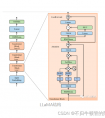
本篇文章讲讲LLaMA的结构,已经有很多文章已经对LLaMA在一些结构上任务表现上做了一些解析,本文主要从优化的角度、实现kernel的角度解析一下LLaMA,读者事先对transformer的结构有基本认识最好。本文首发于我的公众号“AI不止算法”,文章链接在此
LLaMA简单介绍
几个月前,FB开源了LLAMA,LLAMA1包括三个参数量的模型7B、13B、65B, 证明了完全可以通过公开数据集来训练最先进的模型,而无需使用专有和不可获取的数据集,同时LLaMA-13B 在大多数benchmark优于 GPT-3,尽管大小只有后者的1/10。在更大规模上,LLaMA-65B 参数模型也与可以与Chinchilla或PaLM-540B相竞争,这是之前bloom、OPT等没有做到的。本文不谈LLaMA的预训练数据多么多么怎么样,也不谈LLaMA在各个任务上的表现如何,重点从性能优化的角度谈谈LLaMA的模型结构。
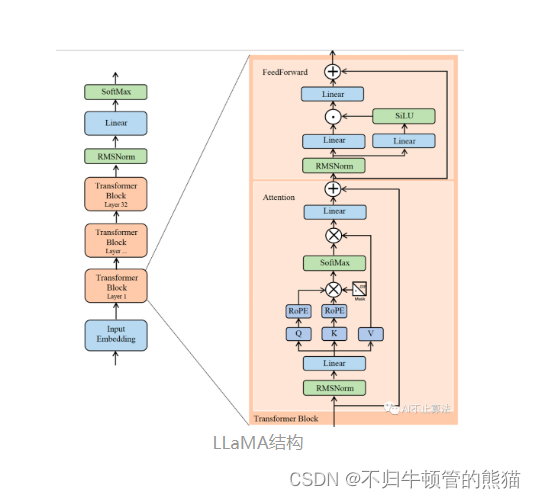
模型结构
LLaMA主体结构依然是transformer组成,和其它LLM不同的是:
使用RMSNorm(即Root Mean square Layer Normalization)对每个Transformer子层的input进行Pre Norm使用激活函数SwiGLU使用RoPE进行相对位置编码使用了AdamW优化器,并使用cosine learning rate schedule (AdamW和Adam的区别我不是特别清楚,先放着不讲)RMSNorm为layerNorm的变体,在分子分母都省去了Mean,同时少了beta参数,虽然不用再计算variance了,但我觉得Welford依然是Normlization类算子性能的最优解

# RMSNormclass RMSNorm(torch.nn.Module): def __init__(self, dim: int, eps: float = 1e-6): super().__init__() self.eps = eps # ε self.weight = nn.Parameter(torch.ones(dim)) def _norm(self, x): # RMSNorm return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) def forward(self, x): output = self._norm(x.float()).type_as(x) return output * self.weight激活函数SwiGLU整合了Swish和GLU这两个函数,网上的文章对这一块讲的似懂非懂,不如直接看CUDA源码,我去翻了一下SwiGLU的实现,得出SwiGLU可以理解为SiLU和mul的fused kernel,前者为x * sigmoid(x),本质上来看依然是一个element wise kernel
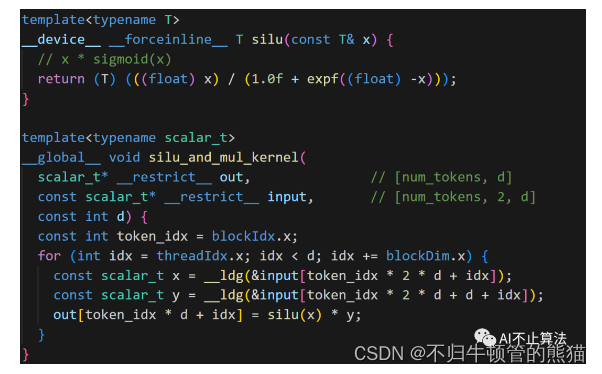
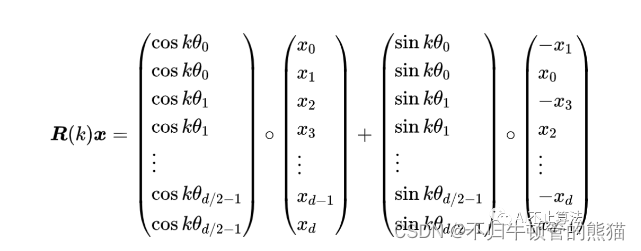
对于RoPE,这是一个新鲜的玩意,我们要做的就是实现这样一个rotary_embedding kernel , 它作用与QK矩阵上,在QK的batch GEMM之前,采用绝对位置编码来达到相对位置编码的效果,绝对位置编码的优点是计算简单高效,缺点是一般效果不如相对位置编码。相对位置编码的优点是效果较好,缺点是计算效率不如绝对位置编码。在相对位置编码中,注意力权重的结果仅仅和参与注意力计算的token向量的相对位置有关,不和绝对位置直接关联。这符合NLP领域在序列长度方向上具有平移不变性的特点,所以相对位置编码一般效果会优于绝对位置编码。
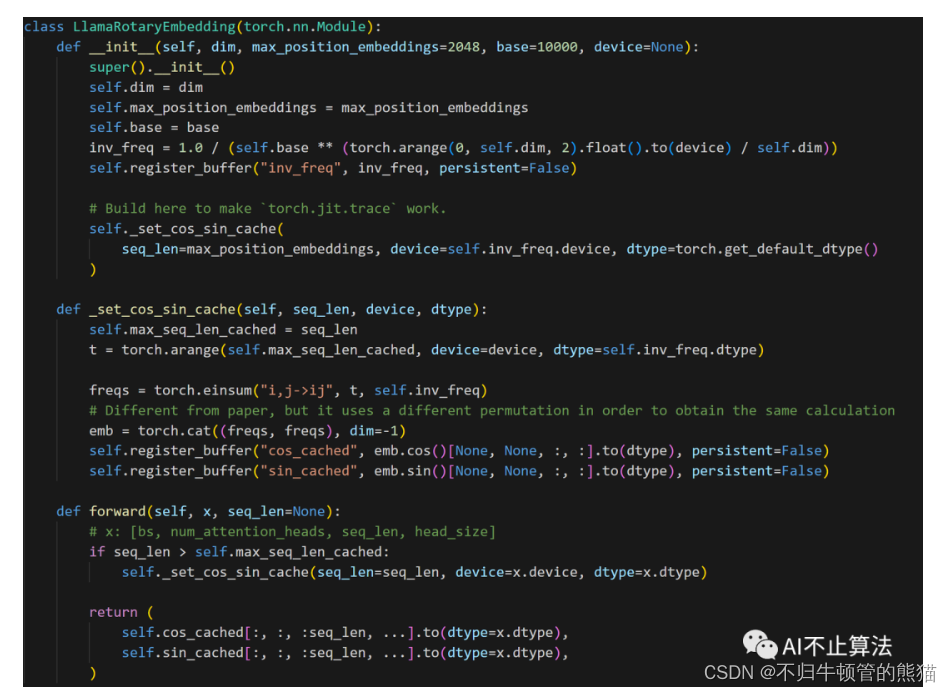
RoPE公式推导我个人有点看不下去,直接看公式吧,将旋转位置编码过程由GEMM简化成两次向量的哈达玛积求和,这也是一个element wise kernel,要把x给索引好,送给cos和sin相乘
python源代码,还是比较straightforward
LLaMA Attention
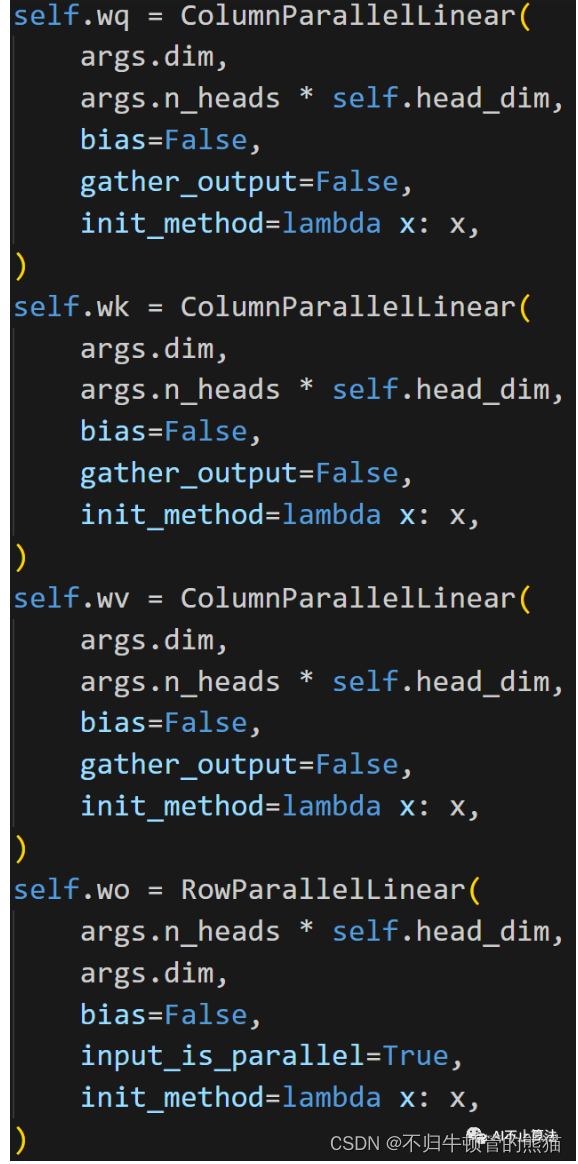
和普遍的attention结构没有太大区别,除了把上面的那些新增结构RMS norm,RoPE给添加到各个transformer layer开头和QK之后。想谈论的是Tensor Parallel 版本的attention,这里对qkv的weight采用了列切分,output linear采用了行切分,这循序了NV megatron的张量并行切分思想,有助于最小化多卡通讯开销。
LLaMA MLP
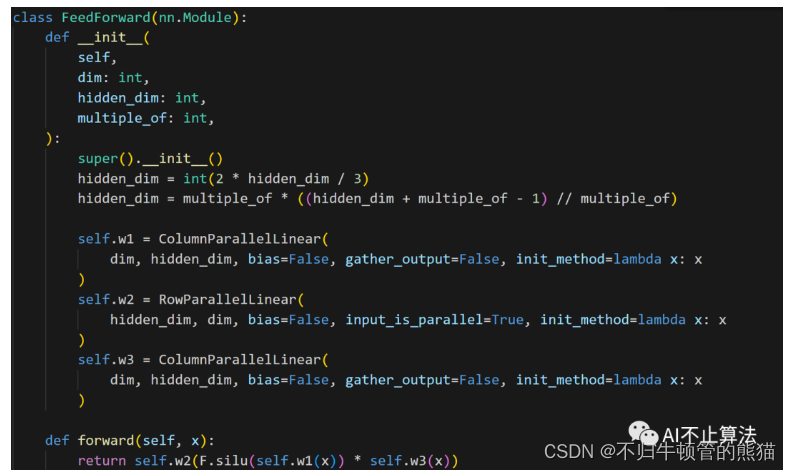
同理对于MLP,也采用了linear的列切分行切分版本,同时把SwiGLU给加了进去
LLaMA TransformerLayer
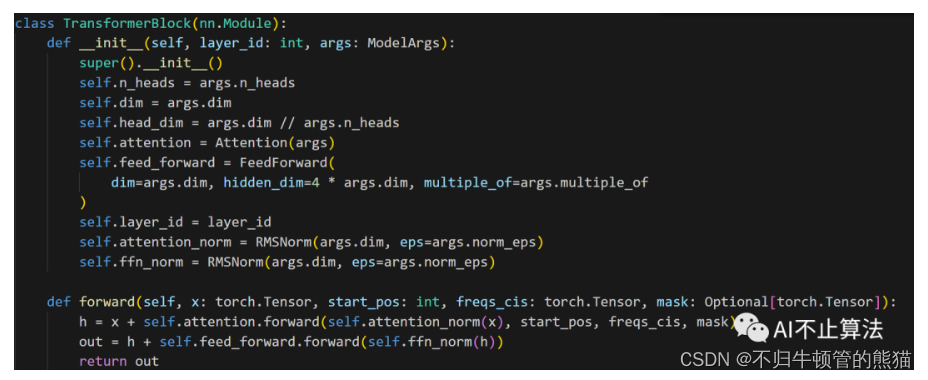
对于每个layer,把attention和MLP叠起来就完事
Llama generate
transformerlayer出来后的经过LMhead(其实就是个linear)+ softmax得到probs,然后就开始sample,可以topP,可以贪心,可以beam search,主要就看怎么设计了,在这份代码里,采用了topP或贪心,最后再detokenize,吐出token到构造的buffer tokens = torch.full((bsz,total_len), self.tokenizer.pad_id).cuda().long()
class LLaMA: def __init__(self, model: Transformer, tokenizer: Tokenizer): self.model = model self.tokenizer = tokenizer def generate( self, prompts: List[str], max_gen_len: int, temperature: float = 0.8, top_p: float = 0.95, ) -> List[str]: bsz = len(prompts) params = self.model.params assert bsz <= params.max_batch_size, (bsz, params.max_batch_size) prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts] min_prompt_size = min([len(t) for t in prompt_tokens]) max_prompt_size = max([len(t) for t in prompt_tokens]) total_len = min(params.max_seq_len, max_gen_len + max_prompt_size) tokens = torch.full((bsz, total_len), self.tokenizer.pad_id).cuda().long() for k, t in enumerate(prompt_tokens): tokens[k, : len(t)] = torch.tensor(t).long() input_text_mask = tokens != self.tokenizer.pad_id start_pos = min_prompt_size prev_pos = 0 # start generate for cur_pos in range(start_pos, total_len): logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos) if temperature > 0: probs = torch.softmax(logits / temperature, dim=-1) # sample by top P next_token = sample_top_p(probs, top_p) else: # greedy search next_token = torch.argmax(logits, dim=-1) next_token = next_token.reshape(-1) # only replace token if prompt has already been generated next_token = torch.where( input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token ) tokens[:, cur_pos] = next_token prev_pos = cur_pos # detokenize decoded = [] for i, t in enumerate(tokens.tolist()): # cut to max gen len t = t[: len(prompt_tokens[i]) + max_gen_len] # cut to eos tok if any try: t = t[: t.index(self.tokenizer.eos_id)] except ValueError: pass decoded.append(self.tokenizer.decode(t)) return decoded# sample the one which is the cum prob < pdef sample_top_p(probs, p): probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True) probs_sum = torch.cumsum(probs_sort, dim=-1) mask = probs_sum - probs_sort > p probs_sort[mask] = 0.0 probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True)) # extract a sample next_token = torch.multinomial(probs_sort, num_samples=1) # find next_token's id next_token = torch.gather(probs_idx, -1, next_token) return next_tokenLLaMA 2
LLaMA2在1的基础上又做了一些改进,在模型结构上引入了GQA来降低KV cache的显存占用,以此来增大batch size,获得更高的吞吐量,后面单独开篇文章讲讲MQA和GQA
另外
1、attention mask的构造上面也有一些要点:
_make_causal_mask用于构造下三角这种mask结构以实现语言模型的单向注意力。
_expand_mask用于将mask信息展开成和attention矩阵相同的张量结构。
2、对优化器AdamW的具体实现不是很了解,后续补补课再来聊聊
3、LLM的inference本身并不像general的inference engine或者framework那么有太大的复杂度,主要还是实现那几个kernel,整体我个人感觉在性能优化的角度,还是不会带来太大的额外工作量,多数kernel都可以reuse已有实现
最后,欢迎关注我的公众号“AI不止算法”