置顶先贴上论文和代码的地址和链接,pointnet和pointnet++简直就是点云深度学习界的resnet呀,经典永流传。
pointnet++论文:1706.02413v1.pdf (arxiv.org) https://arxiv.org/pdf/1706.02413v1.pdf
https://arxiv.org/pdf/1706.02413v1.pdf
pointnet++代码:yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS. (github.com)https://github.com/yanx27/Pointnet_Pointnet2_pytorch
本博文将结合论文和代码来详细地分析pointnet++网络,包括最远点采样方法,网络结构等。
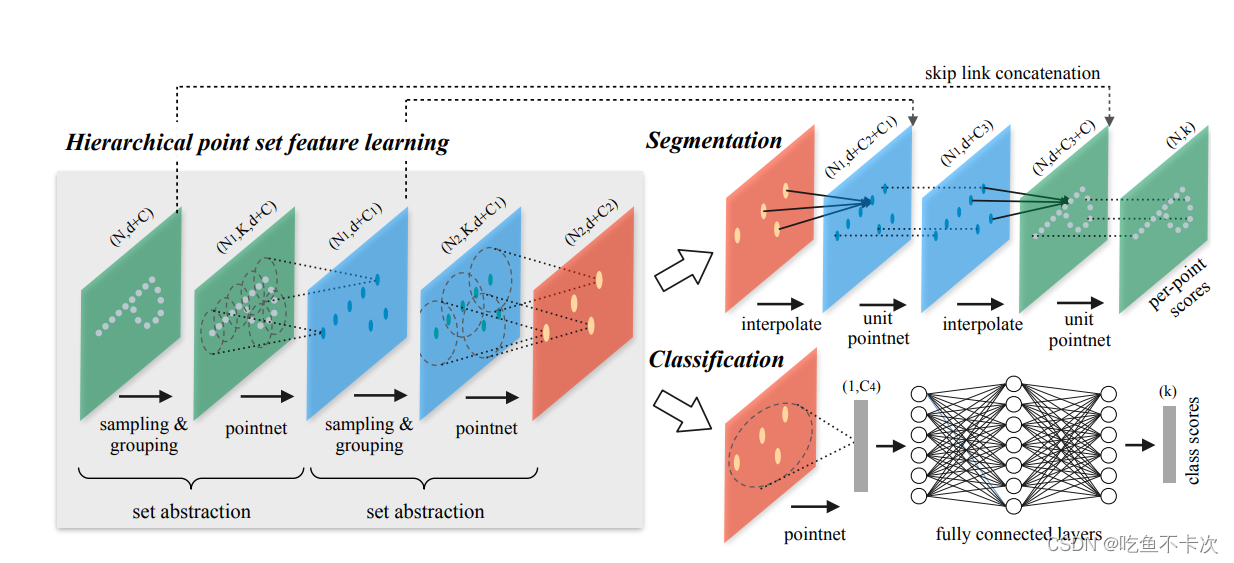
1.Pointnet++网络结构
1.1网络基本结构
如下图所示,Segmentation为分割网络结构,Classification为分类网络结构。主干网络由n个set abstraction(SA模块)构成,N表示点数,d表示维度,其中输入维度一般为xyz三维,或者xyzrgb等六维,分割网络和2D的分割网络一样,会有一个上采样过程,恢复到输入的N个点,并对n个点分别进行预测类别;而分类网络直接通过全连接网络输出整个点云的类别。
1.2 项目基本结构
data:存放数据的路径,详细可见下面这篇博客,有对几种任务的公共数据集的粗略解释,以及数据下载链接。Win10系统下复现Pointnet++(pytorch)_吃鱼不卡次的博客-CSDN博客
data_utils:ModelNet、ShapeNet及S3DIS数据集的dataset组织形式,主要是对数据进行处理的,均含有__getitem__(self, index),__len__(self) 两个方法,getitem一般是用来返回数据和标签的,len返回数据的长度。

log:用来记录训练的流程。
models:定义了pointnet及pointnet++的网络结构。

Visualizer:用来可视化的代码,我一般使用CloudCompare来进行可视化,不用open3d这些库来可视化,因为感觉不方便。

最后是训练和测试的脚本,如下所示。

2.PointNet++分割网络
pointnet++中包含有部件分割网络和语义分割网络,(部件分割在预测的时候需要知道大类的类别,然后再对大类中的小类别进行分类,如果预测结果中包含小类别外的类别,需要另外进行剔除并替换为小类别中的第一个类别,这一点我觉得很奇怪,所以就不使用部件分割,而使用语义分割了)直接来介绍语义分割网络:首先是SA模块,包含了Sampling,Grouping及Pointnet三部分,其中Sampling代表采样,是指从输入的点中使用最远点采样方法(Farthest Point Sampling,FPS)采样n个点(下图1),Grouping表示以采样的n个点为中心,聚合半径r内的点(下图2),Pointnet是指将聚合的点的特征采用MLP及maxpooling操作提取特征。
这里再解释一下下图,对于1中选取的每个中心点,都会进行一次Grouping,每一个Grouping都会送到Pointnet网络中提取特征,所以2和3中会并行Grouping和Pointnet,直观上可以这么理解,代码上对张量进行批量化操作也是一样的道理。
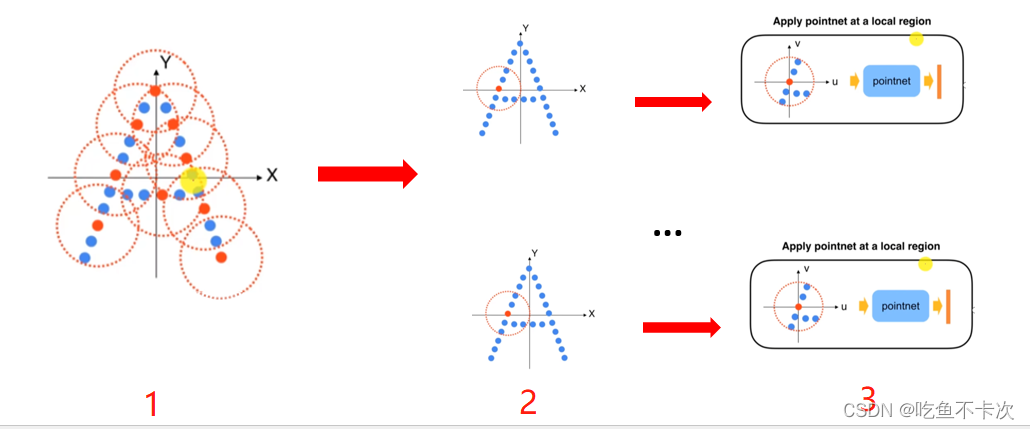
2.1最远点采样(FPS)
顾名思义,假设有一个点的集合{A1,A2,A3...An}就是选取距离彼此最远的k个点,取两个最远点好选取,那么选取k个最远点如何选取呢,通过以下例子来说明最远点采样方法:
假设有7个点P0—P6,首先初始化第一个点为P0,则距离P0的最远点为P6,得到最远点的点集为{P0,P6};
其次第三个点选取步骤:先取最小值,再取最大值,至于为什么可以反过来想,如果我先取最大值,那么我可能选取的这个最大值可能离A远,但是离B近呀,这样就没办法保证我取得的是最远点了。(其实这里我也思考了很久才慢慢思考明白,这个最远点采样方法的思想和豪斯多夫距离(Hausdorff distance )是一样的)。
(1)P1/P2/P3/P4/P5到P0和P6的最小值: P1—>(P0,P6)的距离min(L10,L16) L10 P2—>(P0,P6)的距离min(L20,L26) L20 P3—>(P0,P6)的距离min(L30,L36) L30 P4—>(P0,P6)的距离min(L40,L46) L40 P5—>(P0,P6)的距离min(L50,L56) L50(2)选取最短距离的最大值: max(L10,L20,L30,L40,L50)=L50(3)则第三个点为P5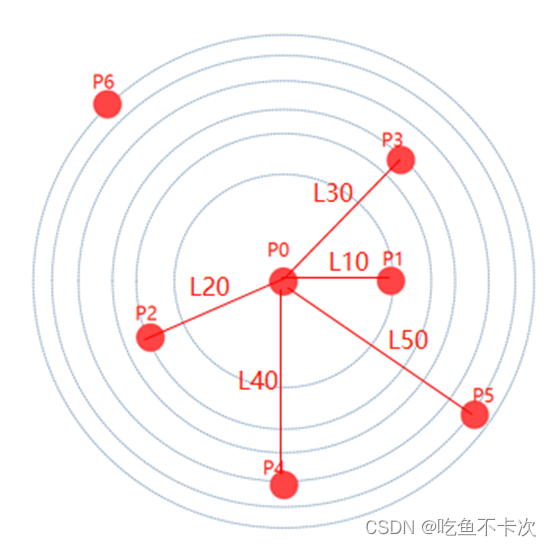
最后重复第二个步骤,直到选取完k个点。代码详见\models\pointnet2_utils.py中的farthest_point_sample(xyz, npoint)方法,上面方法是基于torch写的。
2.2Grouping
Sampling和Grouping这两个操作一般是放在一起进行操作的,从数据的shape中进行分析的话可以看下图:(1)Input:输入是xyz坐标数据(B,N,3),分别代表点云个数B,点个数N,坐标xyz;还有一个输入特征数据是对应的N个点的特征维度D;(2)Sampling:通过最远点采样方法从N个点中选取npoints个点作为中心点,坐标数据变为(B,npoint,3);(3)Grouping:通过Sampling采样得到的npoint个中心点,首先对其每个中心点使用球搜索(会有一个内参r表示球搜索半径)检索出距离中心点最近的nsample个点,如果r范围内的点不足nsample个会用距离中心点的坐标进行补齐;然后通过球搜索检索得到的点来找到对应的特征数据,得到Grouping的特征数据,shape为(B,npoint,nsample,D);最后还需要将坐标数据和特征数据进行拼接,将得到shape为(B,npoint,nsample,D+3)的数据。
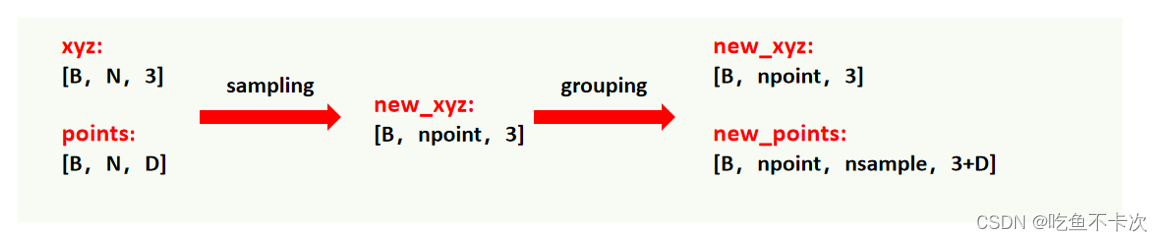
稍微总结下,Grouping就是把Sample得到的点作为中心点,然后检索半径范围内的点,将数据从3维变成4维,保留了局部点云的特征。
2.3PointNet
还是从数据的shape大小角度来分析PointNet这一模块做的工作:(1)首先会将维度进行交换,两个问题:第一,为什么要进行交换?是为了后面可以进行Conv2D卷积;第二,为什么要使用Conv2D卷积,而不使用Conv1D卷积?因为数据是4维的方便进行Conv2D,虽然是Conv2d卷积,但是其卷积核大小也是1X1的;C+D作为第二个维度的大小,可以看成2维卷积的通道数,而后面两维(nsample,npoint)可以看成是特征图的宽高大小;(2)然后经过卷积得到shape为(B,64,nsample,npoint),可以看到卷积只改变了通道数大小,而没有改变特征图大小;(3)最后对卷积后的特征图在最后一维取最大值,shape变为(B,64,npoint),这一步的作用可以看成是为了得到每个球形区域中最明显最大的点。
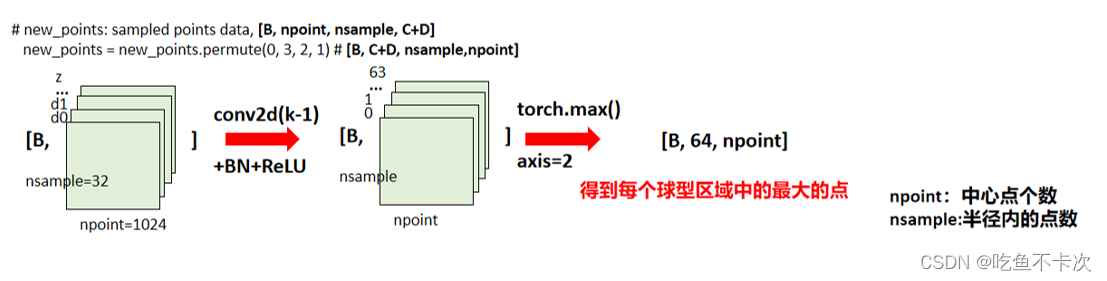
轻微总结下,PointNet这一模块主要是通过卷积提取Sampling+Grouping得到的点的特征,并且将特征数据从4维又变成了3维。
3.PointNet++分类网络
很快就补充好。