首先,假设我们有一个数据集,里面包含一万张图片。将这些图片通过embedding算法转化成向量数据,比如1000维的向量。然后,这些向量数据会被存储到一个向量数据库中。
当数据库构建完毕后,我们如何找到与指定图片相似的图片呢?可以通过search操作来完成。例如,我指定一张图片,通过相同的embedding模型,在embedding过程中会引入领域中的大语言模型。通过大语言模型的能力,我们可以得到这张图片的向量表示,然后将其传送到向量数据库中进行检索。
在检索过程中,我们利用向量之间的相似度关系进行匹配。当我们找到匹配的图片时,可以选择返回最相似的5张图片。每张图片都有一个距离描述与指定图片的相似度。这个距离越小,说明这两张图片越相似。
通过找到匹配图片的ID和路径,就可以在前端展示搜索结果了。
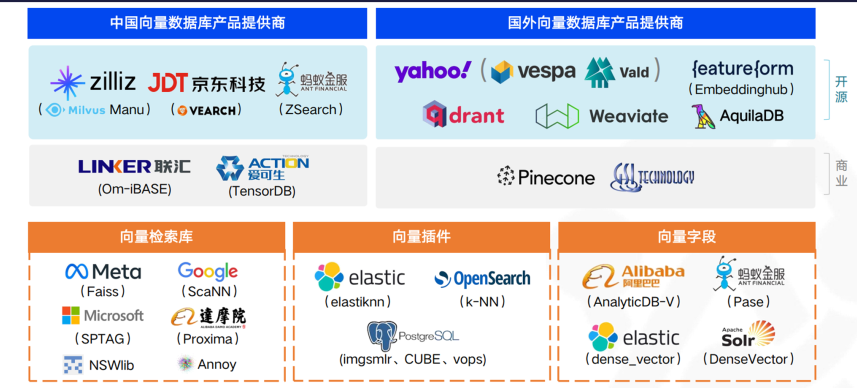
(二)向量数据库产品
目前市场上存在许多向量数据库产品。从国内和国外两个维度来看,国内有Milvus Manu、京东的VEARCH、蚂蚁金服的ZSearch等产品。Milvus是目前向量数据库赛道里较为热门的产品,而京东和蚂蚁更多的是将它们的应用于内部场景,外部使用较少。
在海外来看,大公司都有自己的向量数据库产品,比较知名的有如Qdrant和Weaviate等等。此外,Pinecone是目前商业向量数据库市场最热门的产品。国内的商业数据库产品有联汇和爱可生自己开发的向量数据库产品,当然这些产品都是基于开源产品进行包装的。
从三个维度来看,这些向量数据库可以分为:向量检索库、向量插件和向量字段。在检索库方面有Meta的Faiss、微软的SPTAG,谷歌的ScaNN等等。插件方面包括ES、OpenSearch和PG等产品中都集成了向量的特性。而向量字段则是数据库本身集成的向量特性,但功能相对较弱。
(三)向量数据库的搜索原理
了解完数据库的产品后,我们先返回来给大家讲解一下向量数据库的搜索原理。这一部分可能会需要一些数学知识。首先,我们回顾一下常用的两种搜索方式:欧氏距离和余弦相似度。
欧氏距离是指计算两个向量之间的直线距离。在二维坐标系中,假设有两个向量p和q,欧氏距离就是计算p到q中间连的这条直线的距离。在三维坐标系里,每一个向量包含x、y、z三个坐标点,根据公式计算任意两点之间的距离。而在n维坐标系里,有100个坐标点,根据公式计算任意两点之间的距离。距离越短,说明这两个向量在某些维度上相似性越高。

另一种方式是余弦相似度。除了距离,我们还可以通过向量之间的夹角来描述它们之间的关系。在二维坐标系中,如果夹角越小,说明两个向量之间的关联性越高。我们可以使用公式计算任意两个向量之间的余弦相似度。在三维坐标系里,也可以用同样的原理来计算任意两个向量之间的夹角和余弦相似度。
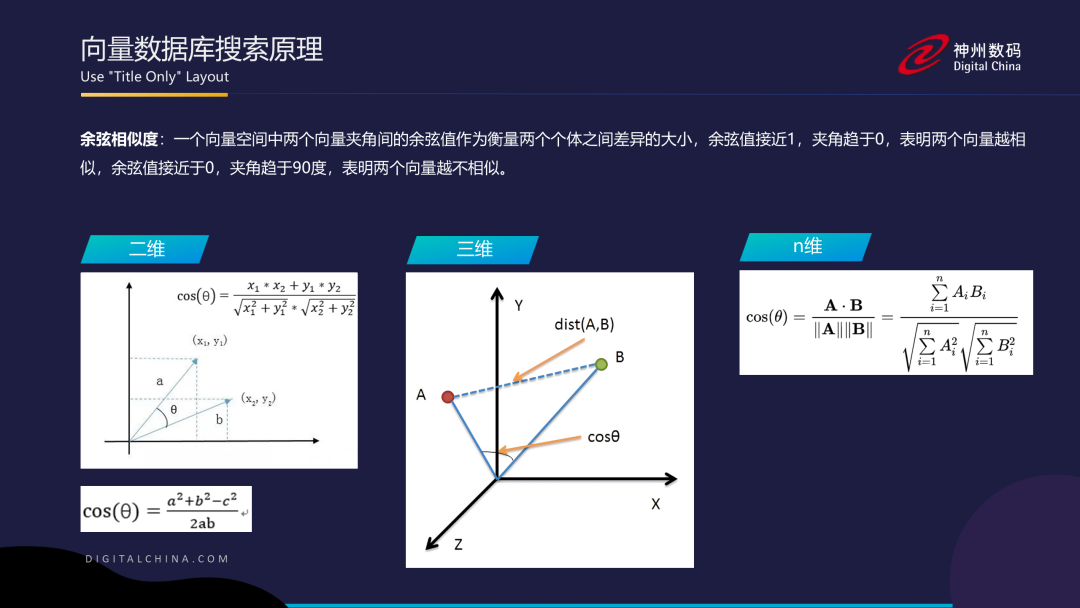
这些方法在向量数据库的搜索中非常常用。当然,除了这两种方法,还有很多其他的方法可以用于向量数据库的搜索,感兴趣的小伙伴可以自行查阅资料进一步了解。
(四)向量索引
前面讲述了向量数据库的检索原理,但实际上,在向量数据库中进行相似度匹配时,不能完全按照公式计算,因为向量数据库的数据量通常很大,维度也很高。
如果使用公式计算两个1000维向量之间的相似度,计算量比较大,而且对CPU的计算密集型需求很高。那如果有一亿个向量,每个都要计算一遍的话,时间和计算成本都会更加高。因此,我们此处引入了一个概念叫做向量索引。
向量索引(vector index):是指通过某种数学模型,对向量构建的一种时间和空间上比较高效的数据结构。借助向量索引,我们能够高效地查询与目标向量相似的若干个向量
向量索引与关系数据库中的索引类似,但有一点不同。在向量数据库中,通过向量索引找到的是近似结果,而不是100%准确的结果。向量索引描述的是相似度的程度高和低。因此,我们称之为近似最邻近搜索(ANS)。如果没有向量索引的话,寻找一个向量的相似度就类似于关系数据库中的全表搜索。但是,在全表搜索之上还要多加一层的运算,因此成本比关系数据库中的全表搜索要高很多。

三、向量数据库的使用
此前讲述了较多的概念,现在让我们来看看一下向量数据库的的使用情况。这里将介绍一个产品和一家公司。
这家公司叫做Zilliz,成立于2017年,是一家面向全球的中国开源公司。这意味着公司的核心团队和创始人主要来自中国,但他们将自己定位为一家面向全球的开源公司,致力于全球业务。
自成立以来,Zilliz已经获得了大量的融资,累计达到一点多亿美元。这意味着市场对他们的认可度很高,可以说是目前全球开源向量数据库领域最受欢迎的公司之一。
在2019年,Zilliz推出了自己的向量数据库产品——Milvus,并在2022年推出了Milvus 2.0。此外,他们还在语音服务领域推出了Zilliz Could产品。目前,已有1000多家用户在使用他们的向量数据库。

下图是这个数据库的一个结构图,这其实是一个经典的分布式系统。
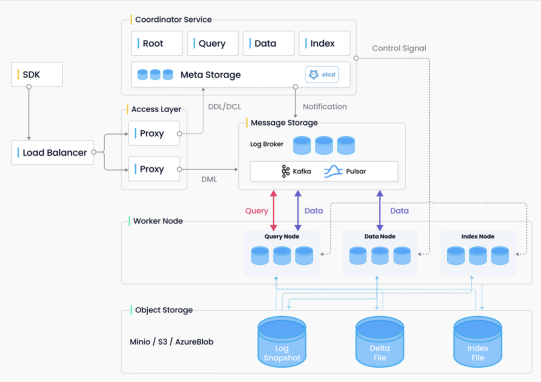
根据架构图显示,它采用存算分离的架构,最底层是存储层,使用了相对廉价的S3对象存储,兼容其他S3存储系统,如AzureBlob等等,未来还计划支持本地存储如SOD或内存储等。存储层之上有一排称为Worker Node的节点,这是计算层,不同角色承担不同任务,如查询、数据节点、负责数据读写和索引等。在架构图的上方,有一个较大的模块负责协调和管理整个集群,这里面分了几个大类,其中Root节点管理整个集群的元信息,Query、Data和Index则是对应计算节点的不同角色。整个中间层通过日志先行理念实现数据流转,所有数据流转都是通过日志来分发来实现的。所以我们可以看到中间有一个转发器称为Message Storage,早期引入通常使用的是Kafka,现已更换为Pulsar,这是一个著名的分布式消息中间件。最后是代理层,与前端和应用对接的部分,通过负载均衡器转接请求并进行转发等操作。
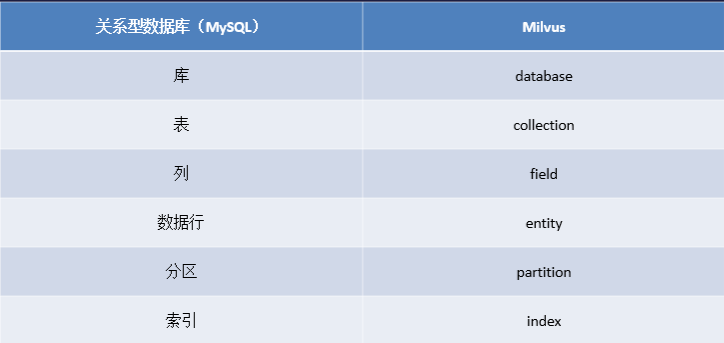
上面内容中提到了一些特定的术语表,这里将其整理并与关系型数据库(以MySQL为例)进行一一对应,以帮助大家更好地理解。
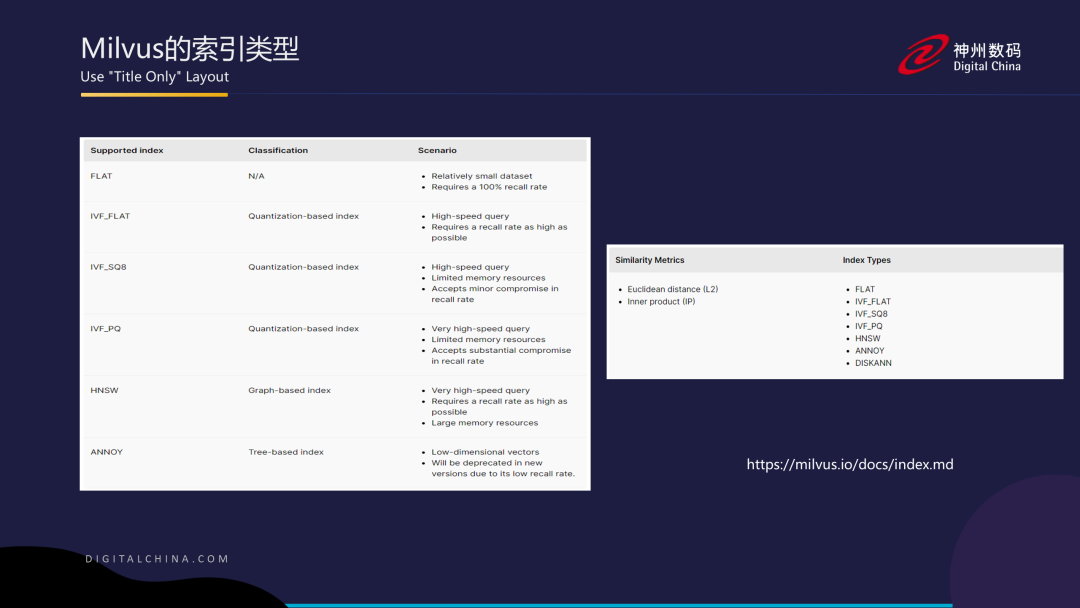
这里着重讲一下索引,在操作数据库时,很多时候我们需要自己指定索引类型。不同的索引类型适用于不同的场景,并且这些不同类型的索引底层使用的是不同的数据结构。例如,我们前面讲到了基于图的索引和基于哈希的索引等等。
此外,从右边的图片中可以看到,这些索引类型都支持我们前面提到的两种相似度检索模型:欧氏距离和余弦相似度。在Milvus中,欧氏距离简称为L2,而余弦相似度是通过两个向量之间的内积来表现的,简称为IP。
此处在分享中有一个实践案例:连接数据库,然后进行查询和搜索操作。通过这个案例,你可以感受到在实际应用中如何使用向量数据库。
感兴趣的小伙伴可以前往B站【神州数码云基地】收看完整分享课程:
别说你还不懂向量数据库?AI时代入门必学|AI入门系列课程
四、向量数据库的发展趋势
随着人工智能的崛起,相信大家都已经感受到从去年ChatGPT诞生到现在AI所带来的冲击。只要人工智能持续发展,与其相关的生态链也会随之持续升温。下图列举了向量数据库中几个知名的产品及其融资情况。可以看到,像Pinecone和Milvus这两个典型的产品,他们的融资均已经超过1亿美金。在基础软件领域,这个金额已经是非常可观的了,特别是这些融资大部分都发生在疫情之后,这是一个很难得的趋势。
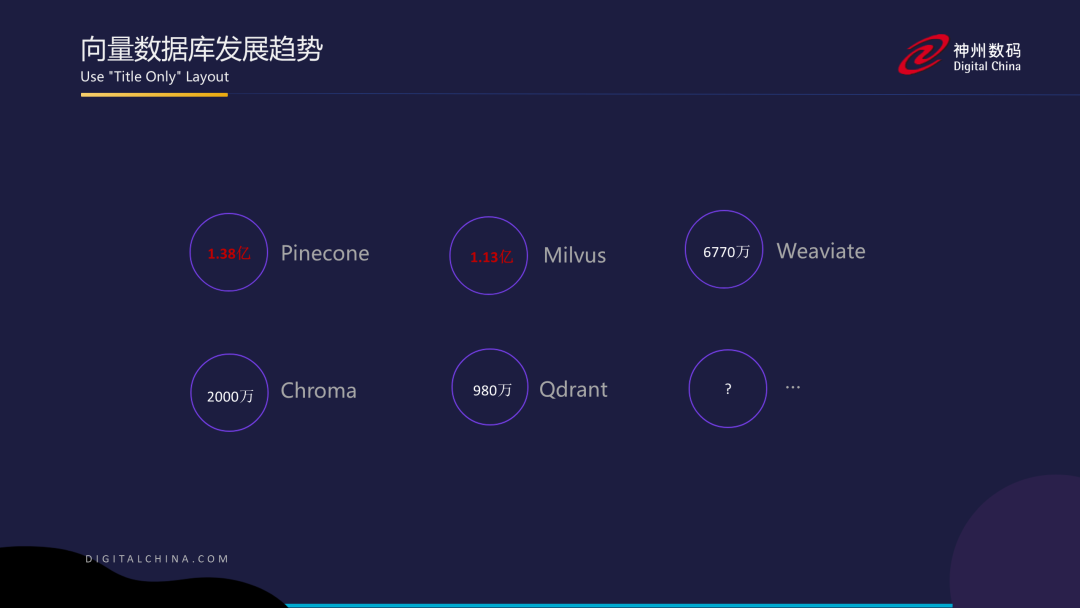
获得了投资圈普遍认可,可以预见的是向量数据库的发展前景一定十分光明。就像10年前移动互联网爆发时,也有一批开源数据库厂商崛起,其中最典型的就是MongoDB。此后,诞生了许多知名的开源数据库公司。同理,人工智能的发展符合技术发展领域未来十年的基本趋势,那么向量数据库也一定会成为一个非常耀眼的赛道。
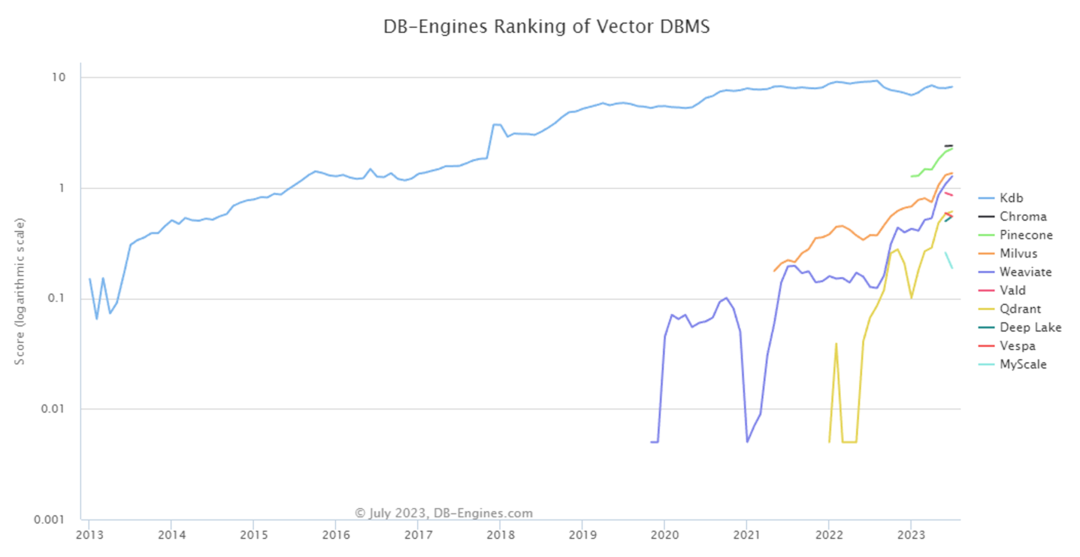
这张图是前段时间截取的向量数据库发展趋势图。从图中可以看到,大部分数据库产品都是在2020年左右或者之后才开始蓬勃发展的。这表明了这个行业是一个非常新兴的行业,每个厂商和数据产品都有上升的势头。
在比较头部的一些产品中,如Pinecone、Milvus包括Weaviate等,它们的增长幅度非常大。这一部分说明了这些头部产品在行业中的领先地位和其优秀表现。
另外也恰恰说明了一点就是向量数据库的发展也与AI的崛起密切相关。特别是ChatGPT这样的大模型的诞生,促进了向量数据库的快速增长,凸显了AI技术对向量数据库发展的重要性。
向量数据库是一个非常有前景和潜力的行业,相信未来随着AI技术的不断发展,向量数据库也必将迎来更加广阔的发展空间。
分享者 :何傲 | 高级后端开发工程师
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,回复关键词【向量数据库】获取原文PPT材料。







