本文来源公众号“CVHub”,仅用于学术分享,侵权删,干货满满。
原文链接:AI标注神器 X-AnyLabeling-v2.3.0 发布!支持YOLOv8旋转目标检测、EdgeSAM、RTMO等热门模型!

今天主要为大家详细介绍 X-AnyLabeling v2.3.0 版本近期更新的一些功能和新特性,同时也借此机会分享下笔者本人在做这款开源工具的一些心路历程。
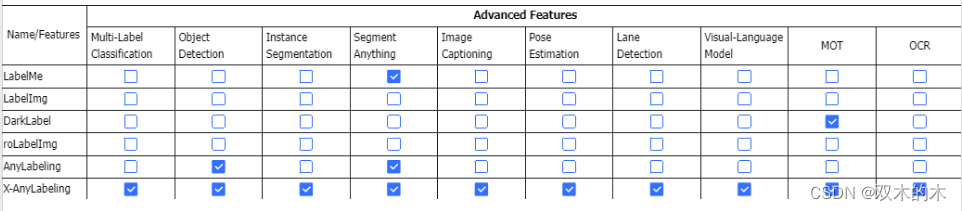
首先,提到图像标注软件,可能许多从事计算机视觉相关领域的研究人员及从业者脑海中第一印象便会想到由MIT开源的主流标注软件:LabelMe,又或者是LabelImg和CVAT等耳熟能详的主流标定软件。这里可能细心的读者会想,既然生态圈已经有了这么成熟的工具,那花这个精力重构和开发这样一款软件的意义是什么呢?
我的答案最早也是:Yes。在设计X-AnyLabeling之前,包括笔者本人我也是基本在通过上述几款主流工具来解决日常的业务需求。这最开始也跟笔者从事的岗位性质有关,作为一名算法工程师,可能大家都或多或少能体会到,其实工作时间大部分时间是在与数据打交道,算法一般考虑到硬件支持和稳定性等各方面因素很少调整;哪怕在ChatGPT以及AIGC发展如火如荼的今天,如何快速构建高质量的数据仍然是主旋律。在大多数场景下,数据的质量远比数量要来得重要,相信在一线的从业人员对这点会深有体会。这一点其实跟我们在学校做研究的方式不同;学术届更多地的是提出一个idea,然后在公认的数据集上刷榜,大多数时候都是在过拟合数据分布,往往也经受不住实际应用的推敲。
一开始,笔者的工作更多地是围绕在目标检测业务上,这其实用CVAT,甚至是LabelMe便已经能够应付了。后来,随着业务的多元化导致各类需求逐渐增多,但本质上还是围绕一个核心——数据,毕竟对于落地的算法其实更讲究的是稳定性,再有便是搭配一些上下游去做整体的逻辑应用,几乎很少会频繁的更换算法模型或者去尝试各种SOTA模型。为此,我们会面临几个问题:
数据的多样性
众所周知,不同的任务其对应的数据输出形式各有不同。举个例子:
对于多标签分类任务而言,我们需要应用到属性识别的功能,赋予每张图像多个不同的标签形式;
对于图像分割任务而言,我们需要能够提供精细化的掩码标签;
对于旋转目标检测而言,我们需要能提供带旋转角度的目标框;
对于文本识别任务而言,我们需要先检测出对应的文本框再进行相应地OCR;
对于多目标追踪任务而言,我们需要能够提供追踪特定目标ID的能力;
...
放在以往,大家可能更多地会针对特定的场景挑选合适的工具去完成相应地标定任务,例如:
通过LabelImg来标注矩形框;
通过LabelMe来进行多边形框的标定;
通过PPOCRLabel来完成文本识别标注任务;
通过roLabelImg来解决旋转目标检测的功能;
通过DarkLabel来完成视频文件的标注及对象的跟踪功能;
通过ELAN完成对视频序列中人物动作的识别以及对应字幕的捕捉;
...
可想而知,我们需要耗费更多地精力去完成这些工作,毕竟每一款工具都需有一定的学习使用成本,这是毋庸置疑的。
工具的易用性
针对第1点,有同学跟我交流过,说大可以使用由 Intel 公司开发的开源工具——CVAT;当然,不得不承认,CVAT工具是一款极其优秀的大型标定软件,毫不夸张地说,市面上几乎所有的标注行业相关公司开发的所谓内部或者云平台标注工具,都是基于此原型进行二次设计和开(包)发(装)的。然而,对于绝大多数用户而言,面对这样一款“庞然大物”,会遇到几个问题:
首先,上手成本相对较高,CVAT使用前需要经过繁琐的配置流程,同时对跨平台使用兼容性较差;
其次, 很多人其实面临的需求都是即时性的需求,更亟需的是一款绿色开源,开箱即用的工具;
最后,船大便意味着难调头,对于一些有特定业务需求的从业人员来说,改动源码进行高度定制化的难度可想而知;另外,其实CVAT支持的功能也是相当“有限”,同时也有很严重的“滞后性”。
因此,我们更多地是需要一款小巧方便,最好是能开箱即用,同时也支持高度定制化和提供丰富功能组件的标定工具。
功能的多样性
除了上述两点,我先前提到的最为关键的一点是,我们需要思考如何更高效、更快速地建立整个数据标定流程。我们有幸身处于这个人工智能大爆发的时代,当今涌现出了许多新技术,其中一些值得一提:
例如,Meta公司开源的SAM是一项令人振奋的技术,用户只需简单点击感兴趣的目标,即可快速、准确地获取精细的掩膜。另外,OpenAI公司也为我们带来了ChatGPT等创新技术,除了可以用人类自然对话的方式来获得逼真拟人化的互动,还可以用于甚为复杂的工具,如自动摘要提取、文本创作、代码编写等。最后,还有发展迅猛的多模态技术,可以帮助人们完成诸如文生成图、图生成文、图文-语音交互以及以文本或图像驱动(prompt-based)等创新应用。这些多模态技术的崛起不仅为各个领域的人工智能应用带来了更广泛的可能性,也推动了不同模态之间更深层次的融合。
为此,我们是不是可以考虑结合以上技术来构建更加强大、高效、快捷的标定流程呢?何乐而不为!以上便是笔者设计此款软件的初衷和动机,当然在整个开发、构建和维护过程中也遇到了许许多多的困难,这里也很难仅凭一两句话道出其中的辛酸,仅希望能与大家共勉。目前该工具也已完全开源,遵循 GPL 协议,感兴趣的小伙伴可以通过下方链接下载体验,顺手点一个Star给予支持:
项目链接:https://github.com/CVHub520/X-AnyLabeling/tree/main
1.X-AnyLabeling
总的来说,X-AnyLabeling从设计和开发之初便有了明确的目标和动机,即要创建一个既能满足多样性需求,又具备易用性,同时包含丰富功能且组件且支持高度定制化的图像标注软件。
值得一提的是,为了尽可能地减轻大家的使用成本,X-AnyLabeling 目前在设计交互的时候会尽可能地与主流标注工具(如LabelImg、Labelme、roLabelImg、Anylabeling以及CVAT等)保持对齐,最大限度提升用户的标注效率和使用体验。同时,目前该工具已基本涵盖了市面上所有主流工具的大部分功能,希望有朝一日能做到真正的 All in one!
好了,话不多说,下面简单为各位小伙伴介绍下最新 v2.3.0 版本相较于前两个版本引入的一些新特性:
添加标签背景高亮,提高辨识度的同时美化UI设计;
新增数据统计预览功能,可通过快捷键Ctrl+G快速查看当前任务的统计数据;
SAM 标注模式下新增一键清除当前prompt的快捷键(c)以及快速创建正样本点(q)和负样本点(e);
Rectangle对象绘制模式从原先的对角顶点模式扩展到四点标注模式,提升微调效率;
新增自动切换编辑模式,无需每次绘制完对象后进行手动切换,减少操作次数;
删除对象时无需按确认键,可加速标注流程;
支持一键导出灰度和彩色掩码图;
新增一键导入和导出多种标签选项,无需预定义设置;
支持隐藏/显示当前选中对象,可用于图层重叠无法调整底下对象的情况;
支持底部状态栏实时显示当前标注任务进度以及当前选中对象的宽高和鼠标点信息;
标签编辑栏新增Difficult复选框以及Description预览和编辑框,极大提升交互体验;
新增YOLOv8旋转目标检测、EdgeSAM、RTMDet、RTMO、车牌检测与识别等算法;
2亮点功能
2.1支持图像和视频导入功能
除了支持图像级的标注功能外,X-AnyLabeling还引入了对视频的全面支持,实现了一键解析和自动标注。为了更好地满足用户对视频文件标注的需求,当前集成了经典的ByteTrack和最新的OC-Sort(CVPR 2023)等先进的跟踪算法。因此,无论是处理图像还是视频,X-AnyLabeling致力于提供全面而高效的标注解决方案,以满足不同场景下的标注需求。
2.2支持一键导入/导出功能
当前,X-AnyLabeling 工具箱中还提供了一键导入/导出的便捷功能,支持多种主流数据标注格式,包括:
MOT-CSV:多目标追踪MOT任务标注
VOC-XML:Pascal VOC,仅支持Rectangle对象;
DOTA-TXT:旋转目标检测;
YOLO-TXT:支持Rectangle(检测)和Polygon(分割)对象;
COCO-JSON:支持Rectangle(检测)和Polygon(分割)对象;
MASK:支持语义分割和实例分割掩码一键导出;
因此,无论您是与其它工具协同工作,还是应用到不同的深度学习框架中进行训练,X-AnyLabeling 都旨在提供广泛的输出选项,确保用户能够灵活地集成标注结果到其工作流程中。
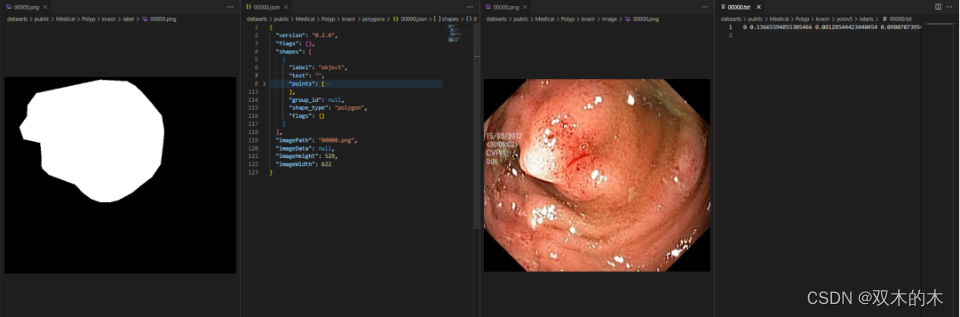
custom ↔ YOLO ↔ mask
通过直接加载上述导出的标签,我们可以快速导入到 YOLO 框架进行训练:
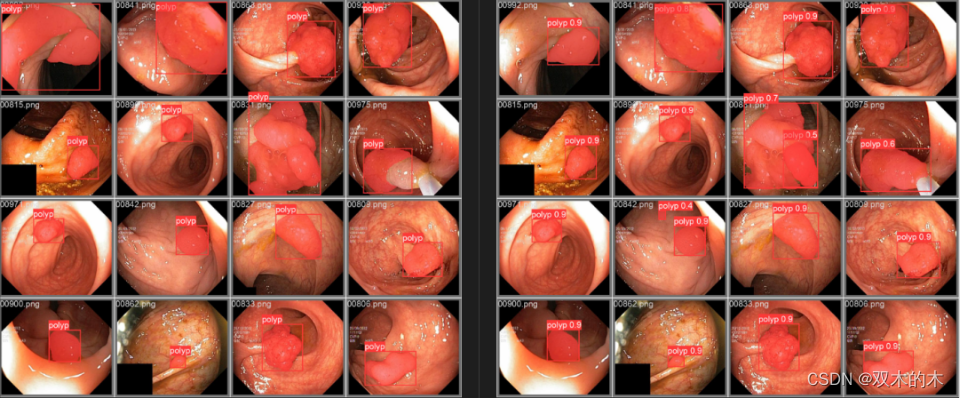
GT vs. Prediction
2.3支持多硬件环境和跨平台应用
X-AnyLabeling 支持在不同硬件环境下运行。除了常规的 CPU 推理外,还引入了 GPU 加速推理支持,当前推理后端仅支持OnnxRunTime,后续会逐步考虑添加TensorRT和OpenVINO等后端支持。此外,该工具具备多平台兼容性,能够在 Windows、Linux 和 MacOS 等不同操作系统环境下流畅运行。不仅如此,X-AnyLabeling 还提供了一键编译脚本,赋予用户根据其具体需求自行编译系统的能力,使用户能够随时随地轻松地分发应用,为其提供更加灵活的定制和部署体验,进一步简化工具的安装过程。
2.4支持单帧和批量预测
X-AnyLabeling 中提供了灵活的标注方式,支持单帧预测和一键处理所有图像。用户可以选择逐帧标注,以更加精细地处理每一张图像,也可以通过一键处理所有图像来快速完成整个数据集的标注。
2.5支持多种标注模式
为最大限度满足用户的各式需求,X-AnyLabeling 中提供了多样化的图像标注功能,包括多边形、矩形、旋转框、圆形、线条、关键点等基本标注形状。此外,工具还支持文本检测和识别,使用户能够方便地标注图像中的文字信息。更进一步,X-AnyLabeling还引入了 KIE(Key Information Extraction)标注,帮助用户标注并提取关键信息,以满足更复杂场景下的标注需求。
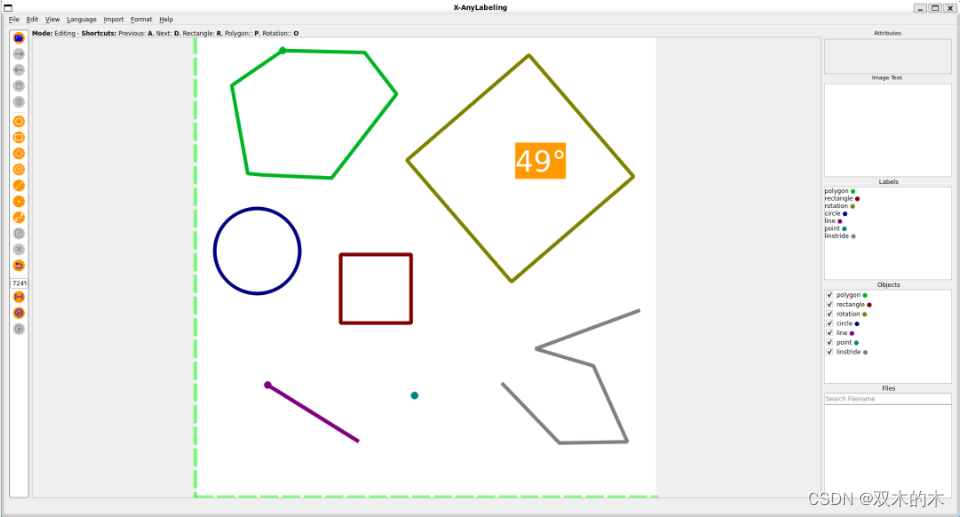
Tip: 旋转框还支持实时显示旋转角哦!
2.6支持多种SOTA深度学习算法
更进一步地,X-AnyLabeling 中内置了多种先进的深度学习算法,包括但不仅限于经典的目标检测算法如 YOLO 系列以及最热门的 SAM 系列等算法,目前仍在不断扩充中。
不仅如此,X-AnyLabeling 还支持导入用户自定义的模型,这一特性使其真正成为一个具备广泛适用性和高度可定制性的标注工具,满足用户的不同需求。
2.7提供详细的帮助文档和完善的社区支持
为了确保用户能够充分利用 X-AnyLabeling 的功能,提供了全面而详细的帮助文档。这些文档包含详细的使用说明、标注步骤、功能解释以及常见问题解答,旨在为用户提供清晰、易懂的指导,使其能够顺利地使用工具完成标注任务。
除此之外,仍积极维护和支持开发者社区,致力于建立一个互助互学的平台。在这个社区中,用户可以分享经验、提出问题、交流想法,得到来自开发人员的支持和解答(初步估计,目前X-AnyLabeling的bug修复率以及功能支持率高达95%+,基本做到有问必答,有bug必解!)。通过建立积极的开发者社区,小编一直希望能为用户提供更加全面、实时的支持,以确保大家在使用 X-AnyLabeling 时能够获得最佳的体验和帮助,同时也欢迎大家积极提PR。
3SOTA 算法库
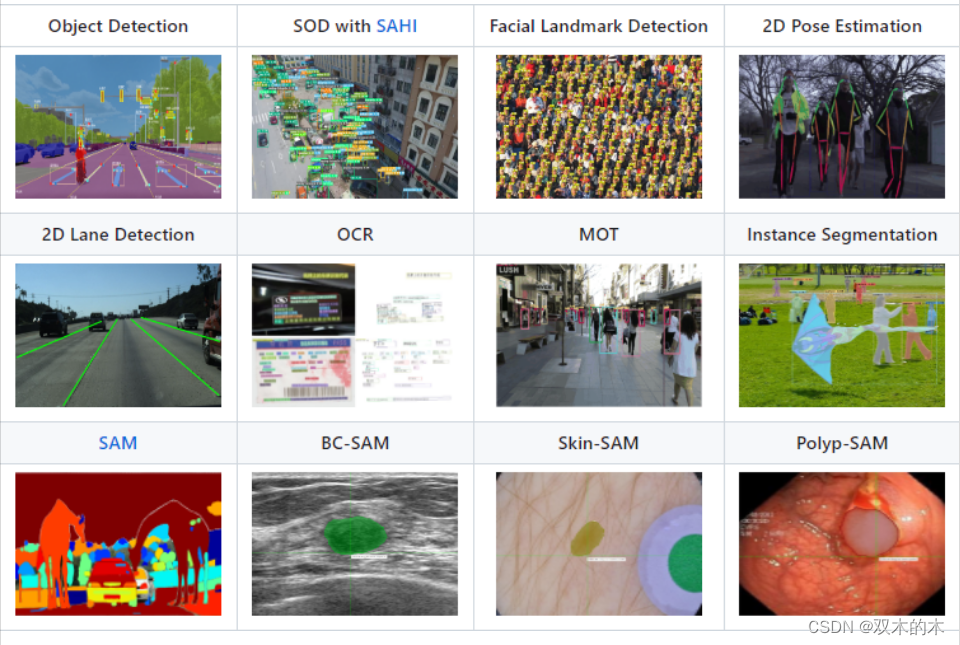
详情可参考[模型列表] (https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/model_zoo.md),其中所有模型权重文件均提供百度网盘和
github链接两种方式。
3.1Visual-Language LLM
作为 v2.0.0 版本的主打功能,X-AnyLabeling 正式实现了从闭集到开集的重大突破。首次推出的功能基于 Grounding-DINO、Grounding-SAM 等模型。其中,Grounding-DINO 是 IDEA 最新开源的零样本目标检测模型,通过任意文本驱动,能够根据用户提供的文字描述来检测图像中指定的目标。
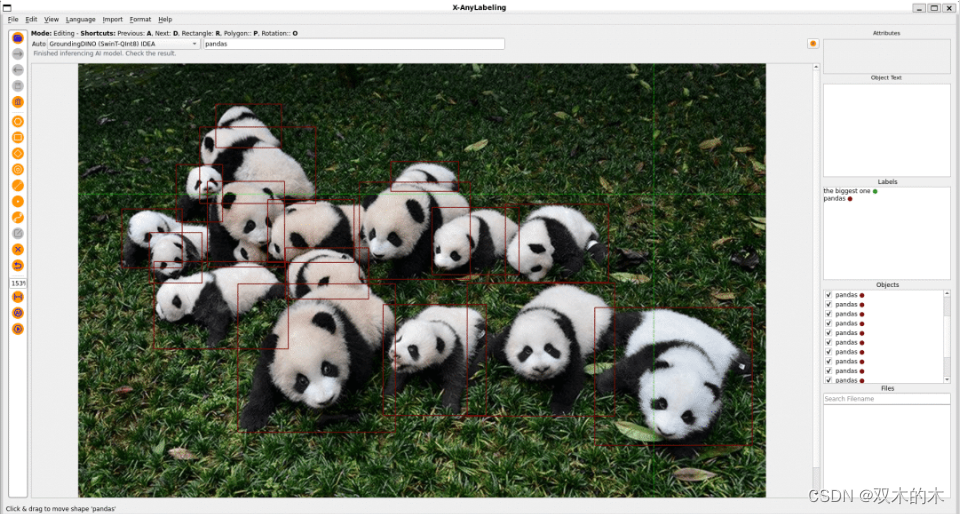
以检测大熊猫为例,检测结果显示模型几乎完美地定位了图像中的每个目标(panda),当然,结果也受到用户给定的文本提示词(prompt)的影响,例如将提示词从 pandas 更改为 panda 可能导致检测结果的变化。
为了实现真正的全自动标注,推荐大家体验最新部署的 Grounding-SAM。通过结合 X-AnyLabeling 工具中独家提供的一键运行组件和导出功能设置,用户可以高效地进行零样本检测和分割,轻松获取适用于各大主流训练框架的标签文件。
此外,尽管对于一些非通用目标定义仍然存在一些局限性,但通过亲自上手体验,可以更好地理解和掌握系统的运作方式。X-AnyLabeling 的持续优化和创新为用户提供了更广泛、更灵活的标注解决方案。
3.2Image Captioning
图像字幕生成是一项融合了计算机视觉(CV)和自然语言处理(NLP)的复杂任务,其目标是使计算机能够以自然语言自动生成对图像内容的详尽描述。具体而言,系统接收一张图像作为输入,通过 RAM 模型的强势植入,实现了自动生成生动而详实的文本描述。该描述旨在生动展现图像中的主要场景、对象及它们之间的关系,从而帮助人们更深入理解图像。
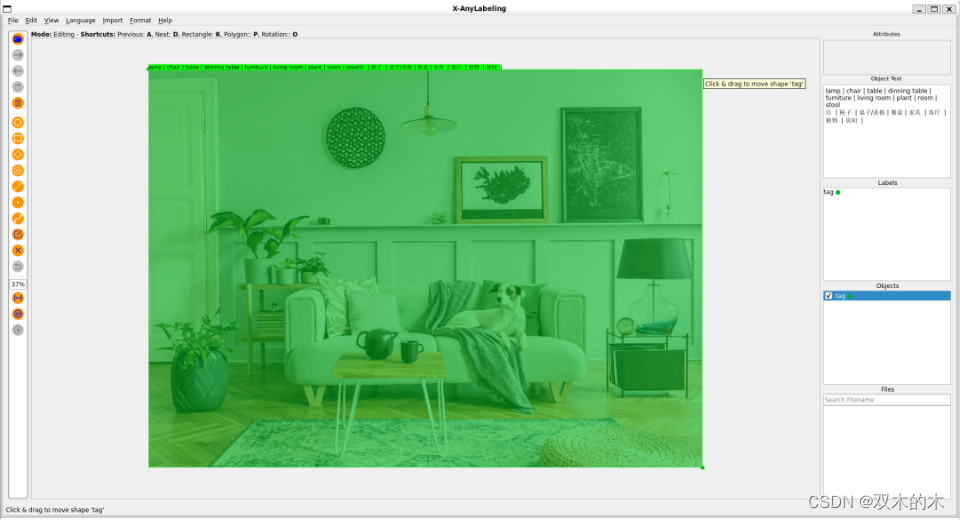
Recognize Anything, RAM 是专用于图像标记的识别一切模型,与 SAM 类似,作为基础模型,它具备卓越的识别能力,在准确性和识别种类方面均超越了 BLIP 等当前领先的模型。最新版本的 X-AnyLabeling 引入了 RAM 模型,并成功集成了该项图像字幕生成功能。
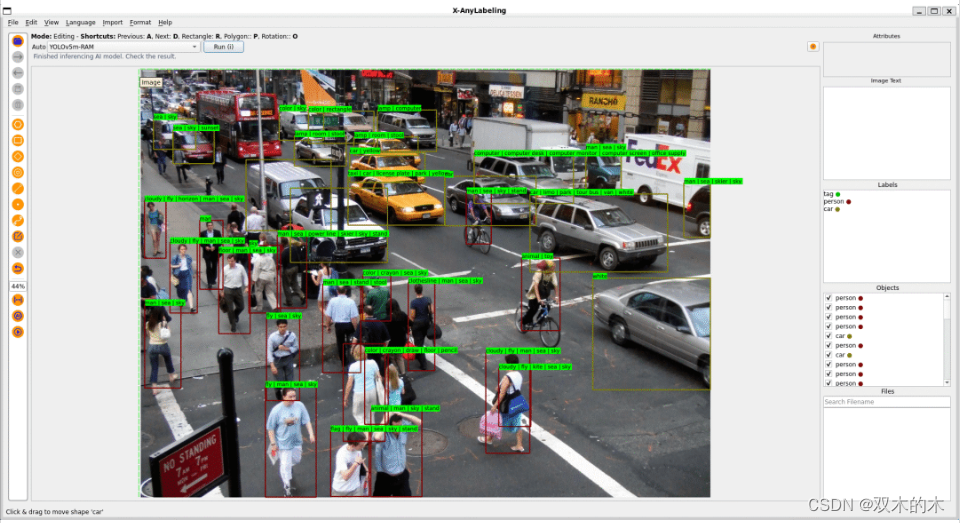
除了图像级别的描述之外,X-AnyLabeling 还引入了Object-level的图像描述功能,从而大幅丰富了系统的功能。这意味着系统不仅能够在整体上描述图像,还能够深入到图像中的各个对象层面,为用户提供更为细致和全面的信息。
3.3Image Classification
当前最新版本支持ResNet50、YOLOv5-cls、YOLOv8-cls以及最新的InternImage模型。

3.4Multi-Label Classification
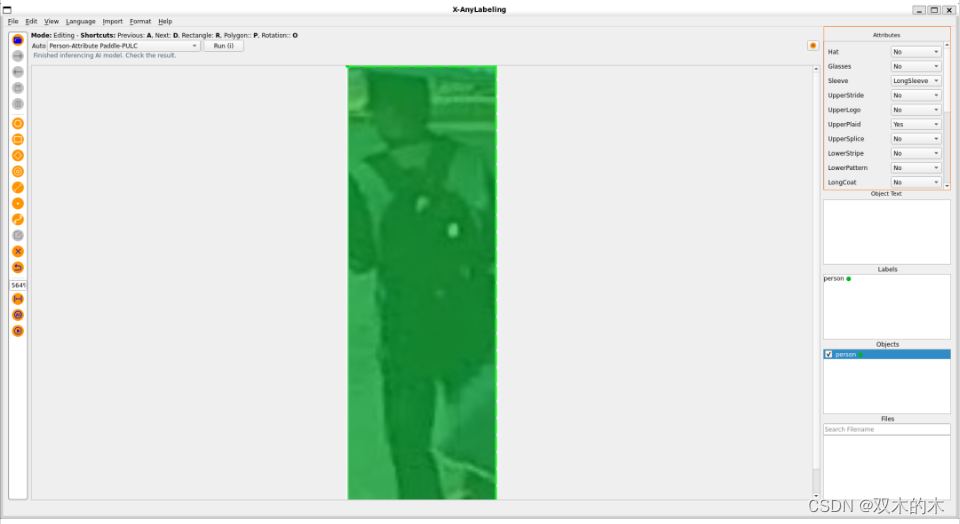
为满足广大粉丝的需求,X-AnyLabeling v2 版本引入了全新的多标签属性标注功能。首次推出的功能包括基于百度飞浆开源的 PULC 中的车辆属性(Vehicle Attribute)和行人属性(Person Attribute)模型。整体的用户界面(UI)设计以及标注范式遵循 CVAT 开源工具箱的标准,为用户提供更加一致和友好的体验。现在,您可以尽情体验这一全新的标注功能!
3.5Object Detection
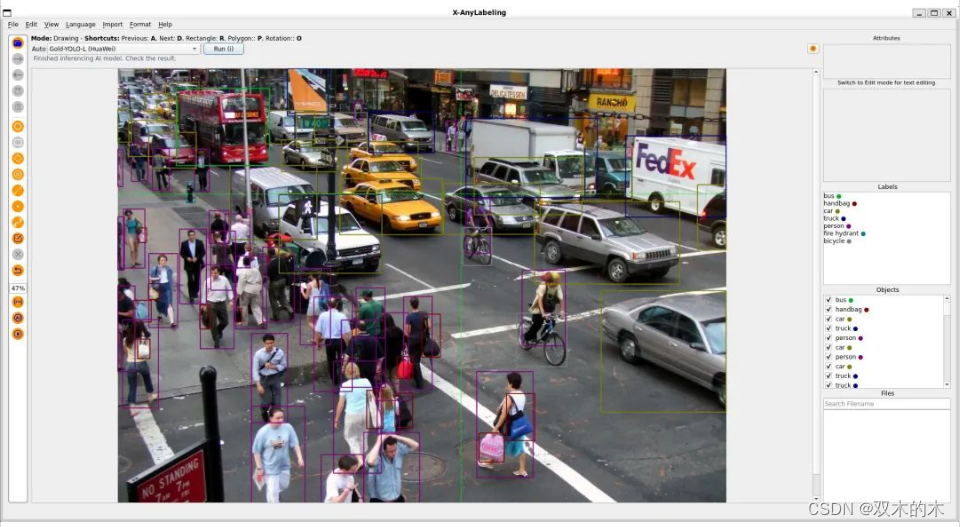
X-AnyLabeling 目前提供基于Horizontal Bounding Box,HBB即水平目标框(如yolov5/yolov6/yolov7/yolov8/yolox/yolo_nas/rtdeter/damo_yolo/gold_yolo等YOLO全系列产品)以及基于Oriented Bounding Box,OBB即有向目标框(如DOTAv1.0/1.5/2.0以及VisDrone数据集训练的yolov5_obb和yolov8_obb)的检测模型。
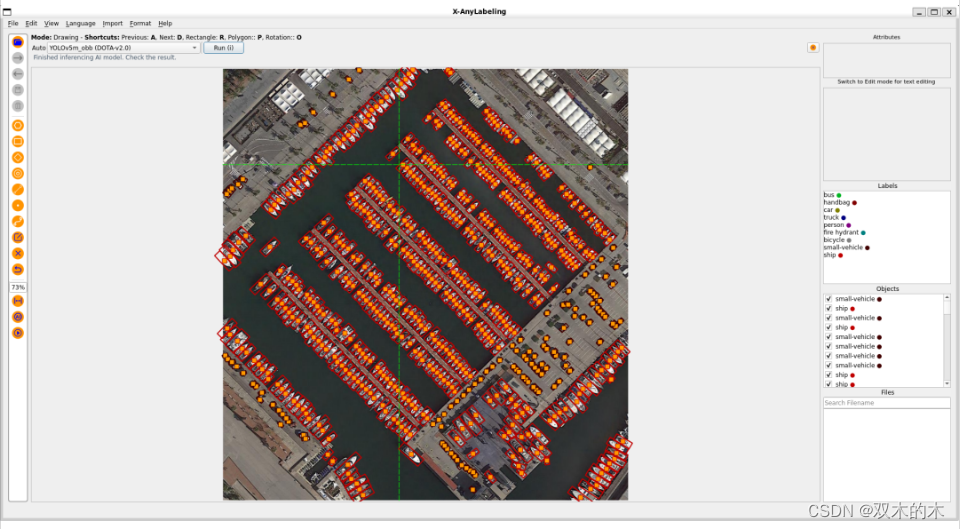
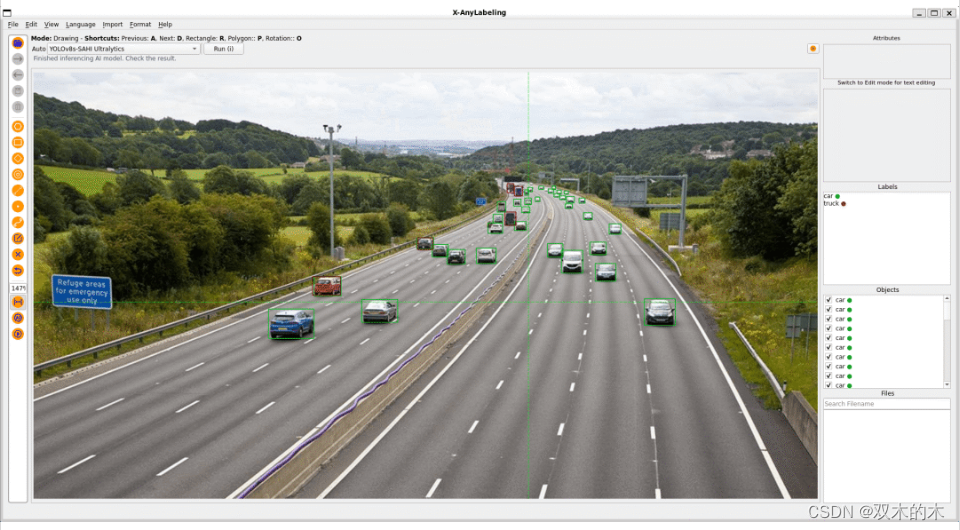
当然,你也可以替换为自定义模型。此外,为了提升小目标检出能力,X-AnyLabeling 中还集成了 SAHI 工具,支持切片推理,一键提升小目标检测性能:
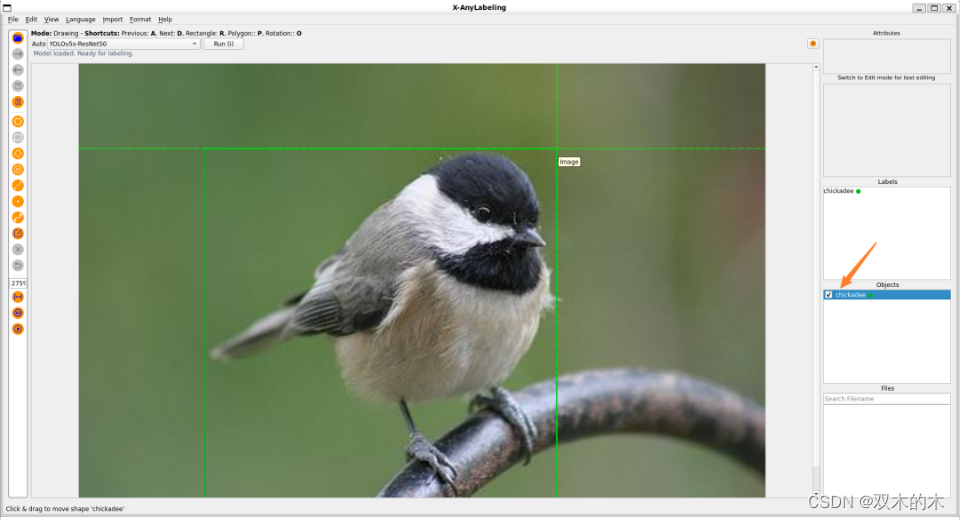
不仅如此,Classify-by-detection 同样也提供,支持对检测后的结果进行二次分类,提供更细粒度的识别结果!例如这里可以将原本是 bird 的类别进一步更正为 chickadee,即山雀:
3.6Multi-Object-Tracking
目前,X-AnyLabeling 已经内置了两种先进的多目标跟踪(MOT)算法,分别是经典的 ByteTrack 和最新的 OC-Sort(CVPR 2023)。默认情况下,检测器使用 yolov5,当然,用户也可以根据个人偏好将其设置为其他先进的检测和跟踪模型。

3.7Keypoint Detection
关键点检测部分主要包括人脸关键点回归(Facial Landmark Detection)和全身人体姿态估计(Pose Estimation)两个关键领域。在这方面,FLD 的一期规划已经植入了美团的 YOLOv6lite-face 模型。
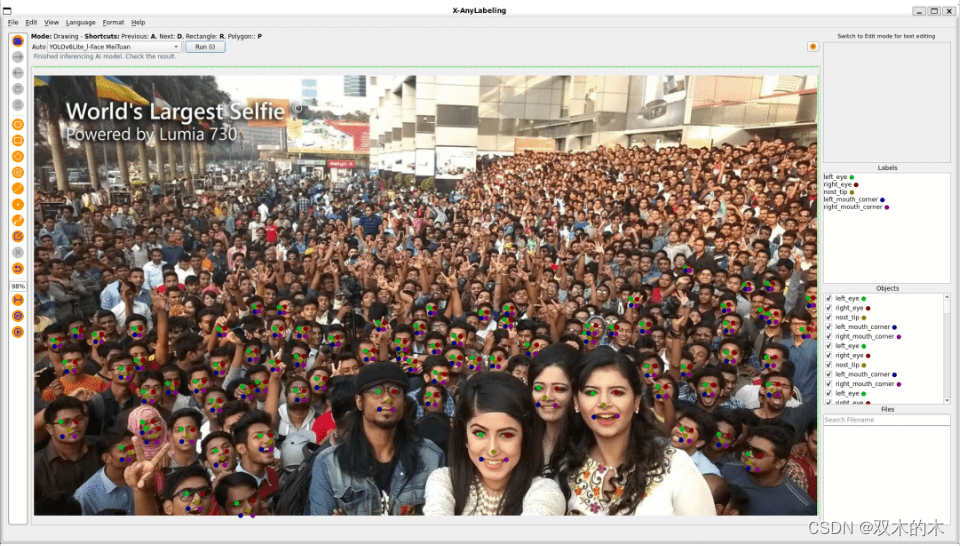
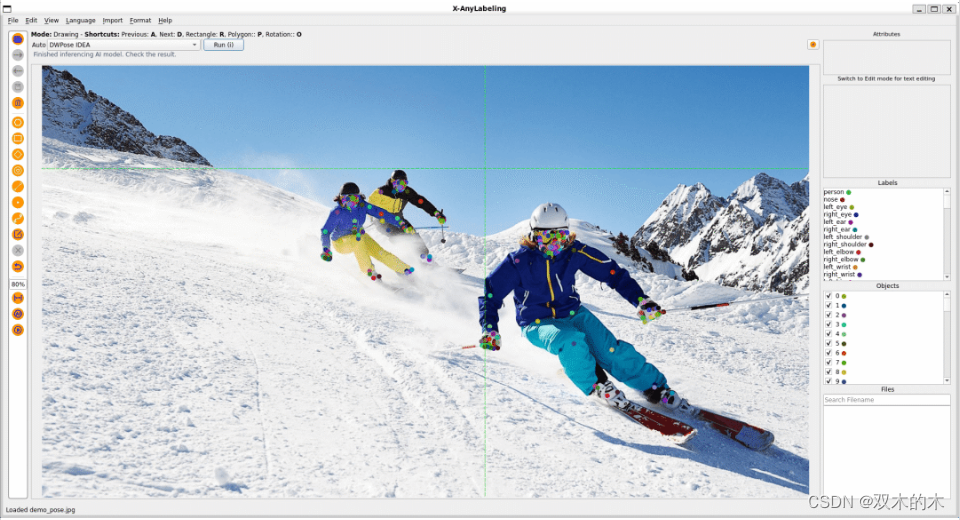
此外,姿态估计方面当前适配了面向产业界应用的 YOLOv8-Pose 模型和高精度的 DW-Pose 两阶段检测模型:
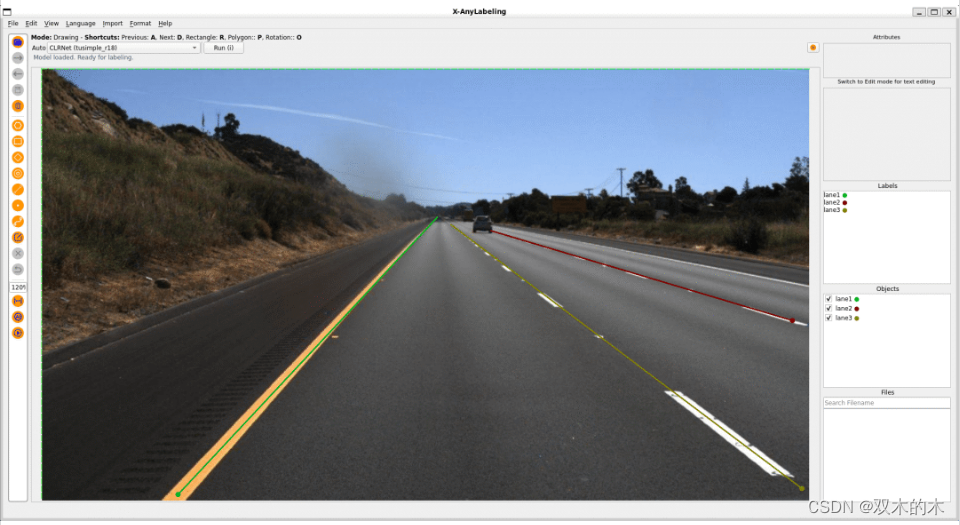
3.8Lane Detection
基于Line模式,X-AnyLabeling 中集成了 CLRNet-Tusimple (CVPR 2022) 模型供大家快速体验:
3.9Optical Character Recognition
OCR(光学字符识别)是一种通过使用机器学习和模式识别等方法自动识别图像中的文字并提取为可编辑的文本,方便后续处理、搜索和编辑。文本标签是许多标注项目中的一项常见任务,但遗憾的是在 Labelme 和 LabelImg 等工具中仍然没有得到很好的支持,X-AnyLabeling 中完美支持了这一项新功能。考虑到效率问题,目前工具内提供了基于 PaddlePaddle 最新开源的 PP-OCRv4 轻量化模型,支持中英文、多语种文本:

图像文本标签:用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。
文本检测标签:当用户创建新对象并切换到编辑模式时,可以更新对象的文本。
文本分组:想象一下,当使用 KIE(键信息提取)时,需要将文本分组到不同的字段中,包含标题和值。在这种情况下,你可以使用文本分组功能。当创建一个新对象时,我们同样可以通过选择它们并按G将其与其他对象组合在一起。分组的对象将用相同的颜色标记。当然,也可以按快捷键U取消组合。
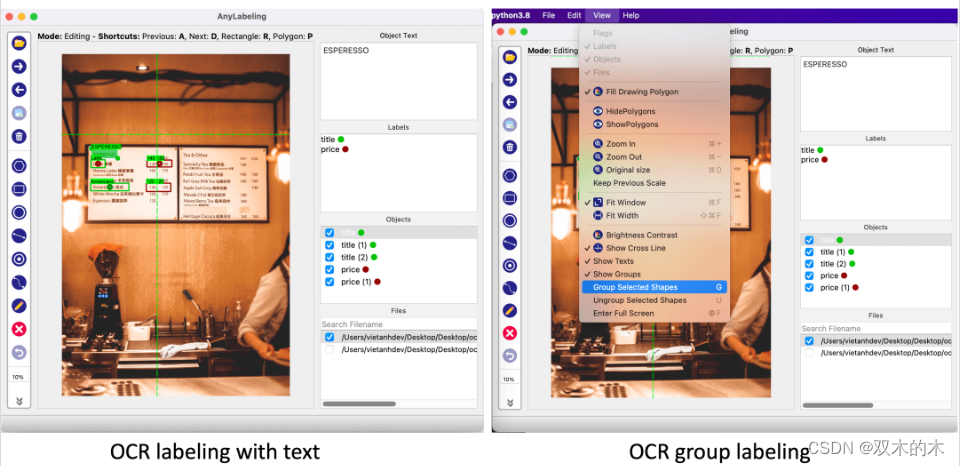
注:标注的文本和分组信息将与其他标注保存在同一个
JSON文件中。文本将保存在text对象的字段中,组信息将保存在字段中group_id。
3.10Instance Segmentation
目前 X-AnyLabeling 工具中提供的实例分割模型主要有两种范式,一种是常规的分割模型,如yolov5-seg和yolov8-seg:

另外一种是基于Segment-Anything范式,如SAM/EdgeSAM/Mobile-SAM/HQ-SAM/Efficientvit-SAM等:

Segment Anything Model(SAM)是 Facebook Research 近来开源的一种新的图像分割任务、模型,可以从输入提示(如点或框)生成高质量的对象掩模,并可用于生成图像中所有对象的掩模;
Mobile-SAM 通过解耦蒸馏方案可同步获取到轻量级的 SAM 编码器和解码器,有效提升了推理性能;
HQ-SAM 是第一个通过对原始 SAM 引入可忽略开销而实现高质量零样本分割的模型,发表于 NeurIPS 2023;
Efficientvit-SAM 则是由 MIT 韩松团队发表于 ICCV 2023 上的最新轻量化网络架构 Efficientvit 扩展而成的 SAM-like 模型,同时兼顾精度和速度!
Edge-SAM:支持移动端或CPU设备的高效推理,基本可以做到低延迟,同时又能满足一定的精度需求。
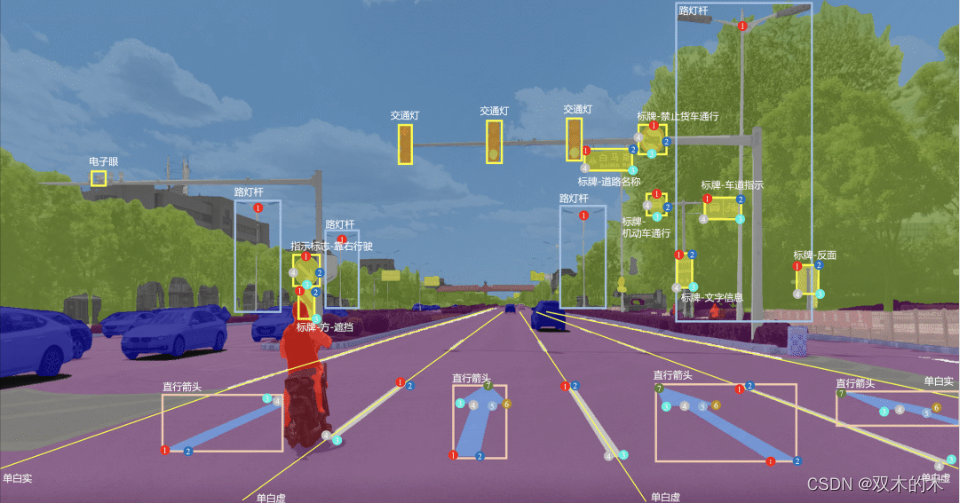
更进一步地,针对医学图像场景,X-AnyLabeling中同样提供了多种基于 SAM 微调的高精度模型,包括:
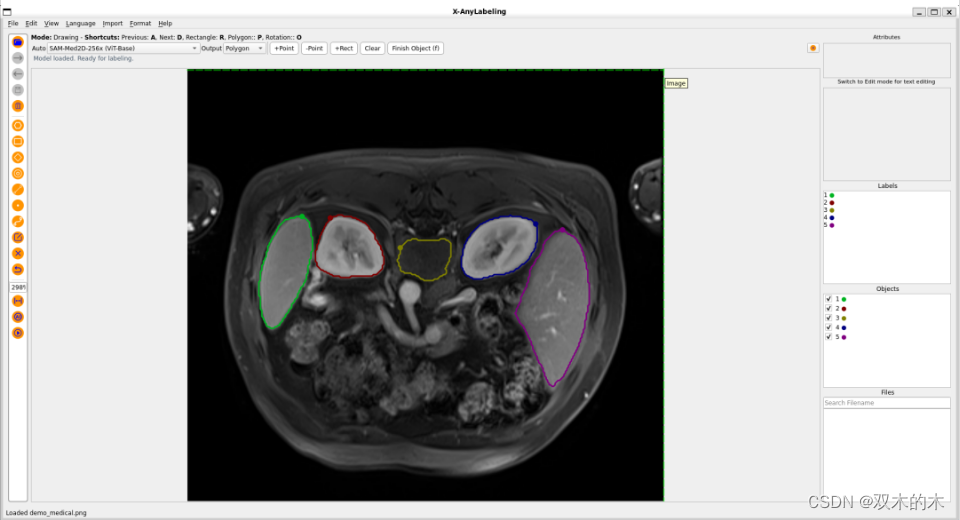
SAM-Med2D: 通用医疗图像分割一切模型;
LVM-Med ISIC SAM:皮肤病灶分割一切模型;
LVM-Med BUID SAM:超声乳腺癌分割一切模型;
LVM-Med Kvasir SAM:结直肠息肉分割一切模型;
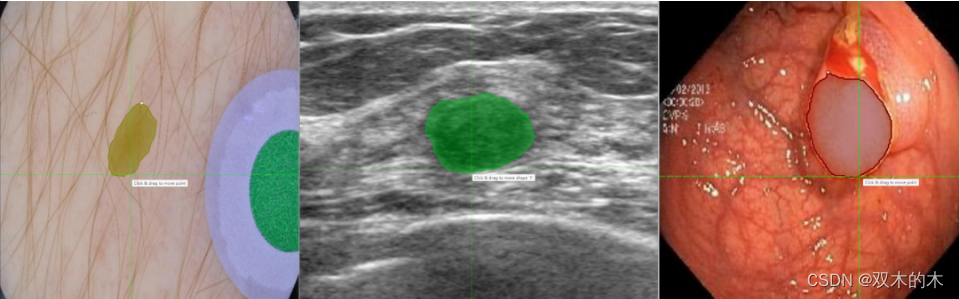
最后,工具内还内置了 yolov5-SAM 及 YOLOv8-EfficientvitSAM 模型,可以为原始的分割模型提供更加精细化的分割结果!
4推理架构
X-AnyLabeling 中的模型推理架构如下图所示:
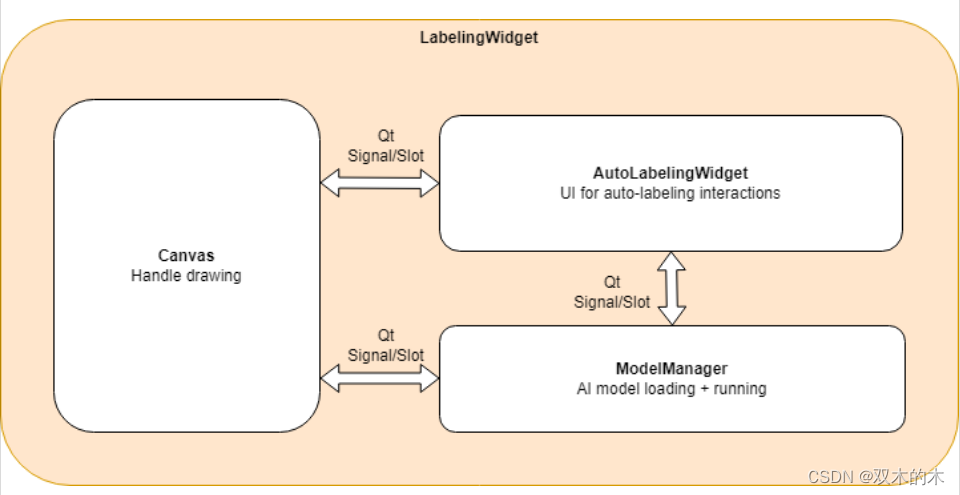
其中,LabelingWidget是推理 SAM 系列模型推理功能所需的核心部件。绘图区域是由Canvas类处理,而AutoLabelingWidget则作为自动标记功能和ModelManager的主要部件用于管理和运行 AI 模型。
4.1优化点:
因为Encoder的计算是需要时间的,所以我们可以把结果缓存起来,也可以对Encoder在以后的图片上做预计算。这将减少用户等待编码器运行的时间。
对于缓存,添加了一个 LRU 缓存来保存编码器的结果。图像保存在缓存中,键是标签路径。当缓存中存在图像嵌入时,不会再次运行编码器,这样可以节省很多时间。缓存大小默认为 10 张图像。
对于预计算,创建一个线程来为下一个图像运行编码器。当加载新图像时,它将和下一张图像一起发送到工作线程进行编码器计算。之后,image embedding会缓存到上面的LRU缓存中。如果图像已经在缓存中,工作线程将跳过它。
4.2SAM 模型使用步骤
选择左侧的Brain按钮以激活自动标记。
从下拉菜单Model中选择Segment Anything Models类型的模型。模型精度和速度因模型而异。其中,Segment Anything Model (ViT-B)是最快的但精度不高。Segment Anything Model (ViT-H)是最慢和最准确的。Quant表示量化过的模型。
使用自动分割标记工具标记对象。
+Point:添加一个属于对象的点。
-Point:移除一个你想从对象中排除的点。
+Rect:绘制一个包含对象的矩形。Segment Anything 将自动分割对象。
清除:清除所有自动分段标记。
完成对象(f):当完成当前标记后,我们可以及时按下快捷键f,输入标签名称并保存对象。
4.3注意事项:
由于 SAM 部署时采用了编解码分离的范式并应用了 LRU 机制,因此第一次进行推理时后天会缓存多张(可自行设置)图片的 image_embedding,具体见下述"集成方式"章节。
X-AnyLabeling 在第一次运行任何模型时,需要从远程服务器下载模型,可能需要一段时间,这具体取决于本地的网络速度和服务运营商。此外,由于当前模型存放在 github 托管,因此如果没有开启科学上网的化,大概率会由于下载失败而中断,可以参考后续实操步骤解决。
4.4集成方式
Segment Anything Model 分为两部分:一个很heavy的编码器和一个lightweight解码器。编码器从输入图像中提取图像嵌入。基于嵌入和输入提示(点、框、掩码),解码器生成输出掩码。解码器可以在单掩码或多掩码模式下运行。
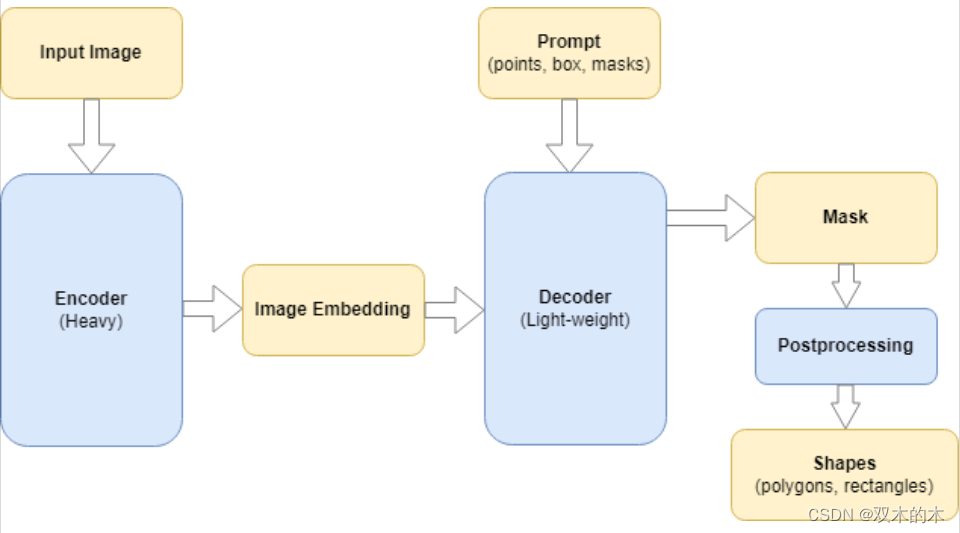
在演示中,Meta 在服务器中运行编码器,而解码器可以在用户的浏览器中实时运行,如此一来用户便可以在其中输入点和框并立即接收输出。在本项目中,我们还为每个图像只运行一次编码器。之后,根据用户提示的变化(点、框),运行解码器以生成输出掩码。项目添加了后处理步骤来查找轮廓并生成用于标记的形状(多边形、矩形等)。
5使用手册
5.1如何快速开始?
X-AnyLabeling 目前提供两种方式供大家运行。第一种是偏向小白用户,大家可以直接再 release 或者直接通过百度网盘链接下载编译好的 GUI 版本,打开即用,具体可参考以下链接:
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/get_started.md
直接下载exe的方式推荐链接:
Release X-AnyLabeling v2.3.0 · CVHub520/X-AnyLabeling (github.com)

第二种方式是通过下载源码运行,也是笔者比较建议的构建方式。具体的可以根据自己的机器和个人需求直接 pip 安装相关的依赖库即可。如果遇到某个包如(lap库)安装失败,可以自行上网搜索下解决方案。此外,如果是想体验GPU加速功能,需要安装对应的 requirements*-gpu.txt 文件,同时修改文件中的 onnxruntime-gpu 版本号,要与 CUDA 匹配,具体适配对照表可参考官方文档 [https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html]。
5.2如何修改自定义快捷键?
X-AnyLalbeing 中同样提供了丰富的快捷键,极大提升标注效率。大家可根据自己的习惯通过修改当前设备的用户根目录下的 .anylabelingrc 文件进行修改:
#Linuxcd ~/.anylabelingrc#Windowscd C:\\Users\\xxx\\.anylabelingrc默认的快捷键设置可以参考 github 主页示意图。
5.3如何支持自定义模型?
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/custom_model.md
5.4如何导入/导出自定义标签?
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/user_guide.md
5.5如何编译打包成可执行文件?
可参考以下打包指令:
#Windows-CPUbash scripts/build_executable.sh win-cpu#Windows-GPUbash scripts/build_executable.sh win-gpu#Linux-CPUbash scripts/build_executable.sh linux-cpu#Linux-GPUbash scripts/build_executable.sh linux-gpu注意事项:
编译前请针对相应的 GPU/CPU 版本修改
anylabeling/app_info.py文件中的__preferred_device__参数,同时根据对应参数激活对应的 GPU/CPU 虚拟环境;如果需要编译
GPU版本,请通过pip install -r requirements-gpu-dev.txt安装对应的环境;特别的,对于GPU版本的编译,请自行修改anylabeling-win-gpu.spec的datas列表参数,将您本地的onnxruntime-gpu的相关动态库*.dllor*.so添加进列表中;此外,下载onnxruntime-gpu包是需要根据CUDA版本进行适配,具体匹配表可参考官方文档说明。对于
macos版本可自行参考anylabeling-win-*.spec脚本进行修改。
6写在最后
本文详细为大家介绍了 X-AnyLabeling 的设计初衷及完整的功能特性介绍。作为一款支持高度定制化的开源工具,其实大家完全可以基于该项目进行二次开发;例如我们可以联合目标追踪、检测及OCR识别等做视频人物和字幕的解析;可以编写TensortRT后端完成更高效的推理;又或者是引入AI Agent构建更高效和强大的数据标定流程等。
文章结束,感谢阅读。大家有推荐的公众号可以评论区留言,共同学习,一起进步。