概述
字符编码转换是指将文本数据从一种字符集编码格式转换为另一种字符集编码格式的过程。由于计算机系统和网络通信中存在多种字符编码标准,比如:ASCII、Unicode(包括UTF-8、UTF-16等变体)、GBK、ISO-8859-1等,当数据在不同的环境或系统间传输、存储时,可能需要进行编码转换以确保正确显示和处理。
ASCII编码:主要用于英语字符的表示,占用一个字节,能表示128个字符。
Unicode编码:为了统一全球所有语言和符号而设计的一种字符集,包含所有已知书写系统的字符,并且有多种实现方式。其中UTF-8是最常用的,它是可变长度编码。对于英文字符,与ASCII兼容;而对于非英文字符,使用多字节表示。
GBK编码:中国国家标准字符集,包含了简体中文字符和其他一些汉字,每个字符通常使用2个字节表示。
ISO-8859系列编码:一组8位字符集编码,每种编码对应于不同的欧洲语言。
CHP_CharConvertor类
字符编码的转换过程通过编程语言提供的API函数或者专门的工具完成,但一般需要在目标操作系统上预先安装对应的字符集。对于嵌入式系统而言,Flash空间和内存空间有限,有时候无法预先安装对应的字符集。基于这个原因,我们封装了CHP_CharConvertor类,用于进行常用字符编码的转换。CHP_CharConvertor类的头文件,可参考下面的示例代码。
#pragma onceclass CHP_CharConvertor{public: static int GbkToUnicode(const unsigned char *pGbk, unsigned short *pusUnicode, int nMaxUnicodeBufLen); static int UnicodeToGbk(const unsigned short *pusUnicode, unsigned char *pGbk, int nMaxGbkBufLen); static int GbkToUtf8(unsigned char *pGbk, unsigned char *pUtf8, int nMaxUtf8BufLen); static int Utf8ToGbk(unsigned char *pUtf8, unsigned char *pGbk, int nMaxGbkBufLen);private: CHP_CharConvertor(); ~CHP_CharConvertor(); static int Ucs2ToUtf8(const unsigned short *pusUcs, unsigned char *pUtf8, int nUtf8BufLen); static int Utf8ToUcs2(const unsigned char *pUtf8, unsigned short *pusUcs, int nUcsBufLen); static short BinarySearch(const unsigned short *pusTable, unsigned short usTabLen, unsigned short usCode); static int GetUniLenOfGbStr(const unsigned char *pBuf); static int GetGbLenOfUniStr(const unsigned short *pusBuf); static unsigned short GbcToUc(unsigned short usGbc); static unsigned short UcToGbc(unsigned short usUc); static unsigned short CutWord(unsigned short usWord, unsigned char ucStart, unsigned char ucEnd);};CHP_CharConvertor类的公共接口有4个,主要用于在GBK编码和Unicode编码、GBK编码和UTF-8编码间进行转换。
GbkToUnicode:Gbk编码数据转换为Unicode编码数据。参数pGbk为Gbk编码数据字符串,参数pusUnicode为Unicode编码数据buffer,参数nMaxUnicodeBufLen为Unicode编码数据buffer的最大长度,返回值为Unicode编码数据的实际长度。
UnicodeToGbk:Unicode编码数据转换为Gbk编码数据。参数pusUnicode为Unicode编码数据字符串,参数pGbk为Gbk编码数据buffer,参数nMaxGbkBufLen为Gbk编码数据buffer的最大长度,返回值为Gbk编码数据的实际长度。
GbkToUtf8:Gbk编码数据转换为Utf8编码数据。参数pGbk为Gbk编码数据字符串,参数pUtf8为Utf8编码数据buffer,参数nMaxUtf8BufLen为Utf8编码数据buffer的最大长度,返回值为Utf8编码数据的实际长度。
Utf8ToGbk:Utf8编码数据转换为Gbk编码数据。参数pUtf8为Utf8编码数据字符串,参数pGbk为Gbk编码数据buffer,参数nMaxGbkBufLen为Gbk编码数据buffer的最大长度,返回值为Gbk编码数据的实际长度。
总结
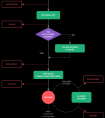
字符编码转换在多语言环境中尤其重要,因为不同的语言和字符集可能需要不同的编码方式来正确表示。字符编码转换的步骤通常包括以下四步。
识别原始编码:确定文本当前使用的字符编码。这可以通过查看文件的元数据、使用特定的库或工具来检测,或者由用户提供。
解码:将原始编码的文本转换成一种中间表示形式,通常是Unicode。解码是将字节序列转换成字符的过程,需要使用与原始编码相匹配的解码器。
编码:将中间表示形式的文本(比如:Unicode)转换成目标编码。编码是将字符转换成字节序列的过程,需要使用与目标编码相匹配的编码器。
输出或保存:将转换后的文本以新编码保存,或输出到另一个系统或应用程序中。