Python+Django+Mysql开发个性化电影推荐系统 movielens数据集 基于机器学习/深度学习/人工智能 基于用户的协同过滤推荐算法 爬虫 可视化数据分析MovielensRecommendSysPy
一、项目简介
1、开发工具和使用技术
Python,Django,mysql8,navicat数据库管理工具,html页面,javascript脚本,jquery脚本,bootstrap前端框架,layer弹窗组件、echarts可视化组件等。
2、实现功能
前台首页地址:http://127.0.0.1:8000/
后台首页地址:http://127.0.0.1:8000/admin
管理员账号:admin 管理员密码:admin
前台用户包含:注册、登录、注销、喜好标签、浏览电影、搜索电影、信息修改、密码修改、电影评分、电影收藏、电影评论、排行榜、热点推荐、个性化推荐电影等功能;
后台管理员包含:数据分析、用户管理、电影管理、电影类型管理、用户喜好标签管理、评分管理、收藏管理、评论管理、浏览记录管理等。
个性化推荐功能:
游客:热点推荐(根据电影总评分降序推荐);
登录用户:基于用户的协同过滤推荐算法(根据评分数据),如果没有推荐结果,采用标签推荐(推荐登录用户喜好标签下的总评分较高的电影,同时是登录用户没有评分的)。
人气榜单:查询浏览数量最多的电影,同时不包括当前登录用户浏览过的电影。
相关推荐:
推荐与当前电影相同类型下收藏量较高的电影,同时不包括当前登录用户收藏过的电影。
电影数据来源:
系统采用由grouplens项目组从美国著名电影网站movielens整理的ml-latest-small数据集,该数据集包含了671个用户对9000多部电影的10万条评分数据
ml-latest-small数据集是由grouplens项目组从美国著名电影网站movielens整理的
该数据集包含:
movies.csv文件:9742个电影数据,包括电影id、电影名称、电影类型
links.csv文件:包含了电影id在imdb电影网站与tmdb电影网站的id,即:movieid是当前数据集中的电影的id,imdbid是电影在imdb网站中的id,tmdbid是电影在tmdb网站中的id
ratings.csv文件:包含了671个用户对电影的100836个评分数据
movies_all.csv文件:是爬虫根据电影imdbid从imdb网站爬取的电影的其他信息,包括:
导演、编剧、演员、电影图片、电影时长、语言、区域、简介等
保存了9738个电影数据
将ml-latest-small数据集保存在数据库中的过程:
1、爬虫读取movies.csv和links.csv文件,并通过电影的imdbid到imdb网站爬取电影数据(包括图片、导演、演员等信息),同时将电影图片下载在电脑中,数据库中只保存电影图片的名称
2、将爬取的数据保存在movies_all.csv文件中
3、解析movies_all.csv,将电影类型数据保存在电影类型表中,将电影数据保存在电影表中,将电影-电影类型关联数据,保存在关联表中
4、解析ratings.csv文件,将用户id保存在用户表中,将评分数据保存在评分表中
5、因为数据集中只有用户id数据,所以用户表中也只有用户id,因此需要添加用户的用户名、密码等信息
6、添加用户标签数据
3、开发步骤
一、需求分析
主要是分析需要实现的功能、确定开发工具及技术等。例如:前台用户需要有登录、注册、注销、搜索电影、电影评分、个性化推荐等,后台管理员需要有登录、注销、用户管理、电影管理、电影类型管理等,个性化推荐使用基于用户的协同过滤推荐算法等。Python开发语言,mysql数据库,django开发框架等。
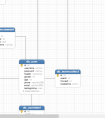
二、数据库设计
数据库设计使用navicat数据库管理工具,可通过sql语句脚本生成数据库表,也可以直接操作新建表设计表等。注意主外键关联设计,例如:评分记录表需要外键关联用户表和电影表。
三、页面设计
使用bootstrap前端框架,通过学习https://v5.bootcss.com/官方文档和开发案例来设计页面。
四、开发框架搭建
Django开发框架搭建请参考:使用pycharm创建django项目讲解.doc
五、功能开发
首先是进行前台用户首页的开发,其次是电影详情,然后是用户注册、登录等,接着是用户的评分、修改信息等,然后是进行管理员功能的开发,最后是进行前台用户的个性化推荐功能实现。
六、系统测试
主要是进行bug修改,推荐算法测试。
二、项目展示





























三、代码展示及运行结果