在Web开发中,我们经常遇到前后端数据类型不匹配的问题,特别是当后端使用大数据类型如Long时,前端由于JavaScript的数字精度限制,可能导致精度丢失。本文将深入探讨这个问题,并提供两种有效的解决方法。
一、问题背景
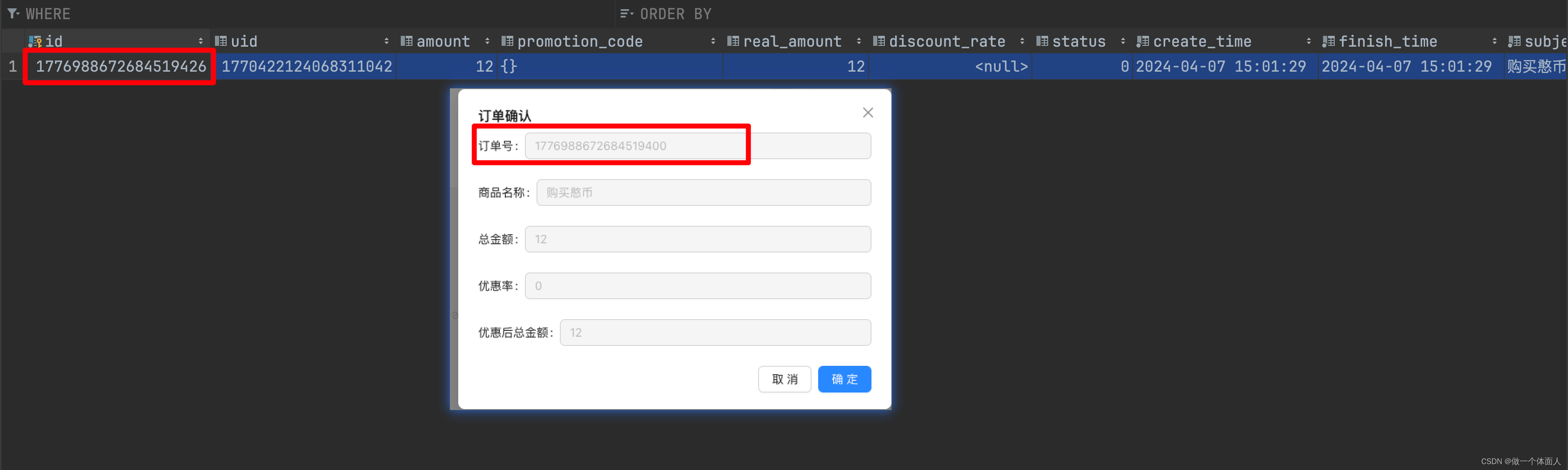
在后端开发中,为了确保数据的完整性和精度,我们可能会选择使用Long类型来存储某些数据,如订单ID、用户ID等。然而,当这些数据通过API传输到前端时,由于JavaScript中Number类型的精度限制(最大安全整数为2^53-1),如果Long类型的值超过了这个范围,就可能导致精度丢失。
二、解决方法
针对这个问题,我们可以采取以下几种解决方法:
方法一:使用@JsonSerialize注解将Long类型转换为String类型
在Java后端中,我们可以使用Jackson库的注解功能,将Long类型的字段在序列化为JSON时转换为String类型。这样,前端接收到的数据就是字符串形式,避免了精度丢失的问题。
示例代码如下:
import com.fasterxml.jackson.databind.annotation.JsonSerialize; import com.fasterxml.jackson.databind.ser.std.ToStringSerializer; import lombok.Data; @Data public class PayOrderVo { // 使用ToStringSerializer将Long类型的id字段转换为String类型 @JsonSerialize(using = ToStringSerializer.class) private Long id; // 其他字段... }通过这种方式,我们可以确保后端返回的JSON中,Long类型的字段都以字符串的形式存在,前端可以直接将其作为字符串处理,无需担心精度问题。
方法二:使用@JsonFormat注解将Long类型格式化为String
除了使用ToStringSerializer,Jackson还提供了@JsonFormat注解,它允许我们指定字段的序列化格式。当我们将shape属性设置为JsonFormat.Shape.STRING时,Long类型的字段也会被格式化为字符串。
示例代码如下:
import com.fasterxml.jackson.annotation.JsonFormat; import lombok.Data; @Data public class PayOrderVo { // 使用@JsonFormat注解将Long类型的id字段格式化为String @JsonFormat(shape = JsonFormat.Shape.STRING) private Long id; // 其他字段... }这种方法同样可以确保Long类型的字段在序列化为JSON时以字符串形式出现,避免前端精度丢失的问题。
前两种通过注解的方式确实可以有效地解决Long类型数据在前后端传输中的精度丢失问题。然而,当项目中存在多个类,且这些类中的多个字段都需要将Long类型转换为String类型返回给前端时,逐一为每个字段添加注解不仅繁琐,还可能导致代码冗余和难以维护。为了更优雅、高效地解决这一问题,我们可以考虑使用全局配置的方式,一次性解决所有Long类型字段的序列化问题。这样,我们不仅能提高开发效率,还能确保代码的一致性和可维护性。接下来,我们将详细探讨如何通过全局配置来实现这一目标。
方法三:全局配置Jackson将Long类型序列化为String
除了对单个字段进行注解配置外,我们还可以进行全局配置,使得所有Long类型的字段在序列化时都自动转换为String类型。这样可以减少在每个字段上添加注解的重复工作。
示例代码如下:
import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.module.SimpleModule; import com.fasterxml.jackson.databind.ser.std.ToStringSerializer; import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder; @Configuration public class JacksonConfig { @Bean @Primary @ConditionalOnMissingBean(ObjectMapper.class) public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) { ObjectMapper objectMapper = builder.createXmlMapper(false).build(); SimpleModule simpleModule = new SimpleModule(); // 将Long类型序列化为String类型 simpleModule.addSerializer(Long.class, ToStringSerializer.instance); objectMapper.registerModule(simpleModule); return objectMapper; } }在这个配置中,我们创建了一个自定义的ObjectMapper Bean,并注册了一个SimpleModule,该模块使用ToStringSerializer将Long类型序列化为String类型。这样,整个应用中所有Long类型的字段在序列化时都会自动转换为String类型。
三、总结
前端精度丢失问题是一个常见的挑战,但通过上述三种方法,我们可以有效地解决这个问题。在实际开发中,我们可以根据项目的具体情况和需求选择合适的方法。对于需要精确表示大数字的场景,将Long类型转换为String类型是一个简单而有效的解决方案。