前言
PaddleOCR 提供了基于深度学习的文本检测、识别和方向检测等功能。其主要推荐的 PP-OCR 算法在国内外的企业开发者中得到广泛应用。在短短的几年时间里,PP-OCR 的累计 Star 数已经超过了32.2k,常常出现在 GitHub Trending 和 Paperswithcode 的日榜和月榜第一位,被认为是当前OCR领域最热门的仓库之一。
PaddleOCR 最初主打的 PP-OCR 系列模型在去年五月份推出了 v3 版本。最近,飞桨 AI 套件团队对 PP-OCRv3 进行了全面改进,推出了重大更新版本 PP-OCRv4。这个新版本预计带来了更先进的技术、更高的性能和更广泛的适用性,将进一步推动OCR技术在各个领域的应用。
PP-OCRv4在速度可比情况下,中文场景端到端 Hmean 指标相比于 PP-OCRv3提升4.25%,效果大幅提升。具体指标如下表所示:
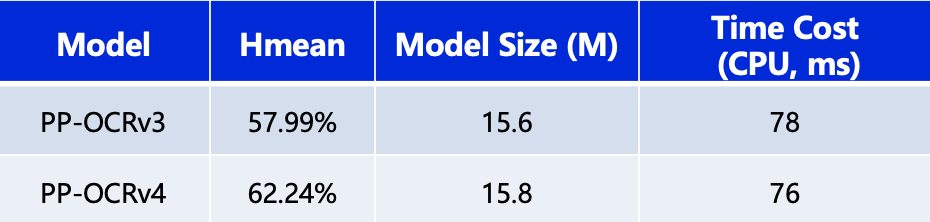
测试环境:CPU 型号为 Intel Gold 6148,CPU 预测时使用 OpenVINO。
除了更新中文模型,本次升级也优化了英文数字模型,在自有评估集上文本识别准确率提升6%,如下表所示:
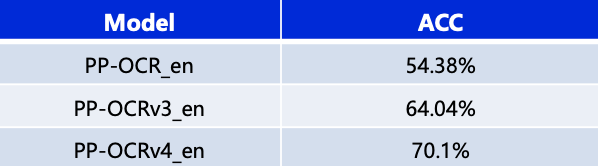
同时,也对已支持的80余种语言识别模型进行了升级更新,在有评估集的四种语系识别准确率平均提升5%以上,如下表所示:
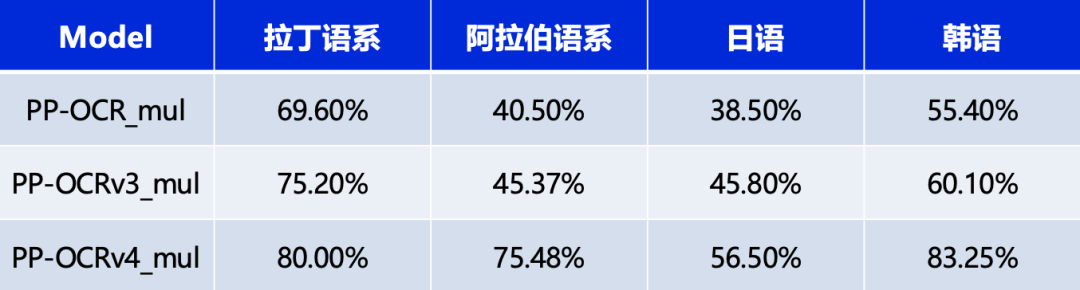
一、模型转换
1.模型下载
从https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7 下载要用到的模型,要下载的模型有文本检测模型、文字方向模型、文字识别模型,我这里只下下载了文本检测与文字识别的模型。

下载好的模型nference.pdiparams为模型参数文件,inference.pdmodel为模型结构文件,这两个文件在转换onnx的时候都要用到。
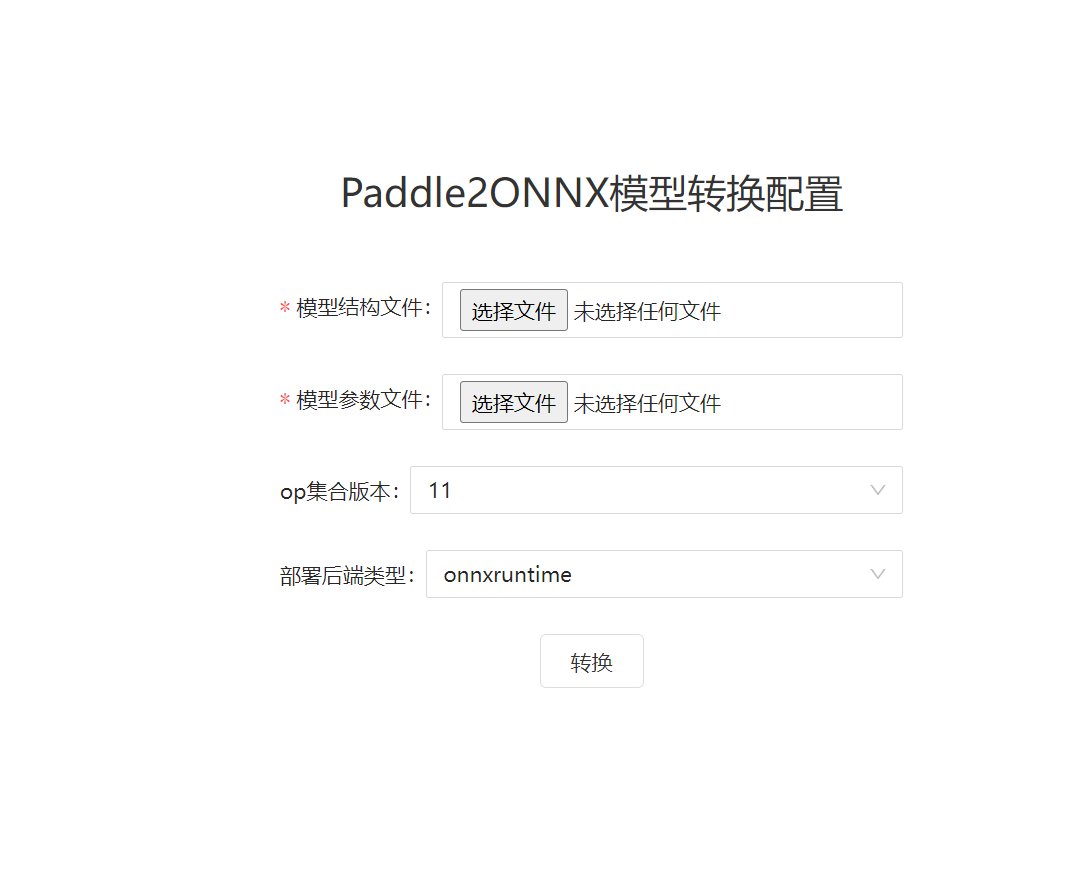
2.模型转成onnx
使用paddle2ONNX进行模型转换,git地址:https://github.com/paddlepaddle/paddle2onnx, 下载源码然后编译转换,也可以使用在线转换的方法,如果嫌麻烦,最好使用在线的转换方法,在线地址:https://www.paddlepaddle.org.cn/paddle/visualdl/modelconverter/x2paddle
3. onnx转ncnn模型
这里为了之后在移动部署做准备,选择使用NCNN做最终的模型推理,NCNN封装了很高效的API接品,可以方便地在移动设备和嵌入式系统上进行神经网络的部署和推理。适用于移动设备和嵌入式设备。它被设计用于在各种硬件平台上高效地运行神经网络推断(inference)。NCNN主要特点包括:
轻量级和高效性: NCNN被设计为一个轻量级框架,具有高度优化的推断性能。它的设计目标是在移动设备和嵌入式设备上实现高效的神经网络推理。
跨平台支持: NCNN支持多种硬件平台,包括CPU、GPU、DSP等,并且可以在各种操作系统上运行,如Windows、Android、iOS、Linux等。
优化和硬件加速: NCNN对各种硬件进行了优化,并利用硬件加速特性提高了神经网络推断的性能。
丰富的模型支持: NCNN支持各种常见的深度学习模型,如AlexNet、VGG、ResNet、MobileNet等,并且兼容一些深度学习框架导出的模型,Caffe、TensorFlow、ONNX等。
可以从https://github.com/Tencent/ncnn 获取源码进行编译,也可以下载官方编译好的lib进行转换,还可以使用在线接口进行转换。在线接地址:https://convertmodel.com/。
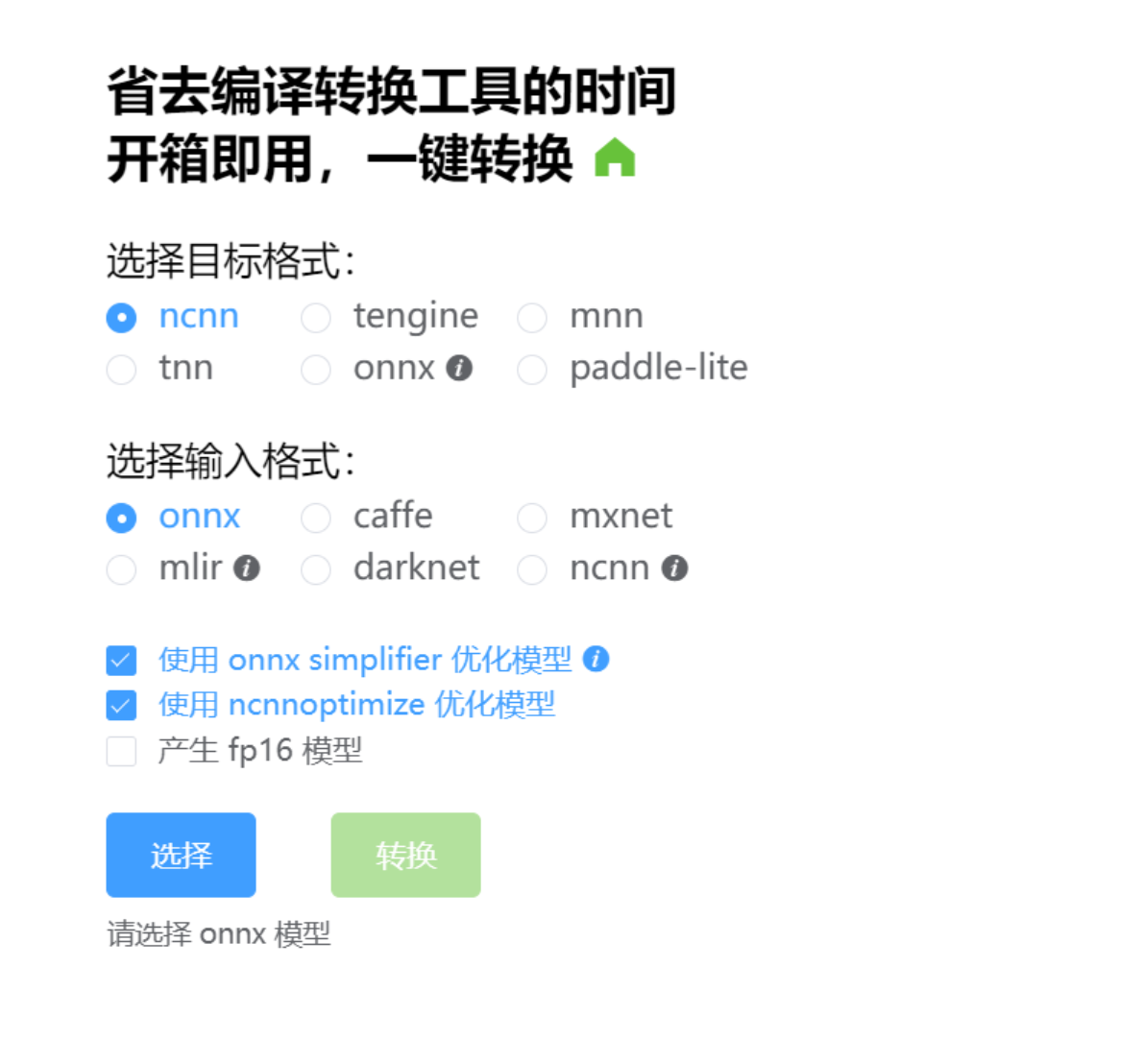
转出来的模型后缀是.param和.bin文件。
二、文本检测
文本检测是旨在从图像或视频中准确地检测和定位文本的位置和边界框,OCR系统中的一个重要组成部分,它为后续的文本识别提供了定位和定界的信息。
预处理:对输入的图像进行预处理,可能包括图像增强、去噪、尺寸标准化等操作,以便更好地适应文本检测算法。
文本区域检测:使用特定的算法或模型来检测图像中可能包含文本的区域。常见的方法包括基于区域的方法(如基于区域的CNN(R-CNN)系列)、基于锚点的方法(如SSD和YOLO)、以及基于注意力机制的方法(如EAST、TextBoxes++等)。
后处理:在获取文本区域的初始预测结果后,可以进行后处理步骤来提高检测的准确性和稳定性。这可能包括非极大值抑制(NMS)来消除重叠的边界框、边框回归以精细调整边界框的位置等。
文本检测类:
#ifndef __OCR_DBNET_H__#define __OCR_DBNET_H__#include "base_struct.h"#include <ncnn/net.h>#include <vector>#include <ncnn/cpu.h>namespace NCNNOCR{ class DbNet { public: DbNet(); ~DbNet() {}; int read_model(std::string param_path = "data/det.param", std::string bin_path = "data/det.bin", bool use_gpu = true); bool detect(cv::Mat& src, std::vector<TextBox>& results, int _target_size = 1024); private: ncnn::Net net; const float meanValues[3] = { 0.485 * 255, 0.456 * 255, 0.406 * 255 }; const float normValues[3] = { 1.0 / 0.229 / 255.0, 1.0 / 0.224 / 255.0, 1.0 / 0.225 / 255.0 }; float boxThresh = 0.3f; float boxScoreThresh = 0.5f; float unClipRatio = 2.0f; int target_size; };}#endif //__OCR_DBNET_H__类实现:
#include "db_net.h"#include "tools.h"namespace NCNNOCR{ int DbNet::read_model(std::string param_path, std::string bin_path, bool use_gpu) { ncnn::set_cpu_powersave(2); ncnn::set_omp_num_threads(ncnn::get_big_cpu_count()); net.opt = ncnn::Option();#if NCNN_VULKAN net.opt.use_vulkan_compute = use_gpu;#endif net.opt.lightmode = true; net.opt.num_threads = ncnn::get_big_cpu_count(); int rp = net.load_param(param_path.c_str()); int rb = net.load_model(bin_path.c_str()); if (rp == 0 || rb == 0) { return false; } return true; } std::vector<TextBox> inline findRsBoxes(const cv::Mat& fMapMat, const cv::Mat& norfMapMat, const float boxScoreThresh, const float unClipRatio) { const float minArea = 3; std::vector<TextBox> rsBoxes; rsBoxes.clear(); std::vector<std::vector<cv::Point>> contours; cv::findContours(norfMapMat, contours, cv::RETR_LIST, cv::CHAIN_APPROX_SIMPLE); for (int i = 0; i < contours.size(); ++i) { float minSideLen, perimeter; std::vector<cv::Point> minBox = getMinBoxes(contours[i], minSideLen, perimeter); if (minSideLen < minArea) continue; float score = boxScoreFast(fMapMat, contours[i]); if (score < boxScoreThresh) continue; //---use clipper start--- std::vector<cv::Point> clipBox = unClip(minBox, perimeter, unClipRatio); std::vector<cv::Point> clipMinBox = getMinBoxes(clipBox, minSideLen, perimeter); //---use clipper end--- if (minSideLen < minArea + 2) continue; for (int j = 0; j < clipMinBox.size(); ++j) { clipMinBox[j].x = (clipMinBox[j].x / 1.0); clipMinBox[j].x = (std::min)((std::max)(clipMinBox[j].x, 0), norfMapMat.cols); clipMinBox[j].y = (clipMinBox[j].y / 1.0); clipMinBox[j].y = (std::min)((std::max)(clipMinBox[j].y, 0), norfMapMat.rows); } rsBoxes.emplace_back(TextBox{ clipMinBox, score }); } reverse(rsBoxes.begin(), rsBoxes.end()); return rsBoxes; } bool DbNet::detect(cv::Mat& src, std::vector<TextBox>& results_, int _target_size) { target_size = _target_size; int width = src.cols; int height = src.rows; int w = width; int h = height; float scale = 1.f; const int resizeMode = 0; // min = 0, max = 1 if (resizeMode == 1) { if (w < h) { scale = (float)target_size / w; w = target_size; h = h * scale; } else { scale = (float)target_size / h; h = target_size; w = w * scale; } } else if (resizeMode == 0) { if (w > h) { scale = (float)target_size / w; w = target_size; h = h * scale; } else { scale = (float)target_size / h; w = w * scale; h = target_size; } } ncnn::Extractor extractor = net.create_extractor(); ncnn::Mat out; cv::Size in_pad_size; int wpad = (w + 31) / 32 * 32 - w; int hpad = (h + 31) / 32 * 32 - h; ncnn::Mat in_pad_; ncnn::Mat input = ncnn::Mat::from_pixels_resize( src.data, ncnn::Mat::PIXEL_RGB, width, height, w, h); // pad to target_size rectangle ncnn::copy_make_border(input, in_pad_, hpad / 2, hpad - hpad / 2, wpad / 2, wpad - wpad / 2, ncnn::BORDER_CONSTANT, 0.f); in_pad_.substract_mean_normalize(meanValues, normValues); in_pad_size = cv::Size(in_pad_.w, in_pad_.h); extractor.input("x", in_pad_); extractor.extract("sigmoid_0.tmp_0", out); // ncnn::Mat flattened_out = out.reshape(out.w * out.h * out.c); //-----boxThresh----- cv::Mat fMapMat(in_pad_size.height, in_pad_size.width, CV_32FC1, (float*)out.data); cv::Mat norfMapMat; norfMapMat = fMapMat > boxThresh; cv::Mat element = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(2, 2)); cv::dilate(norfMapMat, norfMapMat, element, cv::Point(-1, -1), 1); std::vector<TextBox> results = findRsBoxes(fMapMat, norfMapMat, boxScoreThresh, unClipRatio); for (int i = 0; i < results.size(); i++) { for (int j = 0; j < results[i].boxPoint.size(); j++) { float x = float(results[i].boxPoint[j].x - (wpad / 2)) / scale; float y = float(results[i].boxPoint[j].y - (hpad / 2)) / scale; x = std::max(std::min(x, (float)(width - 1)), 0.f); y = std::max(std::min(y, (float)(height - 1)), 0.f); results[i].boxPoint[j].x = (int)x; results[i].boxPoint[j].y = (int)y; } if (abs(results[i].boxPoint[0].x - results[i].boxPoint[1].x) <= 3) { continue; } if (abs(results[i].boxPoint[0].y - results[i].boxPoint[3].y) <= 3) { continue; } results_.push_back(results[i]); } return true; } DbNet::DbNet() { }}检测结果:


三、文字识别
1. OCR
文字识别是将印刷或手写文本转换为可文本,被广泛应用于各种领域,包括数字化档案管理、自动化数据录入、图像搜索、身份验证、自动车牌识别、票据处理、手写文字识别。
类声明:
#ifndef __OCR_CRNNNET_H__#define __OCR_CRNNNET_H__#include "base_struct.h"#include <ncnn/net.h>#include <opencv2/opencv.hpp>#include <vector>#include <ncnn/cpu.h>#include <fstream>namespace NCNNOCR{ class CrnnNet { public: CrnnNet(); ~CrnnNet() {}; int read_model(std::string param_path = "data/ch_recv4.ncnn.param", std::string bin_path = "data/ch_recv4.ncnn.bin", std::string key_path = "data/dict_chi_sim.txt", bool use_gpu = false); int read_keys(std::string key_path); bool detect(cv::Mat& src, TextLine& result); bool detect(std::vector<cv::Mat>& src, std::vector<TextLine>& results); private: TextLine scoreToTextLine(const std::vector<float>& outputData, int h, int w); private: ncnn::Net net; const int dstHeight = 48; const int dstWidth = 320; const float meanValues[3] = { 127.5, 127.5, 127.5 }; const float normValues[3] = { 1.0 / 127.5, 1.0 / 127.5, 1.0 / 127.5 }; std::vector<std::string> keys; };}#endif //__OCR_DBNET_H__类实现:
#include "crnn_net.h"namespace NCNNOCR{ template<class ForwardIterator> inline static size_t argmax(ForwardIterator first, ForwardIterator last) { return std::distance(first, std::max_element(first, last)); } int CrnnNet::read_model(std::string param_path, std::string bin_path, std::string key_path, bool use_gpu) { ncnn::set_cpu_powersave(2); ncnn::set_omp_num_threads(ncnn::get_big_cpu_count()); net.opt = ncnn::Option();#if NCNN_VULKAN net.opt.use_vulkan_compute = use_gpu;#endif net.opt.num_threads = ncnn::get_big_cpu_count(); int rp = net.load_param(param_path.c_str()); int rb = net.load_model(bin_path.c_str()); int rk = read_keys(key_path); if (rp == 0 || rb == 0 || rk == 0) { return false; } return true; } int CrnnNet::read_keys(std::string key_path) { std::ifstream in(key_path.c_str()); std::string line; if (in) { while (getline(in, line)) {// line中不包括每行的换行符 keys.push_back(line); } } else { printf("The keys.txt file was not found\n"); } keys.insert(keys.begin(), "#"); keys.emplace_back(" "); return keys.size(); }; TextLine CrnnNet::scoreToTextLine(const std::vector<float>& outputData, int h, int w) { int keySize = keys.size(); std::string strRes; std::vector<float> scores; int lastIndex = -1; int maxIndex; float maxValue; for (int i = 0; i < h; i++) { maxIndex = 0; maxValue = -1000.f; maxIndex = int(argmax(outputData.begin() + i * w, outputData.begin() + i * w + w)); maxValue = float(*std::max_element(outputData.begin() + i * w, outputData.begin() + i * w + w)); // / partition; if (maxIndex > 0 && maxIndex < keySize && (!(maxIndex == lastIndex))) { /* std::cout << maxIndex << std::endl;*/ scores.emplace_back(maxValue); //std::cout << keys[maxIndex] << std::endl; strRes.append(keys[maxIndex]); } lastIndex = maxIndex; } return { strRes, scores }; } bool CrnnNet::detect(cv::Mat& src, TextLine& result) { int resized_w = 0; float ratio = src.cols / float(src.rows); resized_w = ceil(dstHeight * ratio); cv::Size tmp = cv::Size(resized_w, dstHeight); ncnn::Mat input = ncnn::Mat::from_pixels_resize(src.data, ncnn::Mat::PIXEL_BGR2RGB, src.cols, src.rows, tmp.width, tmp.height); input.substract_mean_normalize(meanValues, normValues); ncnn::Extractor extractor = net.create_extractor(); extractor.input("in0", input); ncnn::Mat out; extractor.extract("out0", out); float* floatArray = (float*)out.data; std::vector<float> outputData(floatArray, floatArray + out.h * out.w); result = scoreToTextLine(outputData, out.h, out.w); return true; } bool CrnnNet::detect(std::vector<cv::Mat>& src, std::vector<TextLine>& results) { int sizeLen = src.size(); // results.resize(sizeLen); for (size_t i = 0; i < sizeLen; i++) { TextLine textline; if (detect(src[i], textline)) { results.emplace_back(textline); } else { return false; } } return true; } CrnnNet::CrnnNet() { }}2.在图像画中文
识别后,想要比对识别的结果,可以把文字画到当前图像,但OpenCV没有提供画中文的方法,甩以要自己写一个画中文的方法:
#include "put_text.h"void get_string_size(HDC hDC, const char* str, int* w, int* h){SIZE size;GetTextExtentPoint32A(hDC, str, strlen(str), &size);if (w != 0) *w = size.cx;if (h != 0) *h = size.cy;}void put_text_ch(Mat &dst, const char* str, Point org, Scalar color, int fontSize, const char* fn, bool italic, bool underline){CV_Assert(dst.data != 0 && (dst.channels() == 1 || dst.channels() == 3));int x, y, r, b;if (org.x > dst.cols || org.y > dst.rows) return;x = org.x < 0 ? -org.x : 0;y = org.y < 0 ? -org.y : 0;LOGFONTA lf;lf.lfHeight = -fontSize;lf.lfWidth = 0;lf.lfEscapement = 0;lf.lfOrientation = 0;lf.lfWeight = 5;lf.lfItalic = italic; //斜体lf.lfUnderline = underline; //下划线lf.lfStrikeOut = 0;lf.lfCharSet = DEFAULT_CHARSET;lf.lfOutPrecision = 0;lf.lfClipPrecision = 0;lf.lfQuality = PROOF_QUALITY;lf.lfPitchAndFamily = 0;strcpy_s(lf.lfFaceName, fn);HFONT hf = CreateFontIndirectA(&lf);HDC hDC = CreateCompatibleDC(0);HFONT hOldFont = (HFONT)SelectObject(hDC, hf);int strBaseW = 0, strBaseH = 0;int singleRow = 0;char buf[1 << 12];strcpy_s(buf, str);char *bufT[1 << 12]; // 这个用于分隔字符串后剩余的字符,可能会超出。 //处理多行{int nnh = 0;int cw, ch;const char* ln = strtok_s(buf, "\n", bufT);while (ln != 0){get_string_size(hDC, ln, &cw, &ch);strBaseW = max(strBaseW, cw);strBaseH = max(strBaseH, ch);ln = strtok_s(0, "\n", bufT);nnh++;}singleRow = strBaseH;strBaseH *= nnh;}if (org.x + strBaseW < 0 || org.y + strBaseH < 0){SelectObject(hDC, hOldFont);DeleteObject(hf);DeleteObject(hDC);return;}r = org.x + strBaseW > dst.cols ? dst.cols - org.x - 1 : strBaseW - 1;b = org.y + strBaseH > dst.rows ? dst.rows - org.y - 1 : strBaseH - 1;org.x = org.x < 0 ? 0 : org.x;org.y = org.y < 0 ? 0 : org.y;BITMAPINFO bmp = { 0 };BITMAPINFOHEADER& bih = bmp.bmiHeader;int strDrawLineStep = strBaseW * 3 % 4 == 0 ? strBaseW * 3 : (strBaseW * 3 + 4 - ((strBaseW * 3) % 4));bih.biSize = sizeof(BITMAPINFOHEADER);bih.biWidth = strBaseW;bih.biHeight = strBaseH;bih.biPlanes = 1;bih.biBitCount = 24;bih.biCompression = BI_RGB;bih.biSizeImage = strBaseH * strDrawLineStep;bih.biClrUsed = 0;bih.biClrImportant = 0;void* pDibData = 0;HBITMAP hBmp = CreateDIBSection(hDC, &bmp, DIB_RGB_COLORS, &pDibData, 0, 0);CV_Assert(pDibData != 0);HBITMAP hOldBmp = (HBITMAP)SelectObject(hDC, hBmp);//color.val[2], color.val[1], color.val[0]SetTextColor(hDC, RGB(255, 255, 255));SetBkColor(hDC, 0);//SetStretchBltMode(hDC, COLORONCOLOR);strcpy_s(buf, str);const char* ln = strtok_s(buf, "\n", bufT);int outTextY = 0;while (ln != 0){TextOutA(hDC, 0, outTextY, ln, strlen(ln));outTextY += singleRow;ln = strtok_s(0, "\n", bufT);}uchar* dstData = (uchar*)dst.data;int dstStep = dst.step / sizeof(dstData[0]);unsigned char* pImg = (unsigned char*)dst.data + org.x * dst.channels() + org.y * dstStep;unsigned char* pStr = (unsigned char*)pDibData + x * 3;for (int tty = y; tty <= b; ++tty){unsigned char* subImg = pImg + (tty - y) * dstStep;unsigned char* subStr = pStr + (strBaseH - tty - 1) * strDrawLineStep;for (int ttx = x; ttx <= r; ++ttx){for (int n = 0; n < dst.channels(); ++n) {double vtxt = subStr[n] / 255.0;int cvv = vtxt * color.val[n] + (1 - vtxt) * subImg[n];subImg[n] = cvv > 255 ? 255 : (cvv < 0 ? 0 : cvv);}subStr += 3;subImg += dst.channels();}}SelectObject(hDC, hOldBmp);SelectObject(hDC, hOldFont);DeleteObject(hf);DeleteObject(hBmp);DeleteDC(hDC);}3.字符转换
识别的字符属于UTF8,在windows下,要转成ASCII才能正常显示不乱码,在C++中,可以使用标准库中的一些函数来处理字符编码的转换,但需要注意UTF-8和ASCII字符编码之间的差异。因为UTF-8是一种更广泛支持字符的编码方式,所以在进行转换时,需要确保要转换的文本仅包含ASCII字符。
#include "EncodeConversion.h"#include <Windows.h>//utf8 转 Unicodeextern std::wstring Utf8ToUnicode(const std::string& utf8string){int widesize = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//unicode 转为 asciiextern std::string WideByteToAcsi(std::wstring& wstrcode){int asciisize = ::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, NULL, 0, NULL, NULL);if (asciisize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (asciisize == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(asciisize);int convresult = ::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, &resultstring[0], asciisize, NULL, NULL);if (convresult != asciisize){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//utf-8 转 asciiextern std::string UTF8ToASCII(std::string& strUtf8Code){std::string strRet("");//先把 utf8 转为 unicodestd::wstring wstr = Utf8ToUnicode(strUtf8Code);//最后把 unicode 转为 asciistrRet = WideByteToAcsi(wstr);return strRet;}//ascii 转 Unicodeextern std::wstring AcsiToWideByte(std::string& strascii){int widesize = MultiByteToWideChar(CP_ACP, 0, (char*)strascii.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = MultiByteToWideChar(CP_ACP, 0, (char*)strascii.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//Unicode 转 Utf8extern std::string UnicodeToUtf8(const std::wstring& widestring){int utf8size = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, NULL, 0, NULL, NULL);if (utf8size == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(utf8size);int convresult = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, &resultstring[0], utf8size, NULL, NULL);if (convresult != utf8size){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//ascii 转 Utf8extern std::string ASCIIToUTF8(std::string& strAsciiCode){std::string strRet("");//先把 ascii 转为 unicodestd::wstring wstr = AcsiToWideByte(strAsciiCode);//最后把 unicode 转为 utf8strRet = UnicodeToUtf8(wstr);return strRet;}三、整体测试
#include <iostream>#include "crnn_net.h"#include "db_net.h"#include "tools.h"#include "put_text.h"#include "EncodeConversion.h"int main() { NCNNOCR::DbNet det_net; NCNNOCR::CrnnNet rec_net; rec_net.read_model(); det_net.read_model(); cv::Mat img = cv::imread("235.jpg"); if (img.empty()) { std::cout << "empty" << std::endl; return 0; } cv::Mat drawImg = img.clone(); std::vector< NCNNOCR::TextBox> boxResult; std::vector< NCNNOCR::TextLine> recResult; det_net.detect(img, boxResult,2560); recResult.resize(boxResult.size()); for (size_t i = 0; i < boxResult.size(); i++) { cv::Mat partImg = NCNNOCR::getRotateCropImage(img, boxResult[i].boxPoint); rec_net.detect(partImg, recResult[i]); cv::polylines(drawImg, boxResult[i].boxPoint, true, cv::Scalar(0,0,255),4); std::string text = UTF8ToASCII(recResult.at(i).text); std::cout << text << std::endl; if (text.empty()) { continue; } put_text_ch(drawImg, text.c_str(), boxResult[i].boxPoint[0], cv::Scalar(0, 0, 255), 80); } cv::namedWindow("result", 0); cv::imshow("result", drawImg); cv::waitKey(); return 0;}
源码地址:https://download.csdn.net/download/matt45m/89070576