本文按步骤详细介绍了使用yolov5进行目标检测的全流程,包括:模型下载、环境配置、数据集准备和数据预处理、模型调整、模型训练、进行目标检测和检测结果分析。本文全部流程使用cpu完成(无需gpu),旨在跑通流程,模型训练过程较慢,且未能到达最优结果。需要 python版本>=3.8。
1. 模型下载
在github上进行模型下载:https://github.com/ultralytics/yolov5
2. 配置环境
首先在pycharm中新建一个Project,我们取名叫deeplearn。将下上步中下载好的yolov5-master.zip解压在该目录中。
在Anaconda prompt中切换到 '.\deeplearn\yolov5-master' 目录下,执行下面的指令安装所有需要的包(此处建议用清华镜像安装,不然会很慢):
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt安装完成显示successfully。

3.数据预处理和配置
需要将我们的训练数据处理成yolov5支持的形式,并配置相应目录。yolov5支持的标签为 txt 格式,yml格式标签转txt格式详见文章:待补充。
3.1 建立数据集目录
首先,数据目录结构如下:
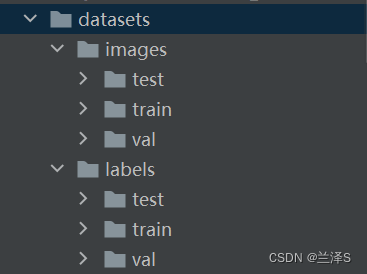
我们将图片放在images文件夹中相应的训练/验证/测试文件夹下,标签放在labels文件夹中相应的文件夹下。
图片为 jpg 格式,标签为 txt 格式。一张图片对应一个txt标签文件。txt文件的每行标识了图片中的每个目标的类别和位置信息,详情如下:
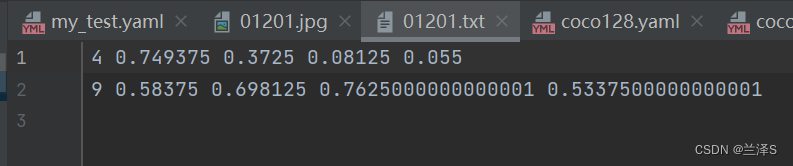
其中,每行包含5个字段,分别为:
(1)类别编号(直接用名称会报错),名称转编号可参考如下脚本;
待补充
(2)图框中心点的相对横坐标x(即图框中心点横坐标/图片宽度);
(3)图框中心点的相对纵坐标;
(4)图框相对宽度(即图框宽度/图片宽度);
(5)图框相对高度。
3.2 配置yolov5中的数据文件
打开 'yolov5-master/data' 路径,找到coco128.yaml,复制一份并重命名为 my_test.yaml。
修改path参数为images和labels文件夹所在目录,修改train参数为 ./images/train,val参数为:./images/val,test参数为 ./images/test,(注意保留:后的空格),详见下图:
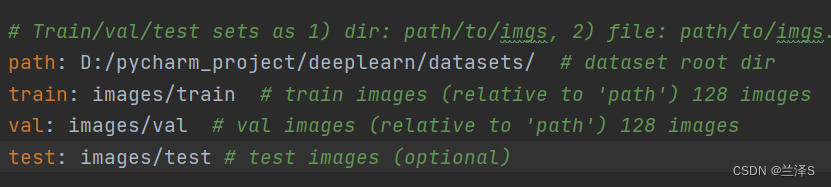
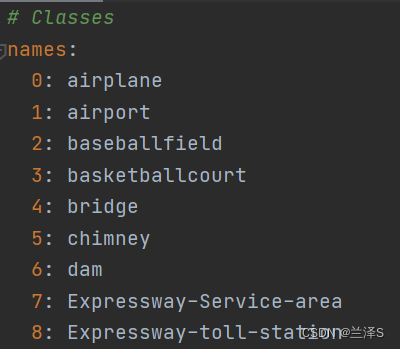
修改names为我们用的数据的类别序号和相应类别名称。
4.模型调整
打开 'yolov5-master/model' 目录下的 yolov5s.yaml 文件,里面即是我们用到的目标检测模型结构(注:如果用yolov5的其它模型也同理调整,yolov5s、m、l、x模型为从小到大的模型,训练速度从快到慢,效果越来越好。yolov5n是一个折中的新版本,速度比yolov5m快,效果也比它好)。
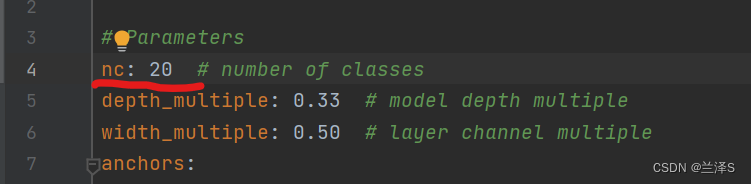
将参数nc改成我们的数据的类别总数 20。如下图:
进行其它简单的模型结构相关调整也在这个文件里。
5. 模型训练
复制一份 .yolov5-master 目录下的 train.py 文件,命名为 my_train.py 。找到第442行 parse_opt() 函数。
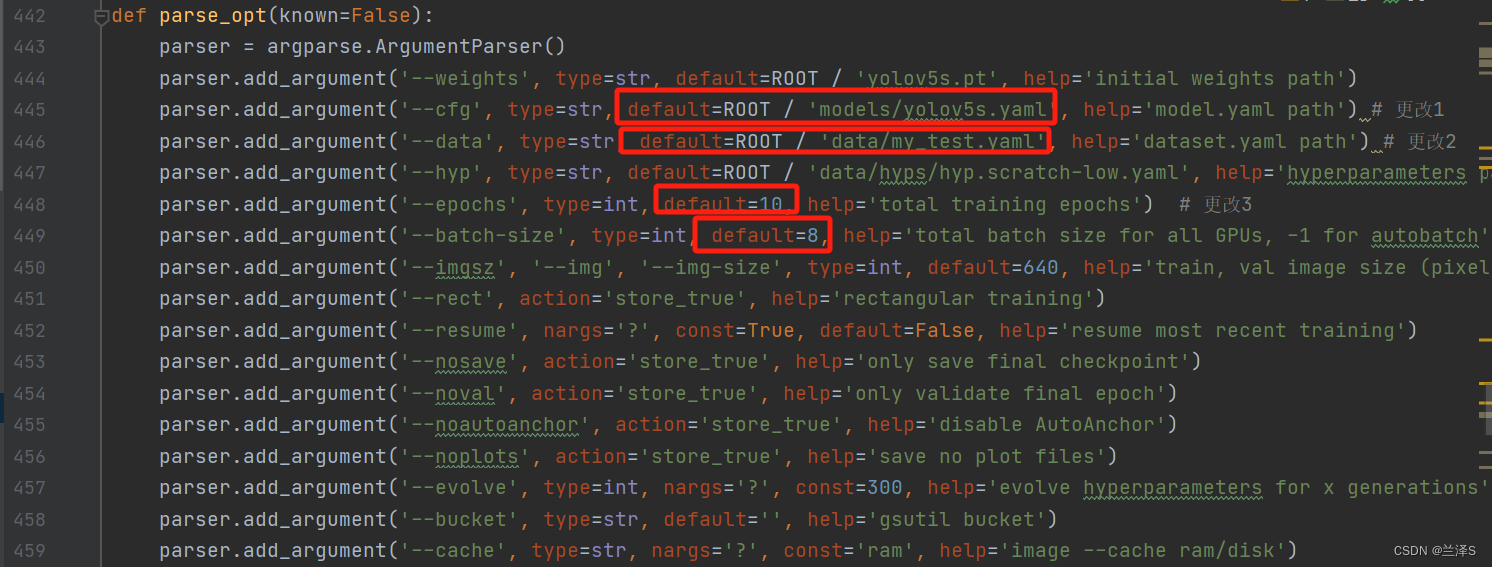
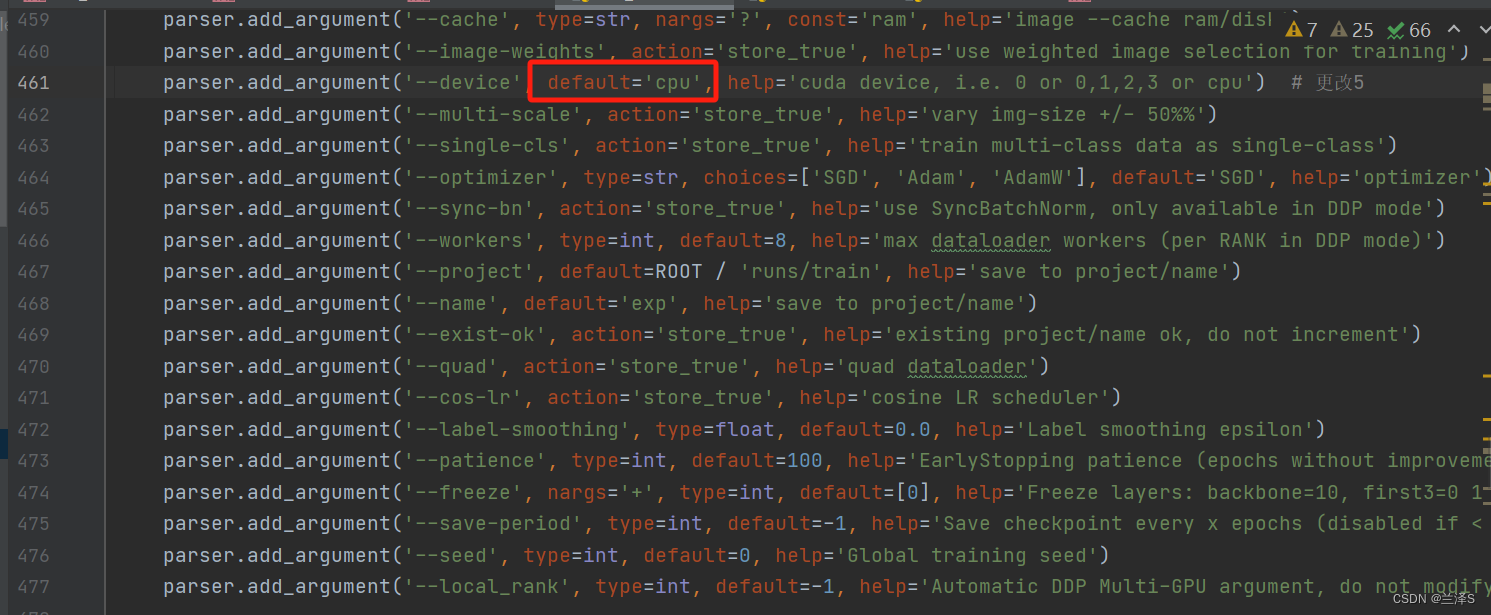
一些必须修改的关键参数已用红框标识:
(1)第445行:--cfg:修改为我们的训练模型配置文件
(2)第446行:--data:修改为我们的训练数据配置文件
(3)第448行:--epochs:训练轮数,需要配置合理的训练轮数,保证模型收敛。(可根据训练结果判断模型是否收敛,详见本文训练结果分析章节)
(4)第449行:--batch-size:批文件数。
(5)第461行:--device:选择用gpu还是cpu运行。本处修改为用cpu运行。如果装了cuda可以用gpu,速度会加快。
还有一些其它常用参数为:
(6)第444行:--weights:模型的初始权重,不做修改会自动下载一份。自行下载相应权重并配置路径。
(7)第464行:--optimizer:模型训练使用的优化器
在my_train.py所在目录下,执行 python my_train.py
会自动下载一份模型的初始参数:

加载完初始参数后,开始训练

第1个epoch,只用gpu训练是真的慢。不过好在跑起来了,坐等结果。1个epoch约20min,10个200min,差不多需要3.5个小时。可以通过增大batch_size减少运行时间。

运行结束:
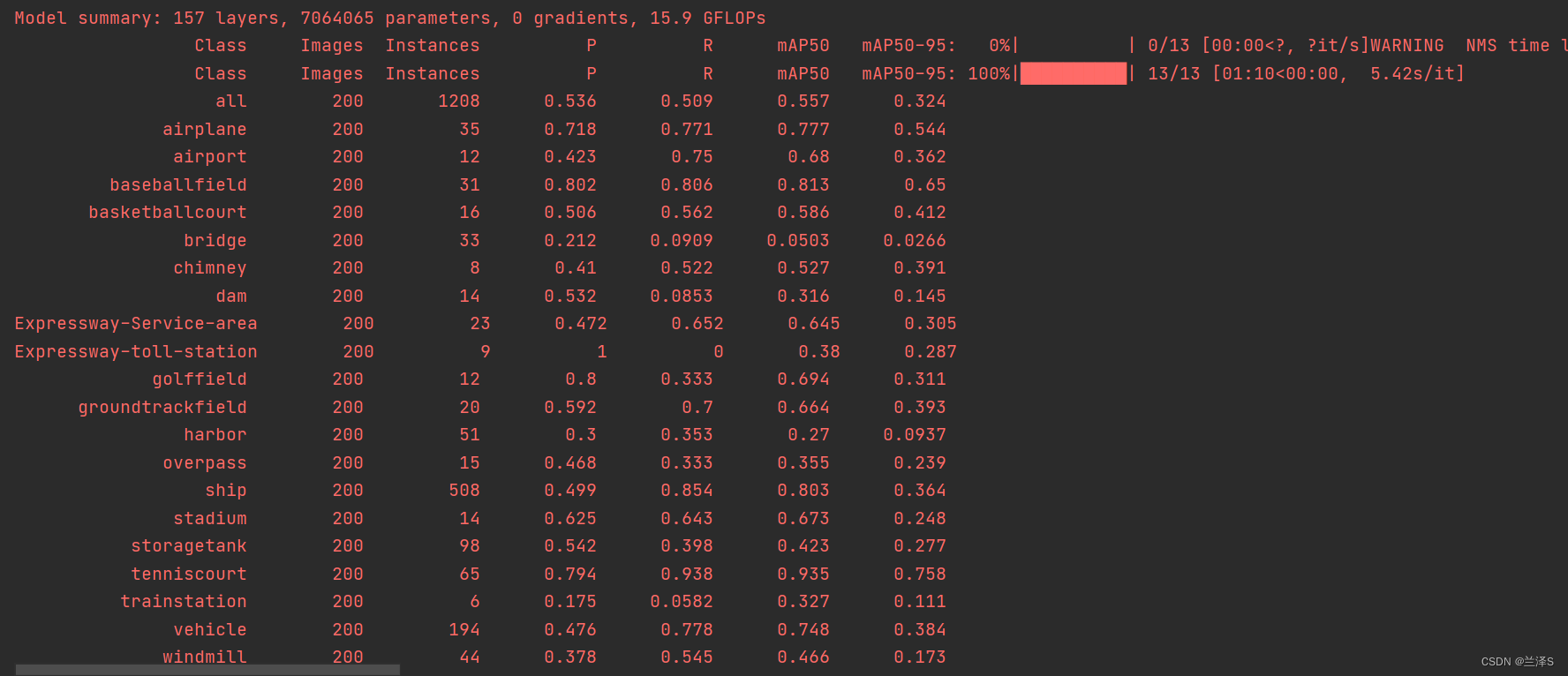
结果在 runs\train\exp4中
6.结果查看
运行结果在 .\runs\train\exp4 目录下,包括
(1)模糊矩阵
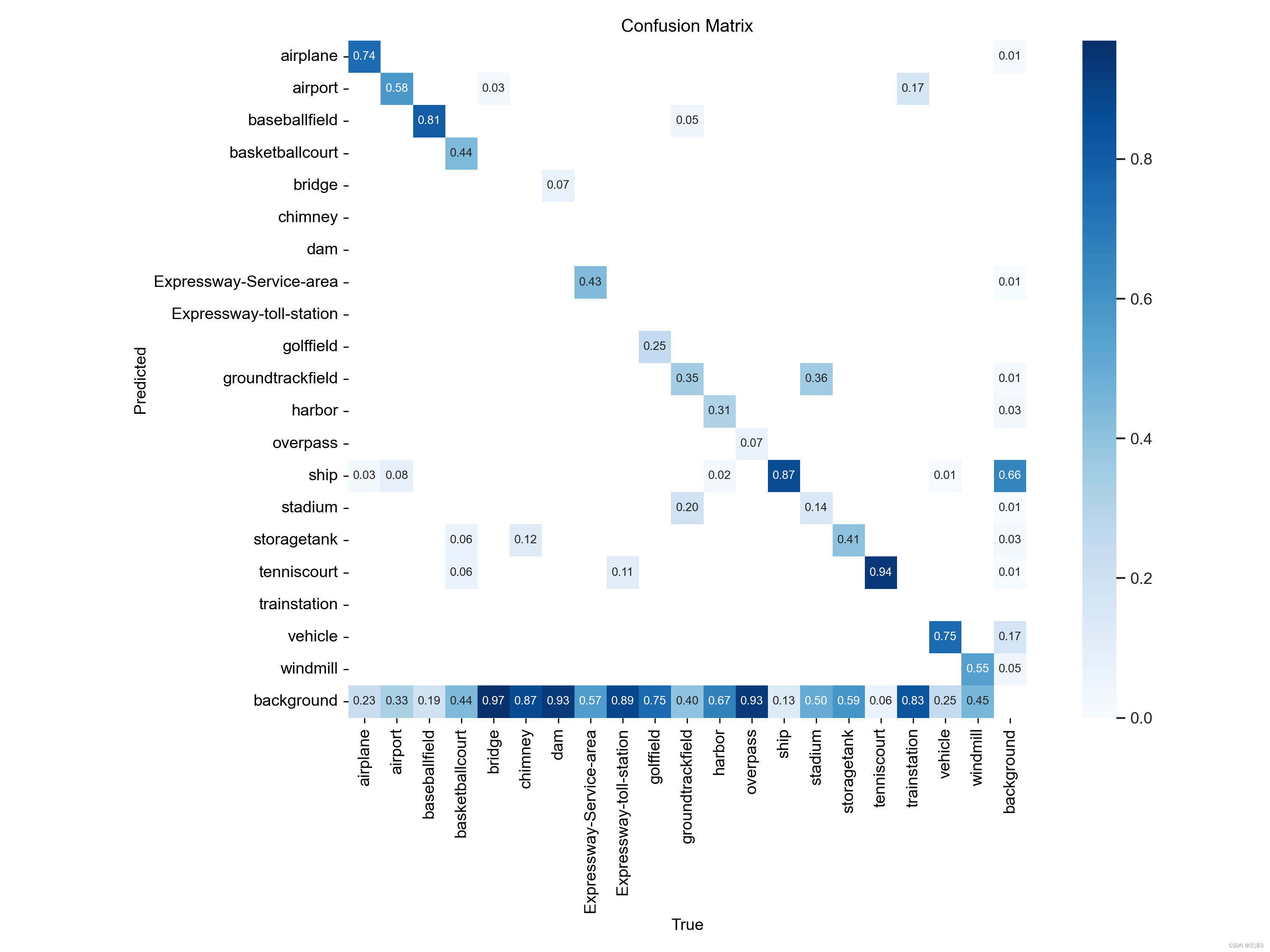
(2)损失函数:
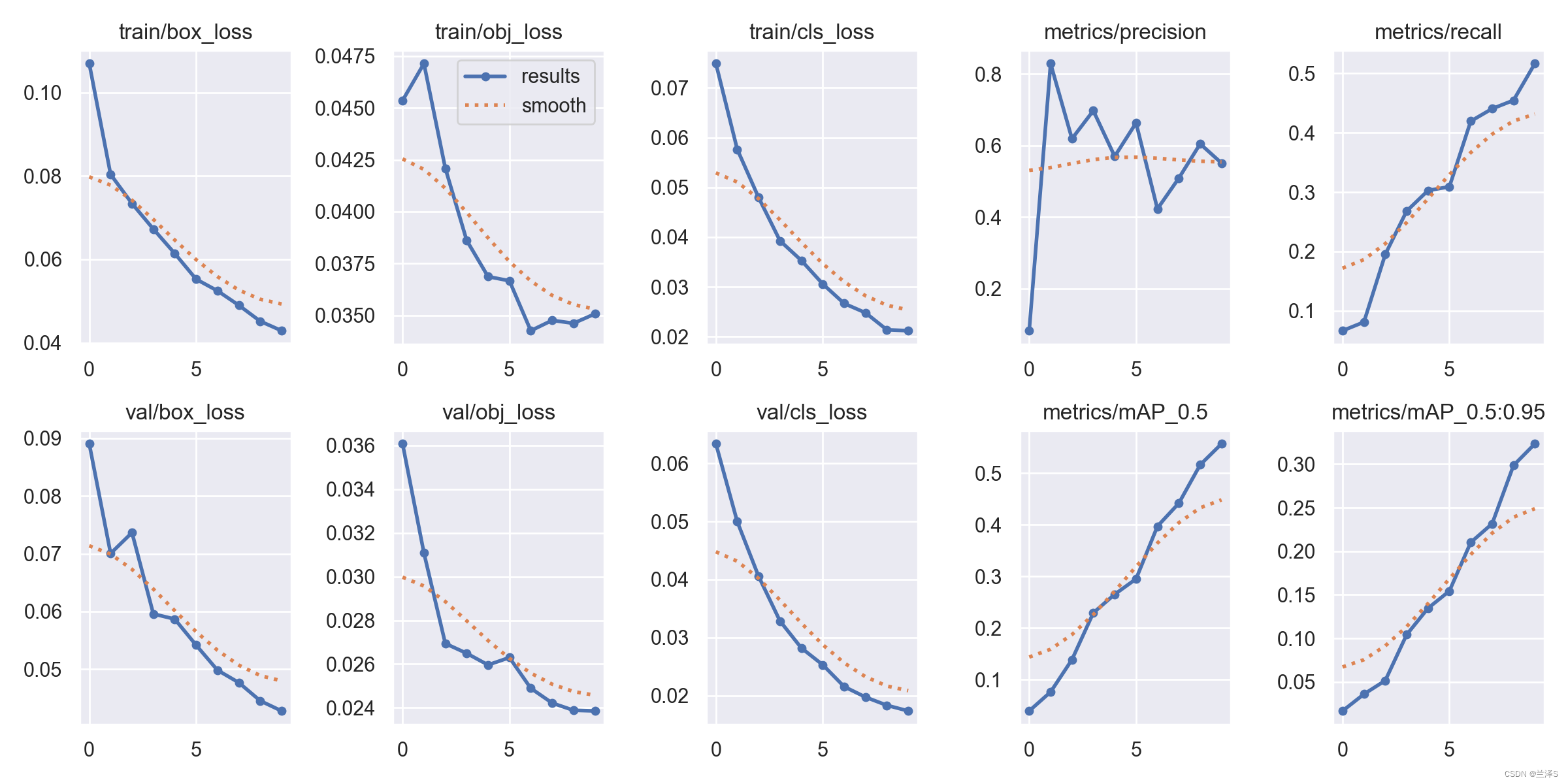
从损失函数上可以看出我们的模型训练没有收敛,因为数据量小且训练训练轮次少。(受时间和资源限制,就先这样了)
(3)可以看下在验证集上的结果:
真实标签如下图所示

我们训练好的模型在验证集上的预测结果为:

7.目标检测
(1)复制一份 detect.py 文件命名为 my_detect.py。
找到第242行:parse_opt()函数,进行如下调整:
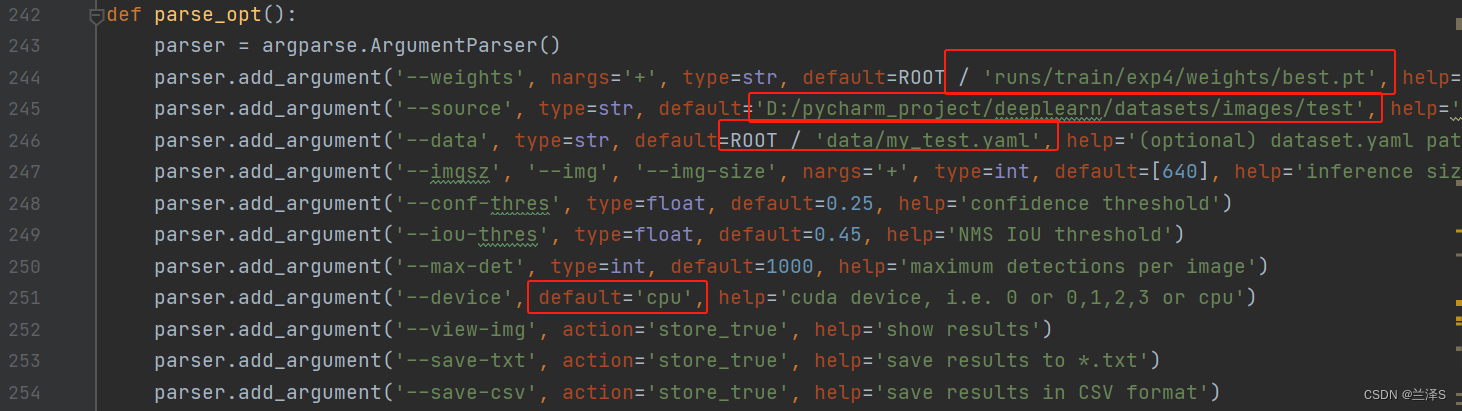
-- weights:改成我们训练好的最佳权重的路径
-- source:改成待检测图片所在目录
--data:改成我们配置的数据 yaml 文件
--device: 改成cpu
其他参数:
--conf-thres: 置信度阈值,检测结果的置信度高于该阈值。提高该值会减少检测出的目标数。默认值0.25是一个常用的经验参数。
--iou-thres: iou阈值,用于控制非极大值抑制(NMS)中的边界框合并阈值,即两个框的iou值高于该阈值,两个框进行合并。提高该值会增加检测出的目标数。默认值0.45是一个常用的经验参数。
(2)进一步,如果需要调整输出的内容,可以先找到第187行,'if save_txt'处:

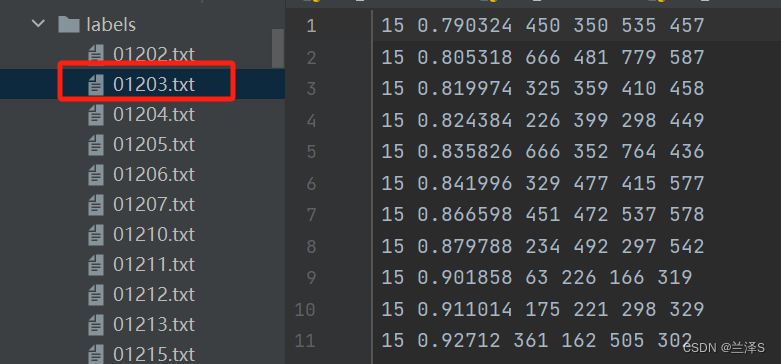
从第189行,可以看出,加上 --save-conf 后,其输出结果按顺序为:类别编号,图框中心点的相对横坐标x(即图框中心点横坐标/图片宽度),图框中心点的相对纵坐标,图框相对宽度(即图框宽度/图片宽度),图框相对高度,置信度。
如果我们希望输出的结果是:类别编号,置信度,x0,y0,x1,y1。则可以将第189行相应改为:
line = (cls, conf, *xyxy) if save_conf else (cls, *xywh) 执行:
python my_detect.py --save-txt --save-conf加上 --save-txt 表示输出目标检测结果的txt文件,其标准输出结果同训练数据的标签。
加上 --save-conf 表示检测结果的txt文件中包含检测的置信度。

对每个测试集图片的检测结果txt文件在labels目录下,内容如下:
其在原图上的检测框表示在exp2目录下:

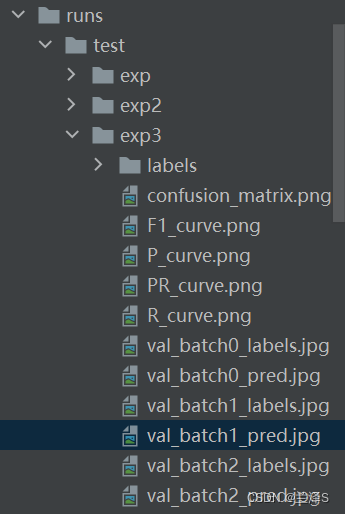
8.查看在测试集上的表现
找到 yolov5-master/val.py,复制一份命名为 my_test.py。找到第342行 parse_opt(),并进行如下修改:
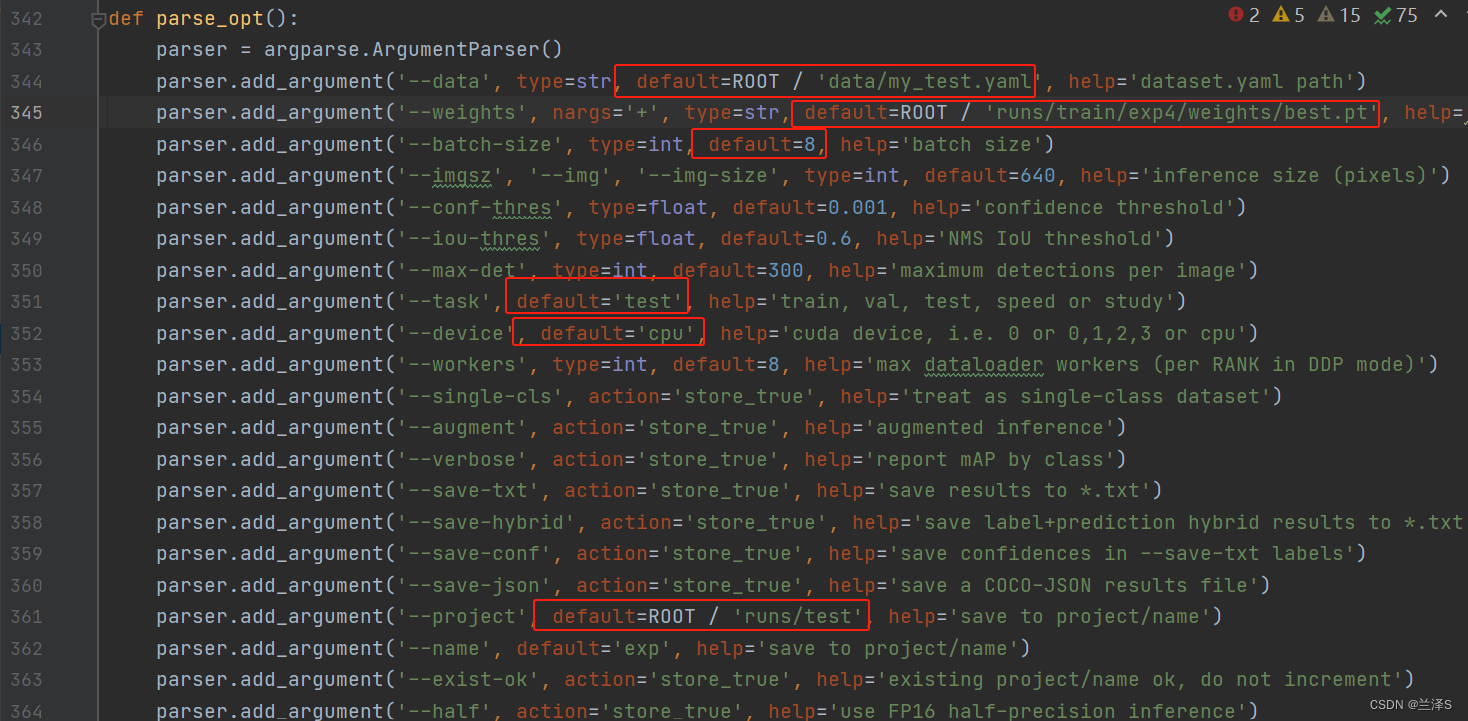
(1)第334行:--data:需要改为我们的数据配置yaml文件
(2)第345行:--weights:需要修改为我们训练后的最佳权重
(3)第346行:--batch-size:可以改为和之前一致的8
(4)第351行:--task:取值 test
(5)第352行:--device:使用gpu
(6)第361行:--project:检测结果存储的目录
(7)--conf-thres、--iou-thres:改成检测时用的值(截图里忘改了)
之后在Terminal中,yolov5-master目录下执行指令:
加上 --save-txt 表示输出目标检测结果的txt文件,加上 --save-conf 表示检测结果的txt文件中包含置信度。
python my_test.py --save-txt --save-conf运行结果如下:
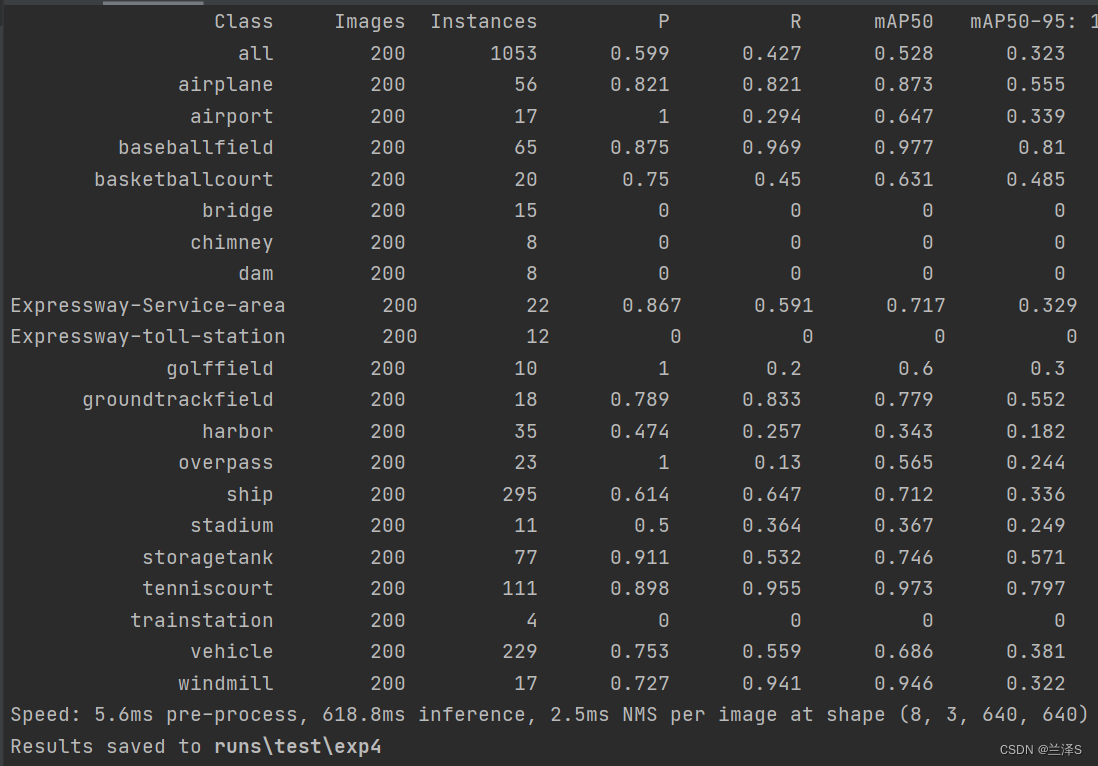
可以看到相应检测结果结果在 runs\test\exp3目录下,包括检测结果、检测框标记、混淆矩阵、F1曲线、PR曲线等。