1、简要描述
上一篇博客主要讲的是pdf文件转换成canvas,然后进行相关的画框截图操作。
【PDF】Canvas绘制PDF及截图
本篇博客主要讲html中dom如何生成pdf文件(前端生成pdf),后端生成pdf当然也可以,原理也是将html网页通过后端服务导出成pdf,然后css设置break-after:always;作为分页逻辑,但是我们不深入讲,这里着重讲前端生成pdf。
2、相关插件及知识
还是使用的老朋友jspdf插件和html2canvas
1、jspdf
"jspdf": "^2.5.1"使用方法:
import JsPDF from 'jspdf';const PDF = new jsPDF({ unit: "mm", // 单位,本示例为mm format: "a4", // 页面大小 orientation: "portrait", // 页面方向,portrait: 纵向,landscape: 横向 putOnlyUsedFonts: true, // 只包含使用的字体 compress: true, // 压缩文档 precision: 16, // 浮点数的精度});// 或者const PDF = new JsPDF('p', 'mm', [210, 297]);<!-- 常用方法 -->// 添加图片PDF.addImage( imageData, // 此值可以为下面这些类型 string | HTMLImageElement | HTMLCanvasElement | Uint8Array | RGBAData 'JPEG', // 转换后的格式 x, // 被切割的imageData的横坐标 y, // 被切割的imageData的纵坐标 w, // 当前图片的宽度 h, // 当前图片的高度);// 添加新的一页PDF.addPage();// 输出格式PDF.output(type: "arraybuffer"): ArrayBuffer;PDF.output(type: "blob"): Blob;PDF.output(type: "bloburi" | "bloburl"): URL;// 本地保存为pdf文件PDF.save('lindadayo.pdf')2、html2canvas
"html2canvas": "^1.4.1"// 实例方法 html2canvas(dom, config).then(function(canvas) {}) config相关配置参考下图:
3、源码
1、dom结构

2、核心逻辑
这里为什么要将dom进行分区处理呢?请看第四点疑难解答中1、为什么要对dom进行分区操作?
/** * 生成pdf * @param CommonPage 需要转换的dom节点 * @param i 分区索引 * @returns */ async generatePdf(CommonPage?: Element, childLen?: number) { PDF = new JsPDF('p', 'mm', [210, 297]); // pdf实例 for (let i = 0; i < childLen; i++) { await asyncSingleAreaControl(CommonPage, i) } generateUploadPdf(); }, /** * 上传pdf文件 */ async generateUploadPdf() { // 文件重命名,修改生成pdf后的文件名 const pdfName = pdfNameHandle() const uri = PDF.output('blob') const file = await blobUriToFile(uri, pdfName) // 此时的file是File类对象,你可以选择上传到服务器噢~当然你也可以选择直接导出到前端 // PDF.output('lindadayo.pdf'); }, /** * 单个分区生成pdf操作 * @param CommonPage 父节点dom * @param i 分区索引 * @returns */ async asyncSingleAreaControl(CommonPage, i) { const canvas = await singleHandle(CommonPage, i) await areaPage(canvas, i) }, /** * 分区pdf处理 * @param canvas 各个分区dom转换后的canvas * @param areaNo 分区索引 */ areaPage(canvas, areaNo) { // 是否是第一个分区(作用于是否开始就addPage) const isFirstArea = areaNo === 0 return new Promise((resolve, _reject) => { // a4纸宽高 const A4Origin = { width: PDF.internal.pageSize.getWidth(), height: PDF.internal.pageSize.getHeight() } const contentWidth = canvas.width; /** * html2canvas放大3.125倍时精度丢失导致多了2像素 * 3368: 高度285mm纸张html2canvas放大300dpi后像素 * 3366:正常实际高度 */ const contentHeight = canvas.height <= 3368 ? 3366 : canvas.height; const pageHeight = Math.round(contentWidth / A4Origin.width * A4Origin.height); let leftHeight = contentHeight; let position = 0; const imgWidth = A4Origin.width; const imgHeight = Math.ceil(A4Origin.width / contentWidth * contentHeight); const pageData = canvas.toDataURL('image/jpeg', 1); // 非首个分区,得先addPage,因为不然会少一页 && 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页 if (!isFirstArea && leftHeight > 0) { PDF.addPage() } while (leftHeight > 0) { PDF.addImage(pageData, 'JPEG', 0, position, imgWidth + (isBrower() ? 0.62 : 0), imgHeight + (isBrower() ? 0.32 : 0)); position -= A4Origin.height; leftHeight -= pageHeight // 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页 if (leftHeight > 0) { PDF.addPage() } } resolve(true) }) }, /** * 单页pdf处理 // * @param root 总节点 * @param index 分区索引 */ async singleHandle(CommonPage, index) { // 报错Unable to find element in cloned iframe解决方法 // getDiv在外部声明, 内部赋值 try { getDiv = CommonPage.querySelector(`#CommonPageItemArea-${index}`) const res = await html2canvas(getDiv, { useCORS: true, allowTaint: true, scale: 3.125 }).then(function(canvas) { return canvas }) return res } catch (e) { console.log(e) } }4、疑难解答
1、为什么要对dom进行分区操作?
其实如果你不使用html2canvas的参数scale,就没必要进行分区,但是在很多时候,你不放大canvas的话,会导致pdf中的图片很模糊,还有锯齿,所以要对canvas进行方法,但是放大后,会导致一些问题:生成pdf后,超过15000px以后的dom会有样式丢失,所以得对dom进行分区操作,让每个分区的dom高度 * 放大倍数不超过15000px。我们一般都会导出a4纸大小,a4纸宽高是210mm*297mm,换算成像素是793.29px * 1122.52px,如果你选择放大两倍,那么,单页高度就是2245px,结论为一个分区能够放六个a4纸高度的dom,所以你在开发页面时,就要做好这种页面结构噢~
2、html2canvas仍然报图片出错/跨域的问题,即使后端oss已经解决跨域了
报错Error loading image
![]()
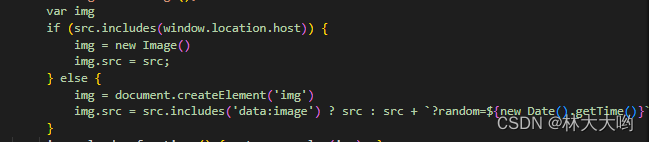
这个涉及知识点:img标签实例化获取属于非跨域操作,Image类实例化属于跨域操作,所以得再html2canvas依赖中打补丁,当图片是你本地的静态图片,那不需要转,还是按照Image实例化来做,当图片已经是base64格式的话,也不需要转,赋值给img标签,否则的话加上随机数。
/dist/html2canvas.js 第5759行
3、报错Unable to find element in cloned iframe解决方法
在分区中循环处理dom生成canvas时会报出这种错误,原因是html2canvas第一参数的变量应该设置为全局变量而不应该是局部变量
try { getDiv = CommonPage.querySelector(`#CommonPageItemArea-${index}`) const res = await html2canvas(getDiv, { useCORS: true, allowTaint: true, scale: 3.125 }).then(function(canvas) { return canvas }) return res } catch (e) { console.log(e) }4、dom-to-image和html2canvas相比,哪个更优?
dom-to-image是一个js库,可以将任意dom节点转换为矢量(SVG)或光栅(PNG或JPEG)图像。和html2canvas相比的话,算是一个新起之秀,更轻巧,相同点就是都会先将dom转成canvas进行操作,所以在dom层级深和多的情况下,还是建议使用html2canvas这种老牌插件
5、生成pdf里图片缺失
那是因为图片转换及获取是异步的,需要时间渲染,所以生成pdf的步骤应该在图片完全加载完之后,由此我们可以加个定时器来循环判断全部图片是否加载完成,加载完成再进行生成操
/** * CommonPage生成dom渲染完成 * @param callback */ commonPageLoadFinish(callback) { nextTick(() => { // 生成节点 const CommonPage = document.querySelector('#CommonPage') const childLen = CommonPage.querySelectorAll('.CommonPageItemArea').length console.log('分区数量', childLen) if (childLen > 0) { let timer = null; // 监听页面中所有转base64图片是否已生成完毕,如果已生成完毕,则进入下一步与dom相关的操作 timer = setInterval(() => { // isImageAllCompleted.sum => 图片总数量, isImageAllCompleted.loadSum => 目前图片已经加载完的数量 if (isImageAllCompleted.sum === isImageAllCompleted.loadSum) { clearInterval(timer) timer = null callback(CommonPage, childLen) } }, 1000) } }) }将生成pdf步骤作为回调函数放在上述函数里
commonPageLoadFinish(generatePdf)那在组件中如何监听图片是否加载完成呢?按照以下代码来写
onMounted(() => { nextTick(() => { // commonRef.value 为某dom的refs // 被动检测是否有图片, 无则直接进入主逻辑 const img = commonRef.value.querySelectorAll('img'); if (!img.length) return methods.successCallback(); let imgSum = 0; asyncImgCompLoad(img).then((res) => { res.forEach(() => imgSum++); // 设置图片总数量和加载数量 setImageAllCompleted({ sum: isImageAllCompleted.sum + img.length, loadSum: imgSum + isImageAllCompleted.loadSum }); }) }) }) async asyncImgCompLoad(imgList) { const promiseList = [] for await (const item of imgList) { promiseList.push(new Promise((res, rej) => { // 参数没有被赋值 if (!item.src) { rej(false) } if (item.complate) { res(true) } else { item.addEventListener('load', () => { res(true) }) // 图片被赋值,但是赋的是错误的值 item.addEventListener('error', () => { rej(false) }) } })) } return Promise.allSettled(promiseList) }6、生成的pdf里,单页底部有白边?
在使用PDFjs插件时候,加入需要导出a4纸大小,那么很多童鞋就会将宽高固定设置为210mm, 297mm,但是实际上不是整数,是小数,所以获取时按照下述方法获取
// a4纸宽高 const A4Origin = { width: PDF.internal.pageSize.getWidth(), height: PDF.internal.pageSize.getHeight() }PDF分页核心源码
// a4纸宽高 const A4Origin = { width: PDF.internal.pageSize.getWidth(), height: PDF.internal.pageSize.getHeight() } const contentWidth = canvas.width; /** * html2canvas放大3.125倍时精度丢失导致多了2像素 * 3368: 高度285mm纸张html2canvas放大300dpi后像素 * 3366:正常实际高度 */ const contentHeight = canvas.height <= 3368 ? 3366 : canvas.height; const pageHeight = Math.round(contentWidth / A4Origin.width * A4Origin.height); let leftHeight = contentHeight; let position = 0; const imgWidth = A4Origin.width; const imgHeight = Math.ceil(A4Origin.width / contentWidth * contentHeight); const pageData = canvas.toDataURL('image/jpeg', 1); // 非首个分区,得先addPage,因为不然会少一页 && 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页 if (!isFirstArea && leftHeight > 0) { PDF.addPage() } while (leftHeight > 0) { PDF.addImage(pageData, 'JPEG', 0, position, imgWidth + (isBrower() ? 0.62 : 0), imgHeight + (isBrower() ? 0.32 : 0)); position -= A4Origin.height; leftHeight -= pageHeight // 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页 if (leftHeight > 0) { PDF.addPage() } }有两个地方可能童鞋们没看懂,1、首先为啥非首个分区,得先addPage呢?因为PDF默认就有一页,所以你能够直接addImage而不出错,然后后续PDF想要新增一页,都得先addPage,这时候默认背景颜色是白色的,然后再将canvas转成图片,贴到这白板上的,所以你看到PDF文档里有白边,那毫无疑问,就是贴的图片没占完那一页,并且火狐浏览器和谷歌浏览器还有一些细微的差别所以你这就得一点一点微调来达到最佳显示效果。2、为啥addIMage时,里面传的参数不同呢?
PDF.addImage(pageData, 'JPEG', 0, position, imgWidth + (isBrower() ? 0.62 : 0), imgHeight + (isBrower() ? 0.32 : 0));这就是浏览器差异问题,火狐浏览器不仅底部有白边,侧面也有白边,相比之下谷歌要更兼容一些。
7、pdf生成的File文件对象,想要先传入oss,再通过服务端下载怎么实现?
这其实就涉及到大文件上传技术了,因为pdf稍微大点可能都上百M,一般都不会一次性上传完的,所以得做切片上传,然后在服务端合并上传到oss,最后将oss路径地址返回给前端,前端通过这地址去下载。当然具体的大文件上传我就不写在这篇博客了,下一篇博客我将着重讲大文件上传如何写噢~
8、vue-fragment插件配合html2canvas使用有问题?
在@vue/composition-api环境下开发,想使用fragment就得使用vue-fragment插件,但是搭配上html2canvas导出canvas会出现bug,就是只会渲染第一个fragment标签的dom,其他的都不会渲染,目前还是建议在@vue/composition-api环境下不使用fragment
--- 有问题可以随时评论噢~喜欢的请点赞收藏啦 ---