web相关概念回顾
软件架构
C/S:客户端/服务器端B/S:浏览器/服务器端资源分类
静态资源:所有用户访问后,得到的结果是一样的,成为静态资源。
*静态资源可以直接被浏览器解析
如:html,css,JavaScript
动态资源:每个用户访问相同资源后,得到的结果可能不一样。成为动态资源
*动态资源被访问后,需要先转换成静态资源,再返回给浏览器
如:servlet/jsp,php,asp…
网络通信三要素
IP:电子设备(计算机)在网络中的唯一标识端口:应用程序在计算机中的唯一标识。0~65536传输协议:规定了数据传输的规则 基础协议: tcp:安全协议,三次握手。速度稍慢udp:不安全协议。速度快web服务器软件
服务器:安装了服务器软件的计算机
服务器软件:接收用户的请求,处理请求,做出响应
web服务器软件:接收用户的请求,处理请求,做出响应
在web服务器软件中,可以部署web项目,让用户通过浏览器来访问这些项目web容器常见的java相关的web服务器软件:
webLogic:oracle公司,大型的JavaEE服务器,支持所有的JavaEE规范,收费的webSphere:IBM公司的,大型的JavaEE服务器,支持所有的JavaEE规范,收费的JBOSS:JBOSS公司的,大型的JavaEE服务器,支持所有的JavaEE规范,收费的Tomcat:Apache基金组织,中小型的JavaEE服务器,仅仅支持少量的JavaEE规范,servlet/jsp。开源的,免费的JavaEE:Java语言在企业级开发中使用的技术规范的总和,一共规定了13项大的规范
Tomcat:web服务器软件
下载
安装:解压压缩包
注意:安装目录建议不要有中文和空格
卸载:删除目录
启动:
bin/startup.bat,双击运行该文件即可
访问:浏览器输入:
http://localhost:8080 回车访问自己http://别人的ip:8080 访问别人可能遇到的问题:
黑窗口一闪而过:
原因:没有正确配置JAVA_HOME环境变量解决方案:正确配置JAVA_HOME环境变量启动报错:
暴力:找到占用的端口号,并且找到对应的进程,杀死该进程
*netstat -ano
温柔:修改自身的端口号
*conf/server.xml
*<Connector port = “8888” protocol = “HTTP/1.1”
connectionTimeout = “20000”
redirectPort = “8445” />
*一般会将tomcat的默认端口号修改为80。80端口号是http协议的默认端口号
*好处:在访问时,就不用输入端口号
关闭
正常关闭:
*bin/shutdown.bat
*ctrl+c
强制关闭
*点击启动窗口的×
配置
部署项目的方式:
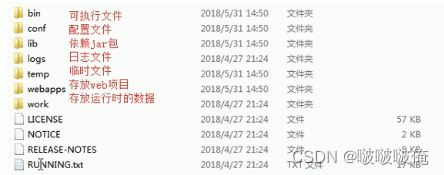
直接将项目放到webapps目录下即可
/hello:项目的访问路径–>虚拟目录
简化部署:将项目打成一个war包,再将war包放置到webapps目录下
war包会自动解压缩配置conf/server.xml文件
在标签中配置
*docBase:项目存放的路径
*path:虚拟目录
在conf\Catalina\localhost创建任意名称的xml文件。在文件中编写
*虚拟目录:xml文件的名称
动态和静态项目:
目录结构 java动态项目: –项目名称 –WEB–INF web.xml:该项目的核心配置文件classes目录:放置字节码文件lib目录:放置项目依赖的jar包将Tomcat集成到IDEA中,并且创建JavaEE的项目,部署项目
XML
概念:Extensible Markup Language 可扩展标记语言
可拓展:标签都是自定义的。
功能
存储数据 配置文件在网络中传输xml与html的区别
xml标签都是自定义的,html标签是预定义xml的语法严格,html语法松散xml是存储数据的,html是展示数据w3c:万维网联盟
语法:
基本语法
xml文档的后缀名 .xml
xml第一行必须定义为文档声明
xml文档中有且仅有一个根标签
属性值必须使用引号(单双都可)引起来
标签必须正确关闭
xml标签名称区分大小写
快速入门:
<?xml version = '1.0'?>
zhangsan
23
male
lisi
24
female
快速入门
组成部分
文档声明
格式:<?xml 属性列表 ?>
属性列表:
version:版本号,必须的属性
encoding:编码方式。告知解析引擎当前文本使用的字符集,默认值:ISO-8859-1
standalone:是否独立
yes:不依赖其他文件
no:依赖其他文件
指令(了解):结合css的
*<?xml-stylesheet type = "text/css" href = "a.css"?>
标签:标签名称自定义的
规则: 名称可以包含字母、数字以及其他的字符名称不能以数字或者标点符号开始名称不能以字母xml(或者XML、Xml等等)开始名称不能包含空格属性:
id属性值唯一
文本
CDATA区:在该区域中的数据会被原样展示
格式:<![CDATA[ 数据 ]]>
*约束:规定xml文档的书写规则
作为框架的使用者(程序员)
能够在xml中引入约束文档
能够简单的读懂约束文档
分类:
DTD:一种简单的约束技术Schema:一种复杂的约束技术DTD:
引入dtd文档到xml文档中
内部dtd:将约束规则定义在xml文档中
外部dtd:将约束的规则定义在外部的dtd文件中
*本地:
*网络:
Schema:
引入:
填写xml文档的根元素引入xsi前缀 xmlns:xsi = “http://www.w3.org/2001/XMLSchema-instance” 引入xsd文件命名空间 xsi:schemaLocation = “http://www.itcast.cn/xml student.xsd” 为每一个xsd约束声明一个前缀,作为标识 xmls = “http://www.itcast.cn/xml”<Students xmlns:xsi = “http://www.w3.org/2001/XMLSchema-instance”>
xmlns = “http://www.itcast.cn/xml”
xsi:schemaLocation = “http://www.itcast.cn/xml student.xsd”
解析:操作xml文档,将文档中的数据读取到内存中
操作xml文档
解析(读取):将文档中的数据读取到内存中写入:将内存中的数据保存到xml文档中。持久化的存储解析xml的方式
DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树 优点:操作方便,可以对文档进行CRUD的所有操作缺点:占内存 SAX:逐行读取,基于事件驱动的 优点:不占内存缺点:只能读取,不能增删改xml常见的解析器:
JAXP:sun公司提供的解析器,支持dom和sax两种思想DOM4J:一款非常优秀的解析器Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。PULL:Android操作系统内置的解析器,sax方式的Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
快速入门
步骤 导入jar包获取Document对象获取对应的标签Element获取数据代码:
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource(“student.xml”).getPath();
//2.2解析xml文档,加载文档进内存,获取dom树---->Document
Document document = Jsoup.parse(new File(path),“utf-8”);
//3.获取元素对象 Element
Elements elements = document.getElementsByTag(“name”);
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = element.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
对象的使用
Jsoup:工具类,可以解析html或xml文档,返回Document
parse:解析html或xml文档,返回Document parse(File in,String charsetName):解析xml或html文件的parse(String html):解析xml或html字符串parse(URL url,int timeoutMillis):通过网络路径获取指定的html或xml的文档对象Document:文档对象。代表内存中的dom树
获取Element对象 getElementById(String id):根据id属性值获取唯一的element对象getElementsByTag(String tagName):根据标签名称获取元素对象集合getElementsByAttribute(String key):根据属性名称获取元素对象集合getElementsByAttributeValue(String key,String value):根据对应的属性名和属性值获取元素对象集合Elements:元素Element对象的集合。可以当作ArrayList来使用
Element:元素对象
获取子元素对象
getElementById(String id):根据id属性值获取唯一的element对象getElementsByTag(String tagName):根据标签名称获取元素对象集合getElementsByAttribute(String key):根据属性名称获取元素对象集合getElementsByAttributeValue(String key,String value):根据对应的属性名和属性值获取元素对象集合获取属性值
String attr(String key):根据属性名称获取属性值
获取文本内容
String text():获取所有子标签的纯文本内容
String html():获取标签体的所有内容(包括子标签的标签和文本内容)
Node:节点对象
是Document和Element的父类