目录
1. CTC-Loss概述
2. CTC-Loss与文字识别算法
3. CTC-Loss与语音识别算法
4. CTC-Loss原理
5. CTC-Loss优缺点
6. CTC-Loss Pytorch实现
1. CTC-Loss概述
为了解决输入和输出对齐问题,标记未分割序列数据是现实世界序列学习中普遍存在的问题,如图像文本识别(OCR)、姿势识别、语音识别(ASR)CTC Loss 是一种不需要数据对齐的,广泛用于图像文本识别和语音识别任务的损失函数
存在的问题:
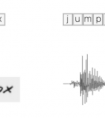
1)在图像文本识别、语言识别的应用中,所面临的一个问题是神经网络的输出与ground truth的长度不一致,导致loss难以计算,例如:“-sst-aa-tt-e” vs“state”(ground truth)
2)Many-to-One,有多种情况的输出都对应着ground truth,例如:“-ss-t-a-t-e-”“--stt-a-tt-e”vs“state”
2. CTC-Loss与文字识别算法
常用的文字识别算法主要有两种框架:
CNN + CRNN(Convolutional Recurrent Neural Network) + CTC-LossCNN + Seq2Seq + Attention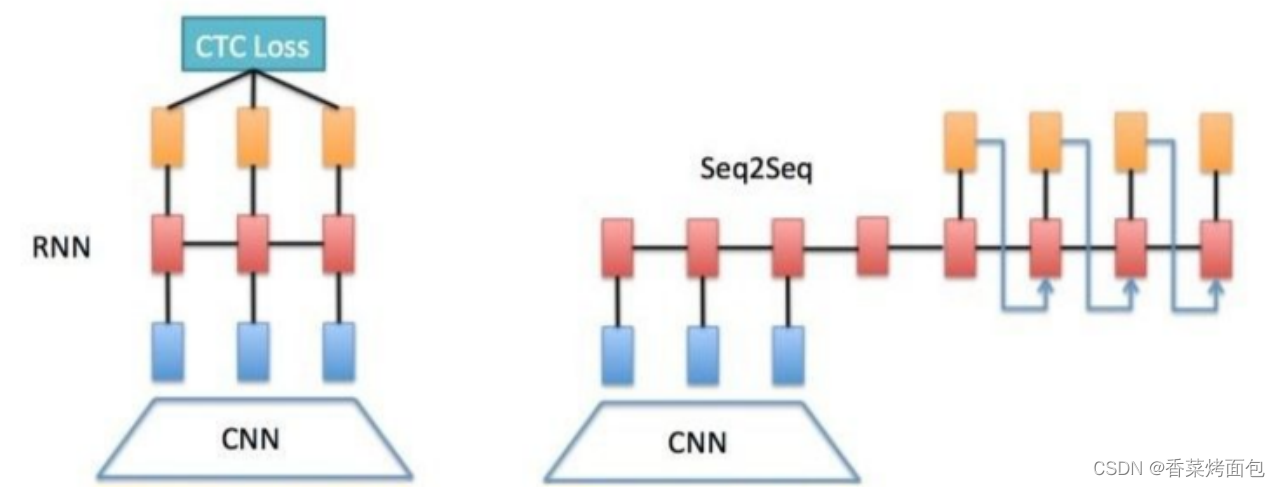
CRNN主要用于端到端对不定长的文本序列进行识别。它不先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,直接基于图像进行文字序列识别。
CRNN算法最大的贡献在于把CNN做图像特征工程的潜力与RNN做序列化识别的潜力进行结合,它既提取了鲁棒特征,又通过序列识别避免了传统算法中难度极高的单字符切分与单字符识别。
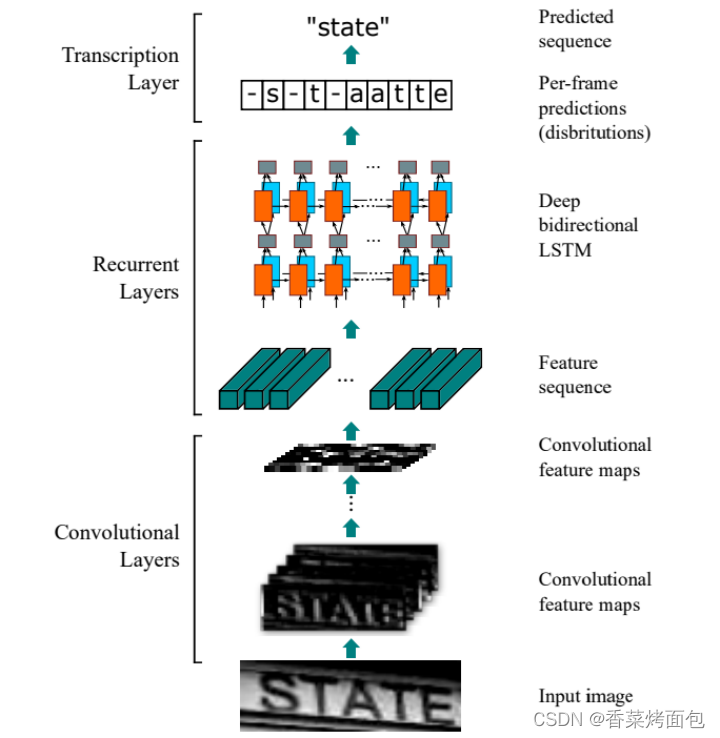
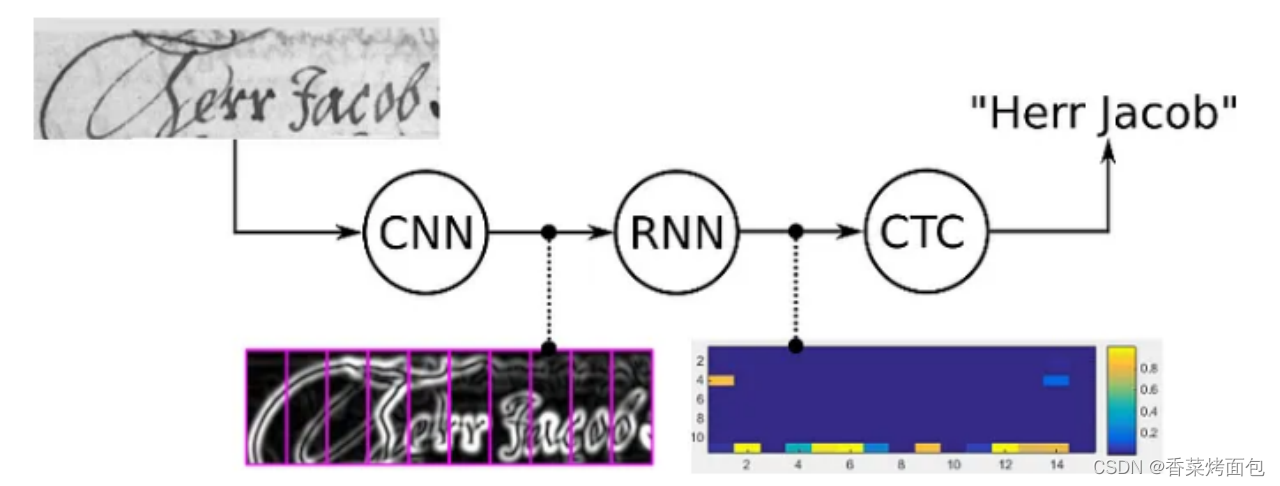
如下图所示,首先通过将图片划分为几个竖直方向的图像,分别识别每列小图片中的文字,从而实现整体文本的识别。
每一列输出都需要对应一个字符元素:用 - 表示blank(空白),预测值 [-ttooo] 和ground truth [to] 的长度不一致,采用常规的损失函数(cross entropy、MSE等)计算时需要先进行对齐才能计算损失。
进行对齐就需要在训练之前的数据标注阶段在训练集图片中标记出每个字符的真实文本和在图片中的位置。但在实际情况中,标记这种对齐样本非常困难,其工作量非常大。并且由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
3. CTC-Loss与语音识别算法
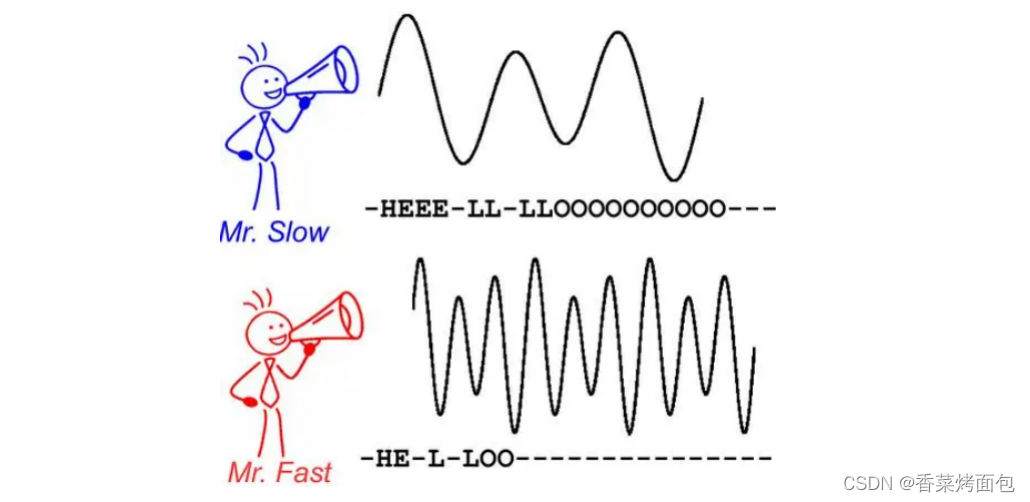 说话快慢如何进行语音帧对齐?
说话快慢如何进行语音帧对齐?
解码器的规则:将连续的相同字符合并,以及去掉blank
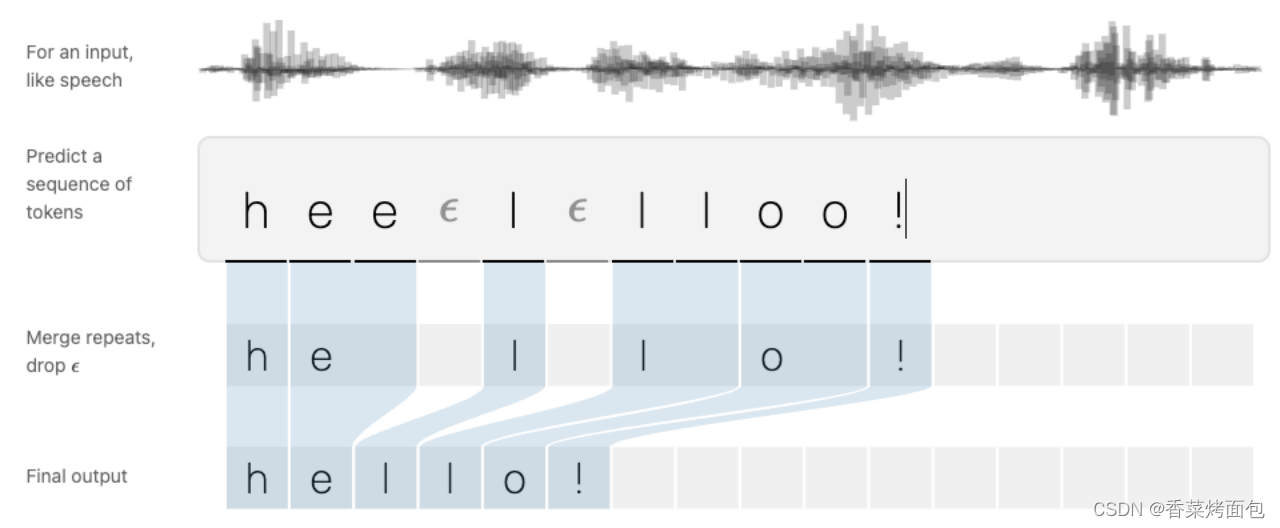
空格的作用:
预测连续两个相同的字母的单词预测完整的话,表示出单词与单词之间停顿的部分
4. CTC-Loss原理
CTC Loss的计算对象是神经网络经过softmax归一化之后的输出矩阵和ground truthCTC Loss 不要求输出矩阵和ground truth的大小相同。输出矩阵的维度为N×T,其中N是类别数(在英文的语音识别中N=27,即26个英文字母和blank),T是语音长度(T个语音帧)
5. CTC-Loss优缺点
优点:不需要数据对齐
缺点:CTC的缺点来源于三个约束:
(1)条件独立:假设每个时间片都是相互独立的,但在OCR或者语音识别中,相邻几个时间片中往往包含着高度相关的语义信息,它们并非相互独立;
(2)单调对齐:CTC要求输入与输出之间的对齐是单向的,在OCR和语音识别中,这种约束是成立的。但是在一些场景中(如机器翻译),这个约束并不成立;
(3)CTC要求是输入序列的长度不小于标签数据的长度,反之便无法使用。
CTC Loss vs CE Loss:
CTC loss——优点,label制作非常简单;缺点,收敛速度一般CE loss——优点,收敛速度很快,很稳定;缺点,需帧级别的标签
6. CTC-Loss Pytorch实现
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction='mean')loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
Reference Paper:
《Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks》https://distill.pub/2017/ctc/https://arxiv.org/pdf/1507.05717v1.pdf