SODA:LLM&RAG突破搜索界限,打造全新一代信息处理AI Tool
背景介绍
随着大型语言模型(LLM)的出现和广泛部署,这些高级系统在多种应用领域展现了巨大的潜力。然而,即使是像GPT-4这样的先进模型也不是没有局限性;它们并非全知全能,且容易出现所谓的“幻觉问题”。面对大语言模型的这些局限性,检索增强生成(Retrieve Argument Generation,RAG)技术为解决这些LLM的固有缺陷提供了一个有效的解决方案。
SODA简介

在此,介绍一款尖端的AI信息整合工具——SODA(Search, Organize, Discover Anything)。SODA 以大语言模型(LLM)为信息处理核心,灵活地从众多渠道获取数据以响应用户查询,从而提供精细和全面的答案。通过SODA,用户可以利用一个高级的网络搜索机制,从互联网上提取相关信息。这使得LLM的内在知识和外部资源无缝整合,确保提供的答案不仅准确而且可靠。此外,SODA还支持用户上传个人文件,便于创建一个私密、安全且强大的本地知识数据库。这一功能使得LLM能够轻松吸收新信息,无需预训练或微调,有效地利用这些知识来响应用户输入。SODA_Github
SODA架构
SODA的架构如下图所示:
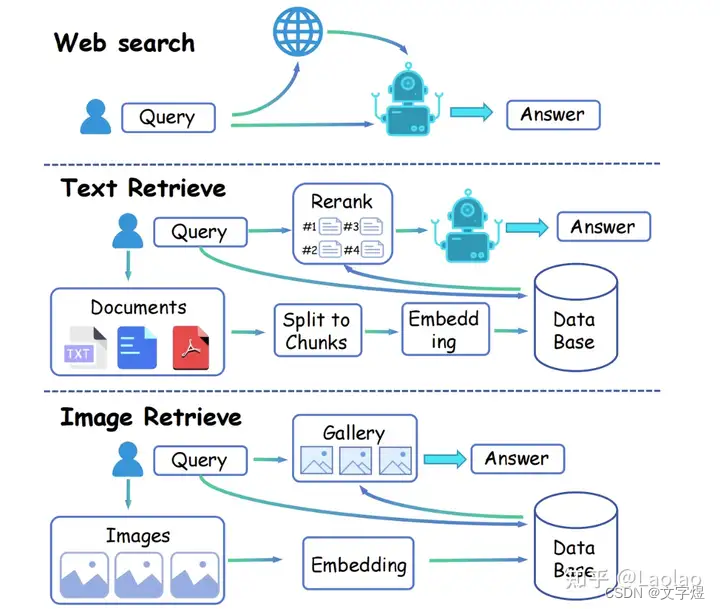
SODA现阶段支持网络检索, 文本检索(本地数据库)和图像检索(本地数据库)。 在文本检索阶段,SODA拥有**两阶段(two-stages)**检索过程,第一阶段从数据库中检索信息,第二阶段对检索到的文本进行重新排序。
SODA优点
全新的技术框架 我们开发了一款由LLM(大型语言模型)驱动的信息整合工具,同时兼容网络检索和本地数据库检索功能。它提供了一个用于检索增强生成(RAG)的技术框架,并为AI Agent提供了使用工具的指导。良好的兼容性 SODA能够轻松切换组件,使用不同的搜索引擎、向量数据库或LLM,并展现出良好的兼容性。可靠&信息来源可追溯 SODA有效地解决了LLM的部分幻觉问题,提供了可追溯信息源的可靠且准确的答案。数据隐私 SODA支持本地数据库,允许模型在不进行预训练或微调的情况下获取新知识,同时有效保护用户数据隐私。SODA的架构支持多种搜索引擎和大语言模型,用户可以根据自己的需要选择合适的组件进行信息检索和信息处理。目前,SODA已支持Google, Bing等搜索引擎。同时,对于SODA的信息处理核心,使用者可以在GPT4 API和本地运行的大语言模型(InternLM-Xcomposer2)之间切换。此外,SODA也支持开发者在此基础上添加和测试更多类型的搜索引擎和大语言模型。无论是联网问答、文本搜索还是图像检索,SODA都能提供高效且精确的解决方案。通过这种模块化的设计,SODA展现了极高的兼容性和灵活性,能够适应不同用户的需求和不断变化的技术环境。
此外,关于数据隐私和安全性,SODA提供了一系列解决方案。用户可以上传自己的文件,建立私人的本地数据库。这不仅保证了数据的安全性,还使得SODA能够在不需要进行预训练或微调的情况下,快速吸收并应用新知识。这种灵活的数据处理方式在提升响应速度的同时,也保证了信息的准确性和可追溯性。

总体而言,SODA被设计为一个安全、可靠、且智能信息采集和处理的工具。它的设计使用户能够处理和解释从大语言模型、网络和您自己的数据库中获得的信息。SODA不仅是一个搜索和组织信息的工具,它还是一个发现未知的平台。无论是学术研究、商业分析还是日常问题解决,SODA都能提供强有力的支持,帮助用户从海量信息中发现有价值的知识,实现数据的最大价值。
我们鼓励所有对大语言模型(LLM)和检索增强生成(RAG)感兴趣的开发者和研究人员访问SODA的GitHub页面,探索其丰富的功能和潜力。随着社区的参与和反馈,SODA将持续进化,带来更多创新的解决方案。
立即访问SODA的 SODA_Github ,开启你的智能搜索之旅,体验SODA带来的全新信息处理方式!