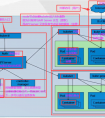
量化、剪支、蒸馏
注意:这三种方法是三选一!不能同时用
Q:为什么不能同时用?
A:技术上可以同时用,但没有必要
每一种优化(压缩)方式都会对模型精度有一定的影响,同时用更会叠加这种影响。如果精度损失过大,就得不偿失了
优化方式:剪枝
面试会问!dropout和剪枝的区别
dropout:以批次为单位,每批次随意抑制神经元(下一批次可能就不抑制了)
剪枝:完全减去参数
正则化的介绍:
https://baijiahao.baidu.com/s?id=1653085297096293714
L1正则化基础:在损失函数中增加——取参数的绝对值,让参数尽可能为0,减少网络规模
L2:在L1基础上,只使参数尽可能“变小”
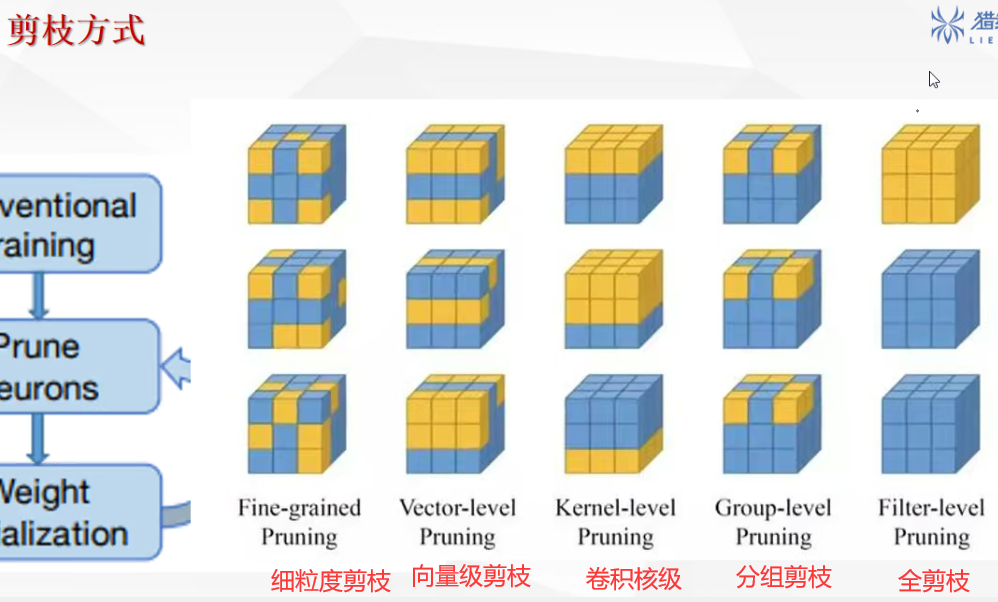
剪枝分为两种:结构化剪枝/ 非结构化剪枝:
结构化剪枝:剪去的是网络层,会改变模型的结构,(对模型影响比较大)
非结构化剪枝:剪的是神经元不会改变模型的结构
【注意!有的硬件是不支持非结构化剪枝的!】
全局剪枝:只支持非L1结构化剪枝
由于是“删去加起来的总共20%权重”,所以会着重减中间的+不可控,所以不推荐
不同剪枝的差异:
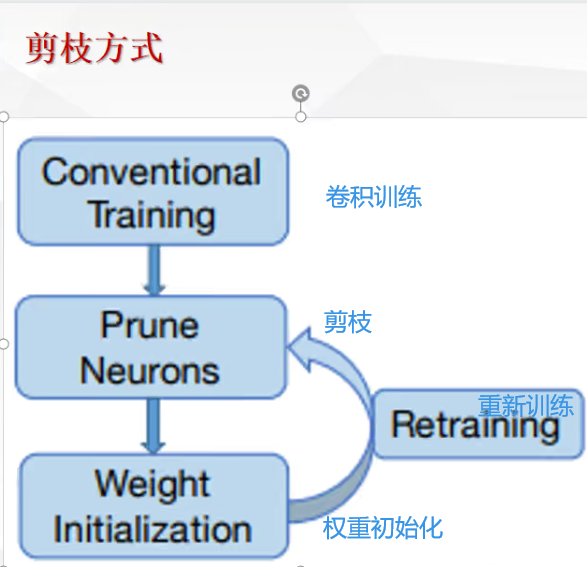
剪枝的步骤(及其根本问题):
每次剪枝后都要重新训练,效率极低
用的最多的是量化
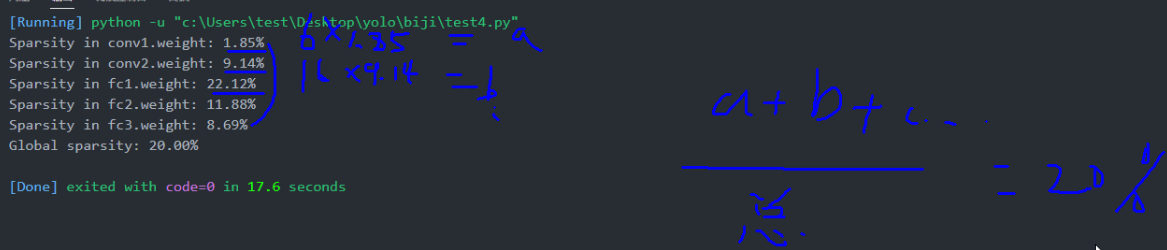
查看参数变化的方法:
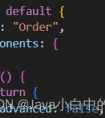
list( module.named_parameters() )
这个方法可以打印模型参数,也会保留原版参数
剪枝知识点概览:

优化方式:蒸馏
从复杂的网络中,提取有用部分,组成一个小模型
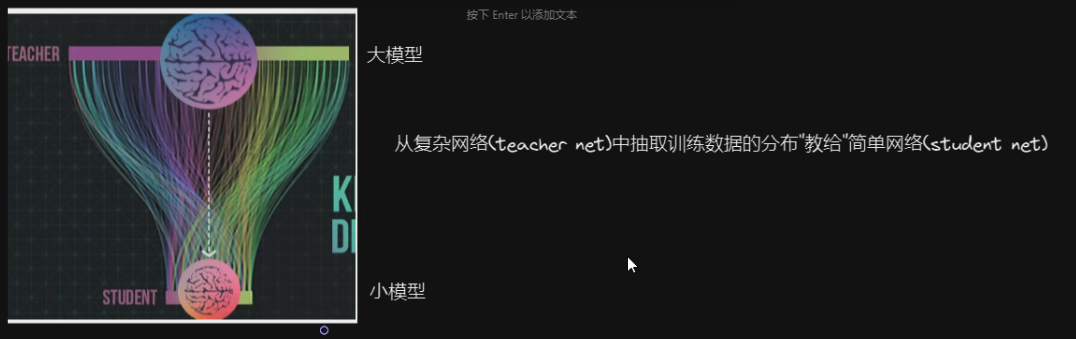
原理即为“教导”
教导的方式:
输出一组概率(软目标),而不是简单的一组one_hot(硬目标)。是一种“极大似然估计”
蒸馏过程:“学习”和“考试”
蒸馏的操作之一:加入T作为softmax的输入(教师和学生都加),使大值更大,小值更小
蒸馏的应用场景:
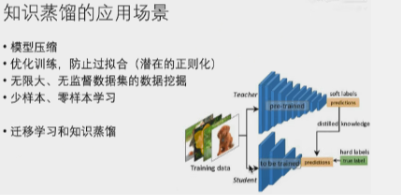
前提:当网络只能刚刚好拟合时,就不能再蒸馏了(目前大部分网络都过大了)
而且也不能无限缩小(小网络的损失要合适)
————————————————————
蒸馏的具体操作

这里的参数“小写t”,要根据具体情况而定(整数,1~3这种)
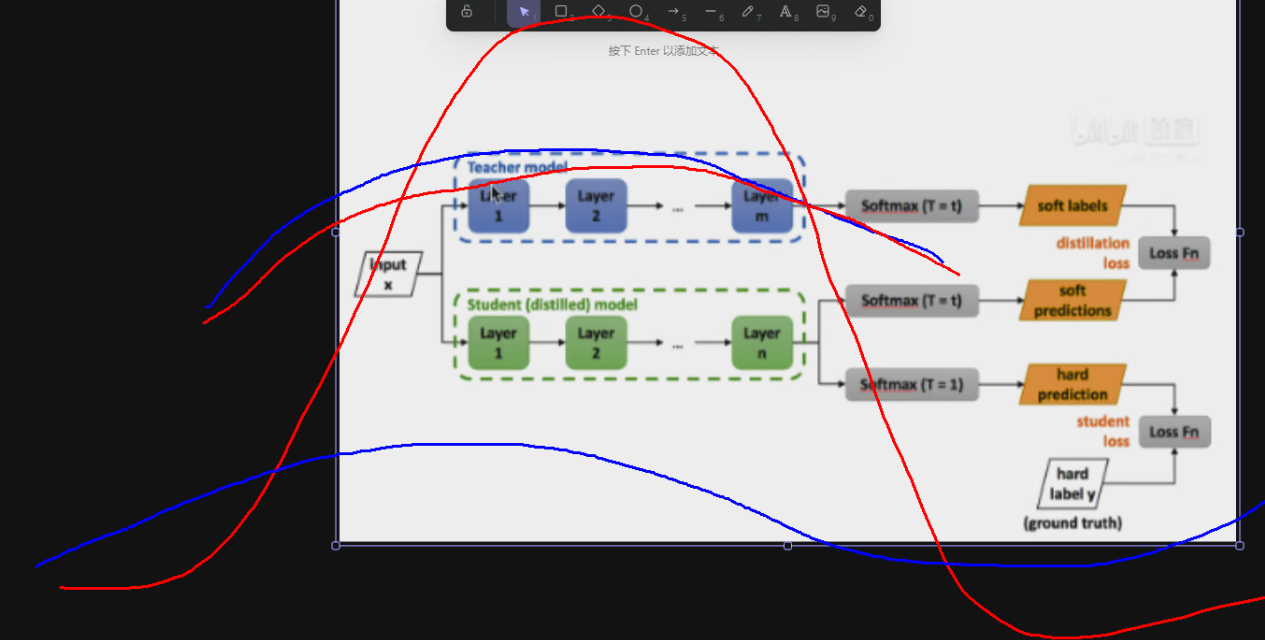 大小会影响“输出概率的平缓程度”,也可以用来调整“老师/学生输出之间的相似度”
大小会影响“输出概率的平缓程度”,也可以用来调整“老师/学生输出之间的相似度”
越大会让曲线越平缓,越小会让曲线越陡峭
选择学习时、损失函数的选择:
交叉熵:两条分布曲线相似
相对熵(KL散度):不仅相似,距离也要接近

使用注意:记得带上这个参数
蒸馏知识点概览:

优化方式:量化
量化:最实用
但pytorch对量化的支持不好
常用程度:量化 > 蒸馏 > 剪枝
量化:将训练好的网络的权值,激活值从高精度转化为低精度的操作过程
优点:
1.减少内存和存储的占用
2.降低功耗
3.提升计算速度
量化的对象:
1.权重
2.激活函数的输出
3.梯度(用于降低分布式计算的通讯成本)
pytorch的量化还在测试,还只支持CPU
知道最大值的数据,可以直接÷最大值来量化
不知道最大值的数据,用标准化(用方差和期望/平均值)来量化
在使用标准化时,dtype=quint8
量化知识点概览: