近日,上海人工智能实验室(上海AI实验室)发布新一代高质量大模型预训练语料“WanJuan 2.0”(WanJuan-CC)(下文简称WanJuan-CC),首批开源的语料覆盖过去十年互联网上的公开内容,包含1千亿字符(100B token),约400GB的高质量英文数据。作为“大模型语料数据联盟”今年首发的开源语料,WanJuan-CC将为学界和业界提供大规模、高质量的数据支撑,助力构建更智能可靠的AI大模型。
预训练数据的质量对大模型整体性能至关重要。当前,CommonCrawl(CC)数据集因其规模大、跨度广而成为国际主流大模型训练数据的重要来源。与此同时,其原始数据格式复杂、数据质量低等问题,或将导致模型训练效率低,甚至可能引发价值观对齐等方面的隐患。
中国科研人员通过原创的数据清洗技术,从CC数据库中抽取约1300亿份原始数据文档进行再处理,“萃取”出其中约1.38%的高质量内容,构建成WanJuan-CC语料库。实验结果显示,WanJuanCC具有高文本质量、高信息密度的特点,可满足当前大模型训练对大规模高质量语料的需求。
上海AI实验室发布的书⽣·浦语2.0(InternLM2)即以WanJuan-CC为关键数据作支撑,使训练效率和语言建模能力大幅提升,综合性能领先开源社区。
开源数据:https://opendatalab.com/OpenDataLab/WanJuanCC
高质量语料驱动,效率性能双提升
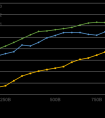
近期,上海AI实验室发布了新一代大语言模型书⽣·浦语2.0(InternLM2)。回归语言建模本质,InternLM2综合性能达到同量级开源模型的领先水平。模型基座语言建模能力的提升,则得益于预训练文本质量及信息密度的增强。
作为InternLM2的关键预训练语料,WanJuan-CC的文本质量和高信息密度经过了模型实际验证。在InternLM2的训练过程中,在仅使用约60%的训练数据情况下,模型即获得了与此前使用1T token相同的性能表现,大幅提升训练效率,并使模型在相同语料规模上取得了更好的性能。
研究团队通过对CC原始数据进行清洗,去除了网页代码和重复内容,同时利用分类模型剔除了广告和质量较差的信息,并通过内容一致性、语法正确性、数据噪声和信息价值等四个维度,对语言的流畅性进行评估。
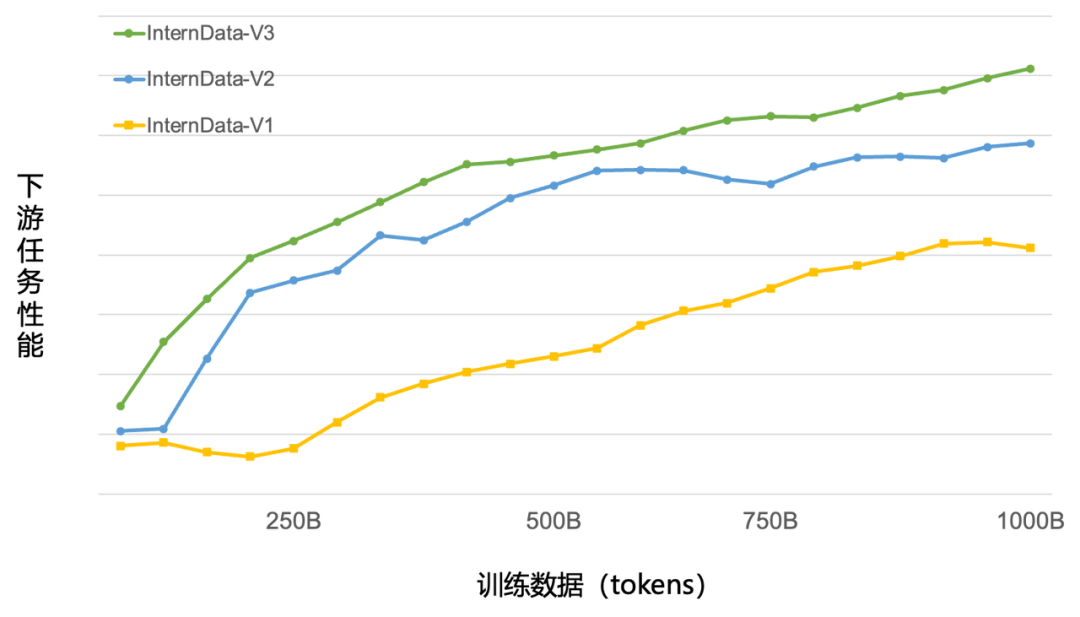
为验证数据质量,研究团队使用WanJuan-CC和RefineWeb(从CommonCrawl中抽取并构建的主流英文预训练语料)分别重新训练了参数量1B的模型,并进行评测。
结果显示,由WanJuan-CC作为训练数据的模型在多项验证中取得了更优效果。
四重处理, 百里挑一“萃取”高质量数据
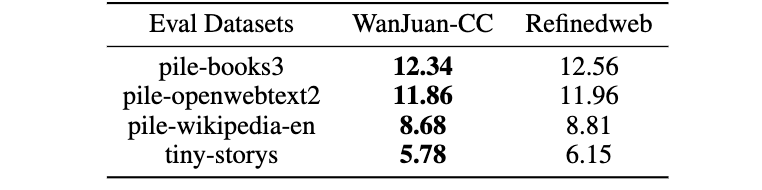
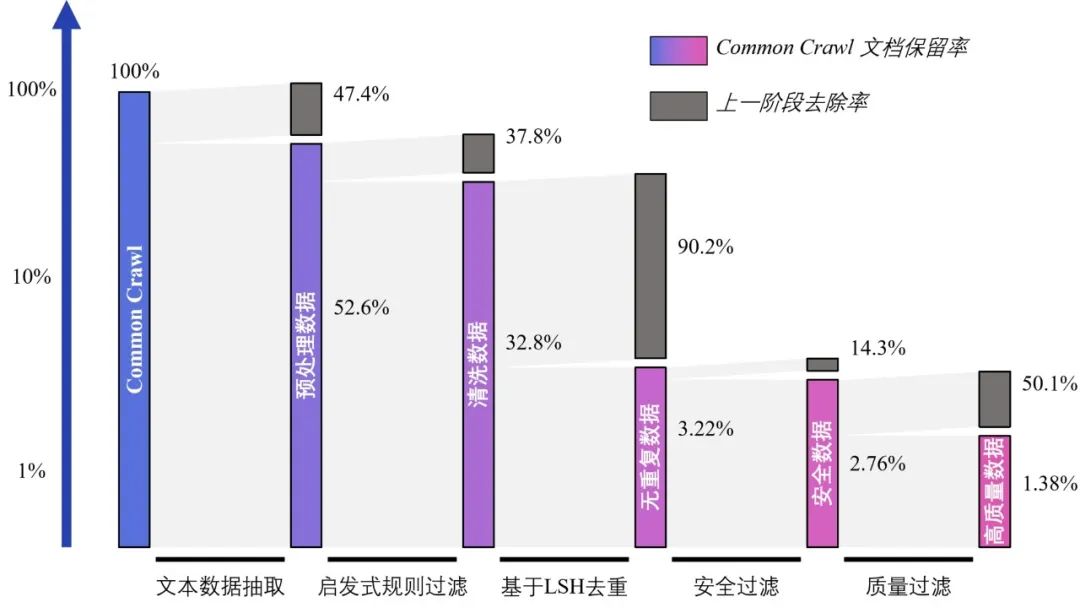
为从浩如烟海的CC数据库中“精选”最可靠的信息,研究团队搭建了高性能分布式数据处理基础设施,通过启发式规则过滤、多层级数据去重、内容安全过滤、数据质量过滤等四个步骤,从原始数据中“萃取”出高质量数据,数据留存率仅为原数据的1.38%。
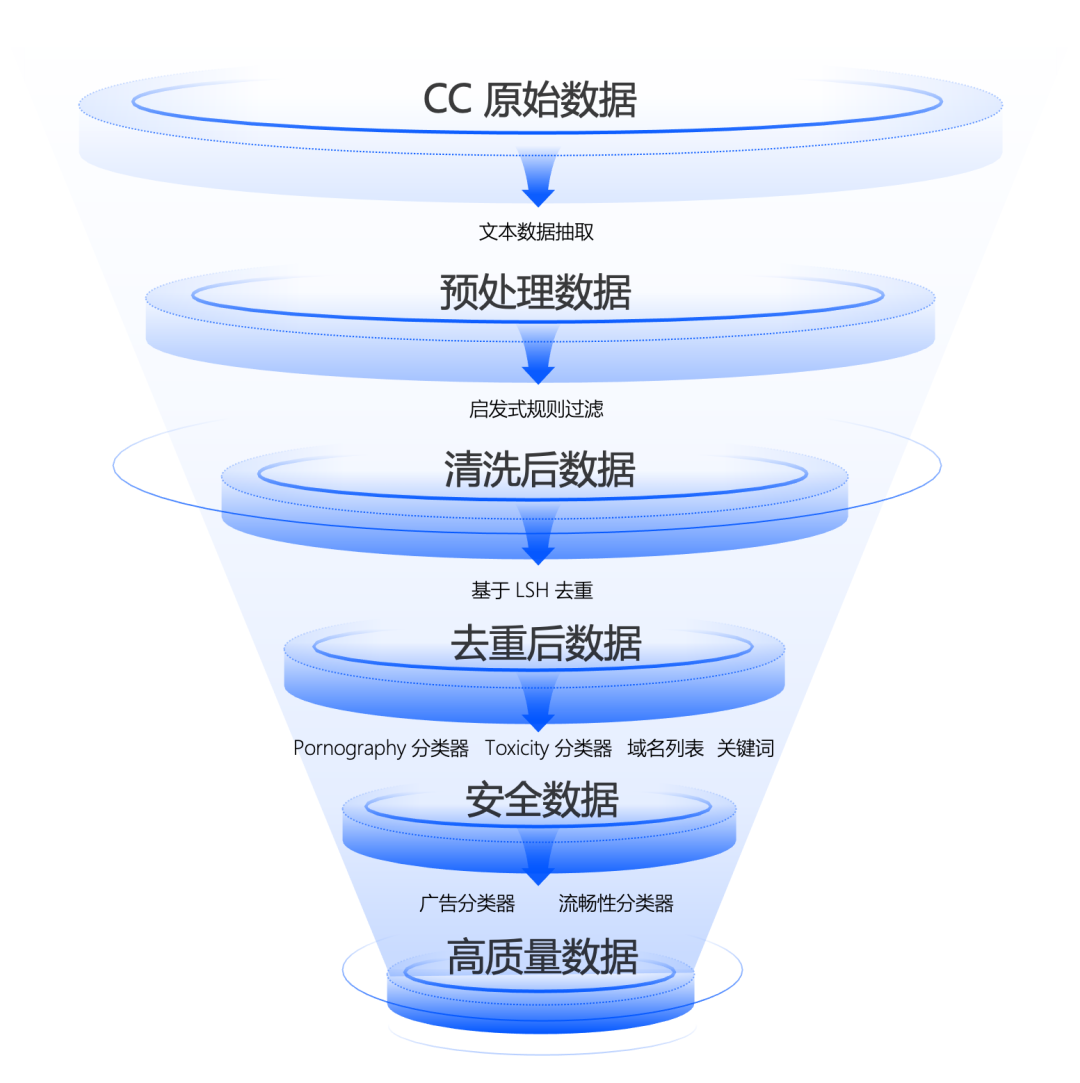
研究团队首先从CC中抽取了约1300亿份原始数据文档,然后基于高性能数据处理工作流得到2.2T token(35.8亿个文档)安全数据,最后,根据质量排序精选出1T token(3.6亿个文档)质量最高的数据,构建成WanJuan-CC。
如以下柱状图所示,在WanJuan-CC构建过程中的每一阶段,均进行了大比例的数据去除。对于仅占原CC数据比例2.76%的安全信息,研究人员再次“筛”掉五成低质内容,最终呈现出“百里挑一”的高质量数据。
数据质量高,模型更可靠
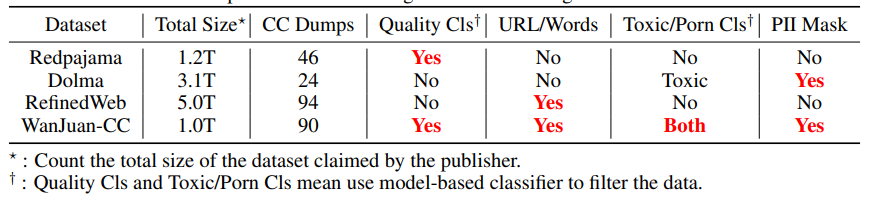
为推动训练更智能可靠的AI大模型,研究团队以保障数据安全性为前提,在数据处理的各环节均实施了多项安全加固措施,使WanJuan-CC成为目前开源CC语料中首个在毒性(Toxic)、色情(Porn)和个人隐私三方面同时进行了安全加固的英文语料,因而在价值对齐方面具有更高的可靠性。
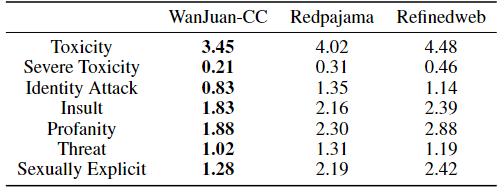
研究人员分别对WanJuan-CC、Redpajama和Refineweb数据集进行了10万条数据的抽样,从毒性、侮辱、恐吓等7个维度进行评分,以验证各数据集的信息安全性。结果显示,WanJuan-CC在各维度上的体现出最高安全性。
高质量、多模态、宽领域的数据已成为支持当前人工智能大模型发展的重要基石。WanJuan-CC的主要构建团队——OpenDataLab致力于建设面向人工智能开发者的超大规模、高质量、多模态开放数据服务平台,目前已汇聚高质量多模态数据集超6500个,涵盖大模型研发应用所需的各类语料数据。
大模型语料数据联盟
由上海人工智能实验室联合中央广播电视总台、人民网、国家气象中心、中国科学技术信息研究所、上海报业集团、上海文广集团等10家单位联合发起。为应对大模型发展对高质量、大规模、安全可信语料数据资源的需求,保障大模型科研攻关及相关产业生态发展,大模型语料数据联盟于2023年7月6日世界人工智能大会开幕式上宣布成立,旨在通过链接模型训练、数据供给、学术研究、第三方服务等多方面机构,联合打造多知识、多模态、标准化的高质量语料数据,探索形成基于贡献、可持续运行的激励机制,打造国际化、开放型的大模型语料数据生态圈。
WanJuan-CC数据集下载:https://opendatalab.org.cn/OpenDataLab/WanJuanCC
下载更多开源语料,请登录大模型语料数据联盟开源数据服务指定平台:https://opendatalab.org.cn