目录
1.效果展示和玩法场景
2.GeneFace++原理学习
3.数据集准备以及训练的过程
5.遇到的问题与解决方案
6.参考资料
一、效果展示
AI数字人进阶--GeneFace++(1)
AI数字人进阶--GeneFace++(2)
想象一下,一个专为你打造的AI数字人,不仅可以代表你在屏幕上出现,还能带来实实在在的商业价值。之前sadtalker照片说话的应用场景不同,定制的视频数字人的应用场景就不仅仅是娱乐,而可以带来更多价值:自媒体运营,短视频带货,数字人直播等等,现在抖音、视频号中看到的刘润等很多视频都是来自于其数字人。
由于其训练成本比较高,现在一般的玩法是提供模板视频任务,用户输入自己的文字或者语音,使用选择的模板生成对应的视频。也可以允许个人上传视频进行定制,单独收费。
二、GeneFace++原理学习
实现高嘴形对齐(lip-sync)、高视频真实度(video reality)、高系统效率(system efficiency)的虚拟人视频合成。
整体架构如下
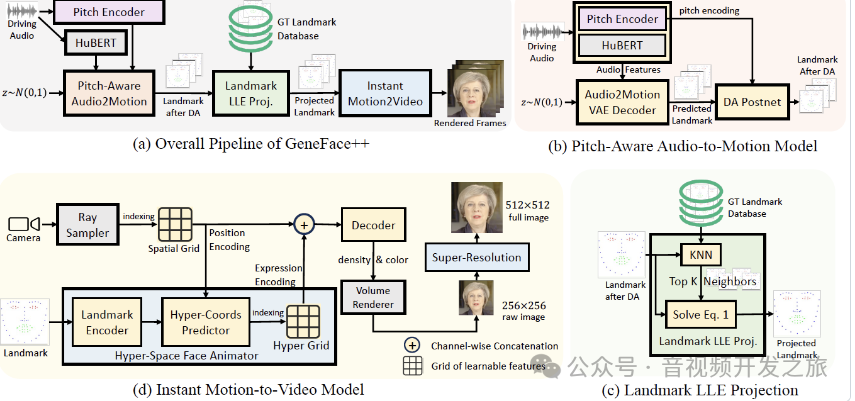
首先,处理输入的语音并提取关键特征,音高和语音
然后,预测说话时面部的动作,特别是嘴唇和面部表情
最后,这些预测被转换成视频帧,
通过一系列图像处理技术确保生成的视频真实和清晰
1. 音频处理
系统首先接收输入的语音,有两个关键部分:
音高编码器(Pitch Encoder):这个部分捕捉语音中的音高变化,因为音高(声音的高低)对理解说话者的情感和意图很重要。
HuBERT:HuBERT是Facebook开发的一种自监督学习模型,用于音频表示学习。用于从语音中提取更丰富的特征,如语速、重音、语音的节奏等,与音高信息结合,以预测面部动作。
2. 面部动作预测
音频信息会被用来预测人脸的动作,特别是嘴唇和面部表情。这个步骤包括:
音高感知音频到动作模型(Pitch-Aware Audio2Motion):这部分使用前面提取的音频特征来预测面部关键点的动作,关键点是面部的重要部位,如眼角、嘴角等。
Landmark LLE Proj:帮助模型理解不同面部关键点之间的关系,并确保预测的动作自然和准确。
3. 视频合成
系统将预测的面部动作转换为实际的视频帧。这一过程包括以下几个部分:
即时动作到视频模型(Instant Motion2Video):把预测的关键点动作转换成连续的视频帧,形成一个可以播放的视频。
超分辨率处理:为了确保生成的视频质量尽可能高,系统会对视频帧进行超分辨率处理,提升图像的清晰度和细节。
Volume Renderer:用于渲染三维数据以产生真实感的二维图像,增强视频的真实性。
三、数据集准备以及训练推理的过程
3.1 训练视频的要求
训练视频的质量直接影响了训练的结果,一般有下面几个重要的要求
1. 训练视频最好3-5分钟,每一帧都要人脸,头部要一直面对镜头,不能太偏;
2. 需要对录制视频进行预处理,降噪、音频重采样为16000HZ,视频裁剪为512*512,帧率25fps;
3. 裁剪后的视频要保证 头部在视频中占据相对较大的区域。
4. 推理的音频尽量和训练的语调保持一致,增加真实感
关于预处理部分,前面写了篇文章,提供了预处理脚本,可以直接使用
3.2 数据处理的脚本(音频特征提取、截帧、抠图、人脸landmark提取以及3dmm生成、将数据打包为npy)
export PYTHONPATH=./export VIDEO_ID=xxxexport CUDA_VISIBLE_DEVICES=0mkdir -p data/processed/videos/${VIDEO_ID}#音频特征提取(hubert以及mel)python data_gen/utils/process_audio/extract_hubert.py --video_id=${VIDEO_ID}python data_gen/utils/process_audio/extract_mel_f0.py --video_id=${VIDEO_ID}# 截帧、抠图mkdir -p data/processed/videos/${VIDEO_ID}/gt_imgsffmpeg -i data/raw/videos/${VIDEO_ID}.mp4 -vf fps=25,scale=w=512:h=512 -qmin 1 -q:v 1 -start_number 0 -v quiet data/processed/videos/${VIDEO_ID}/gt_imgs/%08d.jpgpython data_gen/utils/process_video/extract_segment_imgs.py --ds_name=nerf --vid_dir=data/raw/videos/${VIDEO_ID}.mp4 --force_single_process# 提取2D landmark用于之后Fit 3DMMpython data_gen/utils/process_video/extract_lm2d.py --ds_name=nerf --vid_dir=data/raw/videos/${VIDEO_ID}.mp4# Fit 3DMMpython data_gen/utils/process_video/fit_3dmm_landmark.py --ds_name=nerf --vid_dir=data/raw/videos/${VIDEO_ID}.mp4 --reset --debug --id_mode=global# 将数据打包python data_gen/runs/binarizer_nerf.py --video_id=${VIDEO_ID}
3.3 训练模型
需要分为两步,训练Head NeRF (头部)模型和Torso NeRF(躯干)模型
# 训练 Head NeRF 模型# 模型与tensorboard会被保存在 `checkpoints/<exp_name>`CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videoid/lm3d_radnerf_sr.yaml --exp_name=motion2video_nerf/videoid_head --reset# 训练 Torso NeRF 模型CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config=egs/datasets/videoid/lm3d_radnerf_torso_sr.yaml --exp_name=motion2video_nerf/videoid_torso --hparams=head_model_dir=checkpoints/motion2video_nerf/videoid_head --reset
如果从头开始训练加上-reset,否则去掉即可实现继续上次step继续训练
训练的过程比较耗时,4090显卡,两个模型都训练完大概需要十几个小时,需要注意训练过程中是否有log报错信息(代码中可能会catch,如果出现错误继续执行,可能存在训练模型异常),数据集的准备十分关键,如果准备不到位,很可能就要来来回回折腾很多次。第四节大家会看到一些由于训练视频数据问题导致的奇葩现象。
3.4 推理
推理就很快了,十几秒的视频生成也就十几秒钟的时间
推理脚本. (输入音频支持mp3,会重采样为16k)CUDA_VISIBLE_DEVICES=0 python inference/genefacepp_infer.py --head_ckpt= --torso_ckpt=checkpoints/motion2video_nerf/videoid_torso --drv_aud=data/raw/val_wavs/input.mp3 --out_name output.mp4
四、遇到的问题和解决方案
记录有价值的问题和解决方案,避免踩坑
4.1 工程类错误
(1)Inference ERROR: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
环境问题,按照readme重新创建venv环境
(2)数据处理环节提取图片时卡住
加上 --force_single_process可以解决
python data_gen/utils/process_video/extract_segment_imgs.py --ds_name=nerf --vid_dir=data/raw/videos/${VIDEO_ID}.mp4 --force_single_processhttps://github.com/yerfor/GeneFacePlusPlus/issues/98
(3) loss_output['ambient_loss'].item() AttributeError
Traceback (most recent call last):File "tasks/radnerfs/radnerf_sr.py", line 293, in _training_stepcurrent_ambient_loss = loss_output['ambient_loss'].item()AttributeError: 'int' object has no attribute 'item'| WARNING: ERROR calculating ambient loss| WARNING: ERROR calculating ambient loss
修改代码兼容即可
try:current_ambient_loss = loss_output['ambient_loss'].item()except AttributeError as e:current_ambient_loss = loss_output['ambient_loss']
4.2 效果类问题
(1)推理后的视频,人脸直接糊掉了

原因:人脸占的区域太小了,训练后效果很差,我这个视频原始宽高就比较小 544x900的,裁剪为512x512后,人脸区域就是很小,改为256x256就满足要求,但是需要对齐进行超分到512x512再进行训练
(2)推理后画质降低
可以尝试修改lm3d_radnerf_sr.yaml和lm3d_radnerf_torso_sr.yaml中的lambda_lpips_loss ,例如从 0.001 到 0.003。
https://github.com/yerfor/GeneFacePlusPlus/issues/29
五、参考资料
GeneFace++: Generalized and StableReal-Time 3D Talking Face Generation https://genefaceplusplus.github.io/
【AI数字人-论文】GeneFace++ https://blog.csdn.net/weixin_42111770/article/details/136052069
GeneFace++:https://github.com/yerfor/GeneFacePlusPlus/tree/main
GeneFace++保姆式训练教程 https://www.bilibili.com/video/BV1xx421f7PV/?spm_id_from=333.788.recommend_more_video.1&vd_source=03a763fa6cf49b01f658f32592f5a6f3AI数字人方案、多种解决方案全解析 https://www.bilibili.com/video/BV1KC4y137TT/?p=2&spm_id_from=pageDriverAI 数字人训练GeneFace++ https://www.bilibili.com/video/BV1LB421z76c/?vd_source=03a763fa6cf49b01f658f32592f5a6f3
感谢你的阅读
接下来我们继续学习输出AIGC相关内容,关注公众号“音视频开发之旅”,回复:“数字人” 获取资料,一起学习成长。
欢迎交流