文章目录
推理转换onnx网络架构SPP VS SPPFAutoAnchorLoss 参考【YOLO系列】YOLO v3(网络结构图+代码)
【YOLO 系列】YOLO v4-v5先验知识
【YOLO系列】YOLO v4(网络结构图+代码)
我是在自己笔记本上配置的YOLO v5环境。首先,conda创建YOLO v5虚拟环境,克隆
ultralytics/yolov5项目,pip install -r requirements.txt安装所需库文件。
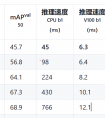
YOLO v5提供了五个不同大小的预训练模型,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。这五个模型的参数量、mAP和推理速度如下所示:

这五个模型的网络结构是一样的,不一样的就是通道数和宽度不一样,受depth_multiple和width_multiple两个因子影响。
| 模型 | depth multiple | width multiple |
|---|---|---|
| YOLOv5n | 0.33 | 0.25 |
| YOLOv5s | 0.33 | 0.50 |
| YOLOv5m | 0.67 | 0.75 |
| YOLOv5l | 1.0 | 1.0 |
| YOLOv5x | 1.33 | 1.25 |
推理
我笔记本的CPU为Inter i7-7700HQ,使用detect.py进行推理。预训练权重选择yolov5x.pt,推理图像默认来自于"\data\images"文件夹下。推理命令行如下所示:
python detect.py --weights models/yolov5x.pt --device cpu --view-img
推理时,会输出每张图片前处理后的图片大小,检测结果和推理时间。官方给出的YOLOv5x在CPU上的推理时间为766ms,可能笔记本的CPU太弱了吧,这两张图片的推理时间在1.5s~2.0s之内。
image 1/2 F:\yolov5\data\images\bus.jpg: 640x480 4 persons, 1 bus, 1973.8ms
image 2/2 F:\yolov5\data\images\zidane.jpg: 384x640 3 persons, 2 ties, 1565.6ms
Speed: 0.5ms pre-process, 1769.7ms inference, 7.8ms NMS per image at shape (1, 3, 640, 640)
| bus图片推理结果展示 | zidane图片推理结果展示 |
|---|---|
 |  |
转换onnx
YOLO v5的模型配置是yaml文件,为了能直观地查看YOLO v5的网络结构,需要将预训练pt模型转换成onnx的格式。onnx的算子版本默认为17,这里设置算子版本为11。
python export.py --weights models/yolov5x.pt --device cpu --opset=11 --include onnx
然后使用生成的onnx文件进行推理,测试一下生成的onnx文件是否正确。
F:\yolov5>python detect.py --weights models/yolov5x.onnx --device cpu --view-img
网络架构
YOLO v5的网络结构也清晰地分为backbone、Neck和Head三部分。YOLO v5第一版于2020年6月发布,距今已有三年,这三年YOLO v5也从第一版已更新到第七版。在前四版时,对PAN和CSP都进行了更新。在第四版时,使用SiLU激活函数代替LeakyReLU和Hardswish激活函数。在第六版时,使用一个Conv(k=6, s=2, p=2) 卷积层替代Focus结构;使用SPPF替代SPP结构。还有一些其他更改,目的都是为了使得YOLO v5模型更轻量、更快和更准确。
自YOLO v5模型第六版之后,backbone、neck和Head的结构就如下所示了。
Backbone: New CSP-Darknet 53Neck: SPPF, New CSP-PANHead: YoLo v3 Head下图是YOLOv5l的网络架构,YOLO v5在Head时,使用C3结构替代YOLOv3和YOLOv4 head和neck的五层卷积。

SPP VS SPPF
| SPP | SPPF |
|---|---|
 |  |
SPPF比SPP的运行时间快2倍。SPP的三个最大池化层的size是不一样的,但是输入是一样的;SPPF的三个最大池化层的size是一样的,后续两个最大池化的输入是前一个最大池化层的输出。
AutoAnchor
在YOLO v5中,默认使用autoAnchor,不用手工选择anchor boxes,使用k-means聚类算法在训练集上自动寻找anchor boxes。训练时设置noautoanchor,才能使用自定义的anchor boxes。
parser.add_argument(‘–noautoanchor’, action=‘store_true’, help=‘disable AutoAnchor’)
autoAnchor在yaml配置文件中设置如下所示。其中3表示每个输出层分配3个anchor大小。
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
k-means是非常经典的聚类方法,通过计算样本之间的距离将相近的样本聚到同一类别。auto anchor的计算函数为utils/autoanchors.py文件的kmean_anchors。源代码有些长,我只截取了k-means计算auto anchor的核心部分和进化算法中的适应度计算。
def metric(k, wh): # compute metrics """ k: anchor框 wh: 整个数据集的 wh [N, 2] x: [N, 9] N个 gt boxes 与所有 anchor boxes的宽比或高比(两者之中较小者) x.max(1)[0]: [N] N个 gt boxes 与所有 anchor boxes中的最大宽比或高比(两者之中较小者) """ r = wh[:, None] / k[None] # 两者的重合程度越高,越趋近1 x = torch.min(r, 1 / r).min(2)[0] # ratio metric return x, x.max(1)[0] # x, best_xdef anchor_fitness(k): # mutation fitness #适应度计算 用于遗传算法中衡量突变是否有效的标注 优胜劣汰 _, best = metric(torch.tensor(k, dtype=torch.float32), wh) return (best * (best > thr).float()).mean() # fitness# 得到数据集中所有图像的whshapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True) # 将图片的长边缩放到img_size,相应地缩放短边wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # 将图片中gt boxes的wh缩放到shapes尺度。 dataset.labels其中格式为[类别,x, y , w, h],xywh均已经归一化了# Filteri = (wh0 < 3.0).any(1).sum() # 统计gt boxes中w和h小于3像素的个数if i: LOGGER.info(f'{PREFIX}WARNING ⚠️ Extremely small objects found: {i} of {len(wh0)} labels are <3 pixels in size')# 筛选大于2像素的gt boxes用作聚类wh = wh0[(wh0 >= 2.0).any(1)].astype(np.float32) # filter > 2 pixels# Kmeans inittry: LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...') assert n <= len(wh) # apply overdetermined constraint # 计算wh的标准差 s = wh.std(0) # sigmas for whitening # 聚类 k = kmeans(wh / s, n, iter=30)[0] * s # points assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similarexcept Exception: LOGGER.warning(f'{PREFIX}WARNING ⚠️ switching strategies from kmeans to random init') k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random initwh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))k = print_results(k, verbose=False)Loss
YOLO v5的loss也由三部分组成,Classes loss和Objectness loss都使用的是BCE loss,Location loss为CIoU loss。三个预测层的Objectness loss是有不同权重的,小中大分别是[4.0, 1.0, 0.4]。
YOLO v5更新了YOLO v3中已知偏移量 c x , c y , t w , t h c_{x},c_{y},t_{w},t_{h} cx,cy,tw,th计算预测bbox的公式,公式对比如下所示:
| YOLO v3 | YOLO v5 |
|---|---|
 |  |
更新公式之后,中心点偏移量的取值范围由 ( 0 , 1 ) \left( 0, 1\right) (0,1)调整到 ( − 0.5 , 1.5 ) \left( -0.5, 1.5\right) (−0.5,1.5),因此,偏移量更容易得到0或者1。在YOLO v3的box方程中,宽度和高度无上限,这是一个严重的缺陷,它可能会导致梯度失控、不稳定性、NaN loss等问题,并最终导致无效训练。
| 中心点对比 | 宽度和高度对比 |
|---|---|
 |  |