目录
一、成员访问
1、operator[ ]&at
2、front( )&back( )
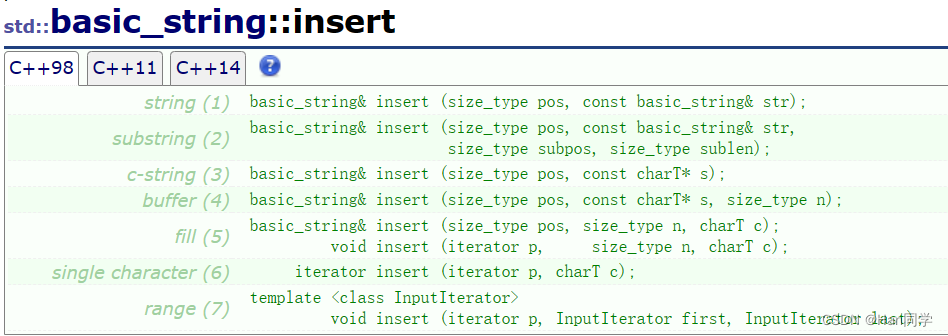
二、插入元素 insert( )
三、删除元素 erase( )
四、替换元素 replace( )
五、查找元素 find( )
六、交换字符串 swap( )
七、C风格 c_str
八、rfind&substr
一、成员访问
1、operator[ ]&at

虽然二者功能一样,但[ ]比较常用。
int main(){string s1("hello world");cout << s1[4] << endl;cout << s1.at(4) << endl;return 0;}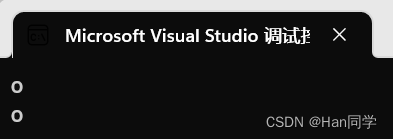
访问越界[ ]会直接报错,.at( )会抛异常。
int main(){string s1("hello world");try {s1.at(100);}catch (const exception& e) {cout << e.what() << endl;}return 0;}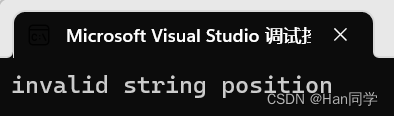
2、front( )&back( )
int main(){string s1("hello world");cout << s1.back() << endl;cout << s1.front() << endl;return 0;}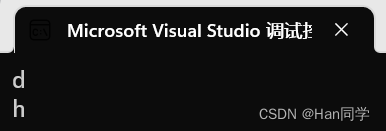
二、插入元素 insert( )
insert/erase不推荐经常使用,能少用就少用,因为他们可能都存在要挪动数据,效率低下。
指定位置插入字符串。
int main(){string s1("world");s1.insert(0, "hello");cout << s1 << endl;return 0;}
指定位置插入单个字符
s1.insert(0, "w"); 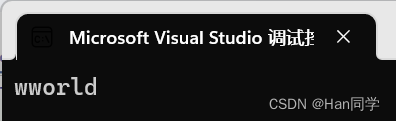
两种方式指定位置插入空字符
使用单引号需要加上插入字符个数(第二个参数),使用双引号不需要。
int main(){string s1("world");s1.insert(2, 1, ' ');s1.insert(3, " ");cout << s1 << endl;return 0;}
插入可以借助迭代器的begin()和end()获取位置。
s1.insert(s1.begin()+2, ' ');s1.insert(s1.end() - 1, ' ');
三、删除元素 erase( )
insert/erase不推荐经常使用,能少用就少用,因为他们可能都存在要挪动数据,效率低下。

删除指定位置指定长度字符。
int main(){string s2("hello world");s2.erase(5, 1);cout << s2 << endl;return 0;}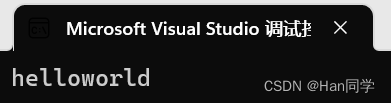
也可以使用迭代器。
s2.erase(s2.begin() + 5);
如果长度大于字符串长度或者缺省,则删除指定位置开始一直到最后的字符。
s2.erase(5, 30); s2.erase(5);
四、替换元素 replace( )
replace()函数的第一个参数是替换的起始位置,第二个参数是要替换的字符数,第三个参数是替换的字符串。
int main(){string s1("hello world");s1.replace(5, 1, "&&&&");cout << s1 << endl;return 0;}s1被初始化为"hello world"。这是一个注释行,不会被执行。然后,使用s1.replace(5, 1, "&&&&")函数调用来替换字符串s1中从索引位置5开始的1个字符,将其替换为"&&&&"。接下来,使用cout对象和<<运算符将修改后的字符串s1输出到标准输出流。 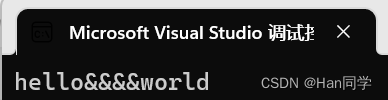
使用replace时,空间不够扩容,还要移动数据。
五、查找元素 find( )
find()用于在字符串中查找指定子串的第一个出现位置。

find()函数有多个重载版本,其中最常用的版本接受一个参数,即要查找的子串。它返回一个整数值,表示子串在字符串中的位置索引。如果找到了子串,则返回第一个匹配的位置索引;如果未找到子串,则返回一个特殊的值std::string::npos。
int main(){string s1("hello world I love you");size_t pos = s1.find(' ');while (pos != string::npos) {s1.replace(pos, 1, "***");pos = s1.find(' ');}cout << s1 << endl;return 0;}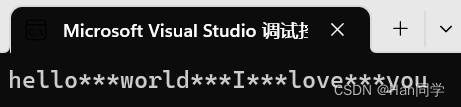
我们可以对上述程序进行优化。
int main(){string s1("hello world I love you");size_t num = 0;for (auto ch : s1) {if (ch == ' ')++num;}s1.reserve(s1.size() + 2 * num);size_t pos = s1.find(' ');while (pos != string::npos) {s1.replace(pos, 1, "***");pos = s1.find(' ',pos+3);}cout << s1 << endl;return 0;}s1的字符串对象,并将其初始化为"hello world I love you"。然后,使用一个循环遍历字符串s1中的每个字符。在循环中,如果当前字符是空格,则将计数器num加1。接下来,使用s1.reserve(s1.size() + 2 * num)函数调整字符串s1的容量,以便能够容纳替换后的字符串。这样做是为了避免在替换过程中频繁地重新分配内存,提高性能。然后,使用s1.find(' ', pos)函数来查找字符串s1中下一个空格的位置。如果找到了空格,将其位置存储在变量pos中。接下来,使用s1.replace(pos, 1, "***")函数将找到的空格替换为三个星号"***"。这样做会修改字符串s1中的内容。然后,使用pos = s1.find(' ', pos + 3)来查找下一个空格的位置,从上一个空格的位置加3开始查找。这样做是为了避免重复替换已经被替换过的空格。循环会一直执行,直到没有更多的空格被找到。最后,使用cout对象和<<运算符将修改后的字符串s1输出到标准输出流。 还可以使用+=运算符进一步优化。
int main(){string s1("hello world I love you");string newStr;size_t num = 0;for (auto ch : s1) {if (ch != ' ')++num;}newStr.reserve(s1.size() + 2 * num);for (auto ch : s1) {if (ch != ' ')newStr += ch;elsenewStr += "***";}s1 = newStr;}与之前的版本相比,这段程序是对第一段程序的改进版本,具有以下特点和优点:
更简洁:第二段程序使用了更简洁的方法来替换字符串中的空格,避免了使用循环和查找函数。
更高效:第二段程序只需遍历一次原始字符串,而不是使用循环和查找函数多次遍历。这样可以减少时间复杂度,提高程序的执行效率。
更易读:第二段程序使用了更直观的方式来替换空格,通过判断字符是否为空格来决定添加字符还是添加"***"。这样代码更易读懂,减少了冗余的操作。
更节省内存:第二段程序使用了新的字符串newStr来存储替换后的结果,避免了对原始字符串s1进行频繁的修改。这样可以减少内存的使用,提高程序的效率。
六、交换字符串 swap( )
int main(){string s1("hello world");string s2("xxxxx");s1.swap(s2);cout << s1 << endl;cout << s2 << endl;swap(s1, s2);cout << s1 << endl;cout << s2 << endl;}
这段程序中的两个swap函数调用有以下区别:
std::string::swap是std::string类的成员函数,它直接在两个字符串对象之间交换数据,通常是通过交换内部指针来实现的,所以它的效率非常高,几乎是常数时间复杂度。
std::swap是标准库提供的一个模板函数,它可以用于交换任何类型的两个对象。对于std::string类型,std::swap内部实际上也是调用的std::string::swap,所以效率也是很高的。
总的来说,这两种方法在效率上是相当的,你可以根据实际情况和编程风格来选择使用哪一种。如果代码只涉及到字符串交换,那么使用std::string::swap可能会更直观一些;如果代码需要处理多种类型的交换,那么使用std::swap可能会更通用一些。
七、C风格 c_str
int main(){string s1("hello world");cout << s1 << endl;cout << s1.c_str() << endl;return 0;}cout << s1 << endl;:这行代码将字符串对象s1直接输出到标准输出流cout中。它会输出s1的内容,即字符串 "hello world"。
cout << s1.c_str() << endl;:这行代码使用了字符串对象s1的c_str()成员函数。c_str()函数返回一个指向以空字符结尾的字符数组(C风格字符串)的指针。然后,该指针被传递给cout输出流进行输出。它也会输出s1的内容,即字符串 "hello world"。
区别在于输出的方式不同。第一行直接输出字符串对象s1的内容,而第二行使用了c_str()函数将字符串对象转换为C风格字符串后输出。通常情况下,直接输出字符串对象更为简洁和方便。
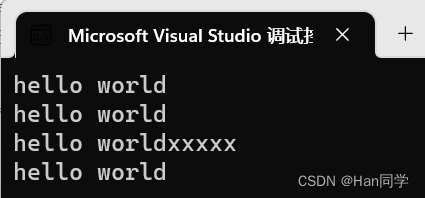
int main(){string s1("hello world"); cout << s1 << endl;cout << s1.c_str() << endl;s1 += '\0';s1 += '\0';s1 += "xxxxx";cout << s1 << endl;cout << s1.c_str() << endl;return 0;}可以看到,通过对s1进行修改操作后,输出结果中的空字符('\0')在字符串对象s1的输出中仍然存在,但在c_str()函数返回的C风格字符串中被忽略了。这是因为c_str()函数会将字符串以空字符结尾,而在输出时遇到空字符就会停止输出。
我们逐步解释为什么输出结果会有所不同。
初始状态下,s1的值为"hello world"。
cout << s1 << endl;:输出s1的内容,即字符串 "hello world"。
cout << s1.c_str() << endl;:输出s1的C风格字符串表示,即 "hello world"。
s1 += '\0';:在s1末尾添加一个空字符('\0'),此时s1的值变为 "hello world\0"。
s1 += '\0';:再次在s1末尾添加一个空字符('\0'),此时s1的值变为 "hello world\0\0"。
s1 += "xxxxx";:将字符串 "xxxxx" 追加到s1的末尾,此时s1的值变为 "hello world\0\0xxxxx"。
cout << s1 << endl;:输出s1的内容,即 "hello world\0\0xxxxx"。
cout << s1.c_str() << endl;:输出s1的C风格字符串表示,即 "hello world"。这里需要注意,c_str()函数返回的是以空字符结尾的字符数组,输出时遇到第一个空字符就会停止输出。
八、rfind&substr
rfind函数用于在一个字符串中从后往前搜索指定的子字符串,并返回子字符串的位置。
它的语法如下:
size_t rfind(const string& str, size_t pos = string::npos) const;str是要搜索的子字符串,pos是搜索的起始位置,默认为string::npos,表示从字符串的末尾开始搜索。
substr函数用于从一个字符串中提取子字符串。它的语法如下:
string substr(size_t pos = 0, size_t len = string::npos) const;其中,pos是要提取的子字符串的起始位置,默认为0,len是要提取的子字符串的长度,默认为string::npos,表示提取从起始位置到字符串末尾的所有字符。
接下来看下面代码:
int main(){string file("string.cpp.tar.zip");size_t pos = file.rfind('.');if (pos != string::npos){string suffix = file.substr(pos);cout << suffix << endl;}return 0;}
这段代码的目的是提取文件名中的后缀名。
首先,定义了一个字符串file,其中包含了一个文件名string.cpp.tar.zip。然后,使用rfind函数从后往前搜索.字符的位置,并将结果保存在变量pos中。如果找到了.字符,则pos的值不等于string::npos。接下来,通过判断pos的值是否不等于string::npos,来确定是否找到了.字符。如果找到了,则使用substr函数从pos位置开始提取子字符串,并将结果保存在变量suffix中。最后,将提取到的后缀名输出到标准输出流cout中,然后换行。 在这个例子中,输出结果为.zip,因为.字符后面的部分就是文件的后缀名。
从URL中提取主机地址:
int main(){string url("http://www.cplusplus.com/reference/string/string/find/");cout << url << endl;size_t start = url.find("://");if (start == string::npos){cout << "invalid url" << endl;}start += 3;size_t finish = url.find('/', start);string address = url.substr(start, finish - start);cout << address << endl;return 0;}
使用find函数搜索字符串url中第一次出现的子字符串"://"的位置,并将结果保存在变量start中。如果找不到该子字符串,则start的值等于string::npos。
接下来,通过判断start的值是否等于string::npos,来确定是否找到了"://"子字符串。如果没有找到,则输出"invalid url",表示URL无效。
如果找到了"://"子字符串,则将start的值增加3,以跳过"://"部分,然后使用find函数搜索从start位置开始的下一个'/'字符的位置,并将结果保存在变量finish中。
最后,使用substr函数从start位置开始,提取从start到finish之间的子字符串,并将结果保存在变量address中,将提取到的主机地址输出到标准输出流cout中,然后换行。







