一、概念
1.1 主题模型
主题模型(Topic Model)是自然语言处理中的一种常用模型,是一种无监督学习方法,它用于从大量文档中自动提取主题信息。
主题模型的核心思想是,每篇文档都可以看作是多个主题的混合,而每个主题则由一组词构成。
主题模型能够帮助我们理解文档集中的主题结构,有助于文档分类、聚类和信息检索。主题模型能够将高维的文本数据降维到低维的主题空间,便于后续的分析和处理。1.2 BERTopic
BERTopic是基于BERT词向量进行主题建模技术,它利用 Transformer 和 c-TF-IDF 来创建密集的集群(分类),允许轻松解释主题,同时在主题描述中保留重要词。
从个人实践效果来看,要优于LDA、BTM等主题模型
BERTopic 可以看作是创建其主题表示的一系列步骤。此过程有五个步骤:
Embeddings:词嵌入,选择预训练模型Dimensionality Reduction:降维,默认选择UMAPClustering:聚类,默认选择HDBSCANVectorizers:将文本中的词语词频矩阵c-TF-IDF:获得主题的准确表示Fine-tune Topics:模型微调(可选)
里面涉及到的模型原理后续会分别整理
二、建模流程
使用BERTopic,有两种方式,一种是全部使用默认参数,直接调包运行;另外一种是自己根据实际数据集进行超参数进行调整
2.1 快速入门
直接使用默认的参数进行调用
2.1.1 安装包
pip install bertopic2.1.2 数据导入
df = pd.read_csv('news.csv')2.1.3 分词
分词可以实现处理好再进行建模,也可以定义好分词的方法在建模时传入,一般建议先分词在建模,这样可以打印中间分词结果进行检查

2.1.4 创建模型
from sentence_transformers import SentenceTransformerfrom sklearn.feature_extraction.text import CountVectorizerembedding_model = SentenceTransformer("distiluse-base-multilingual-cased-v1")vectorizer = CountVectorizer()from bertopic import BERTopictopic_model = BERTopic(embedding_model=embedding_model, vectorizer_model=vectorizer)topics, probs = topic_model.fit_transform(docs)训练时如果报错,可参照之前的一篇文章

2.1.5 查看结果
topic_model.get_topic_info 查看各主题信息

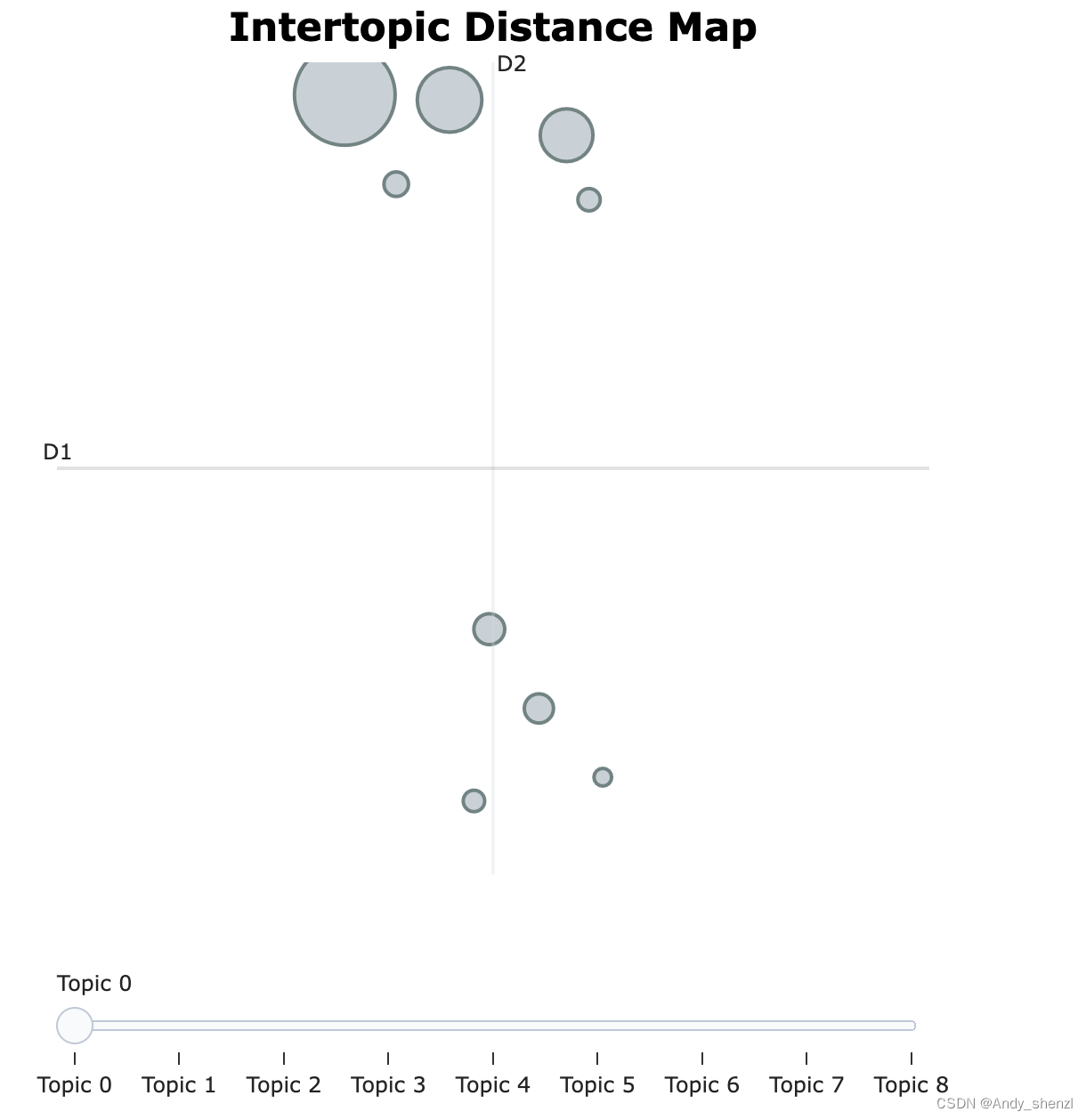
topic_model.visualize_topics() 话题间距离的可视化
topic_model.visualize_hierarchy(top_n_topics=20) 主题层次聚类可视化
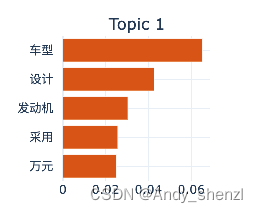
topic_model.visualize_barchart(topics=[1]) 显示主题1的词条形图
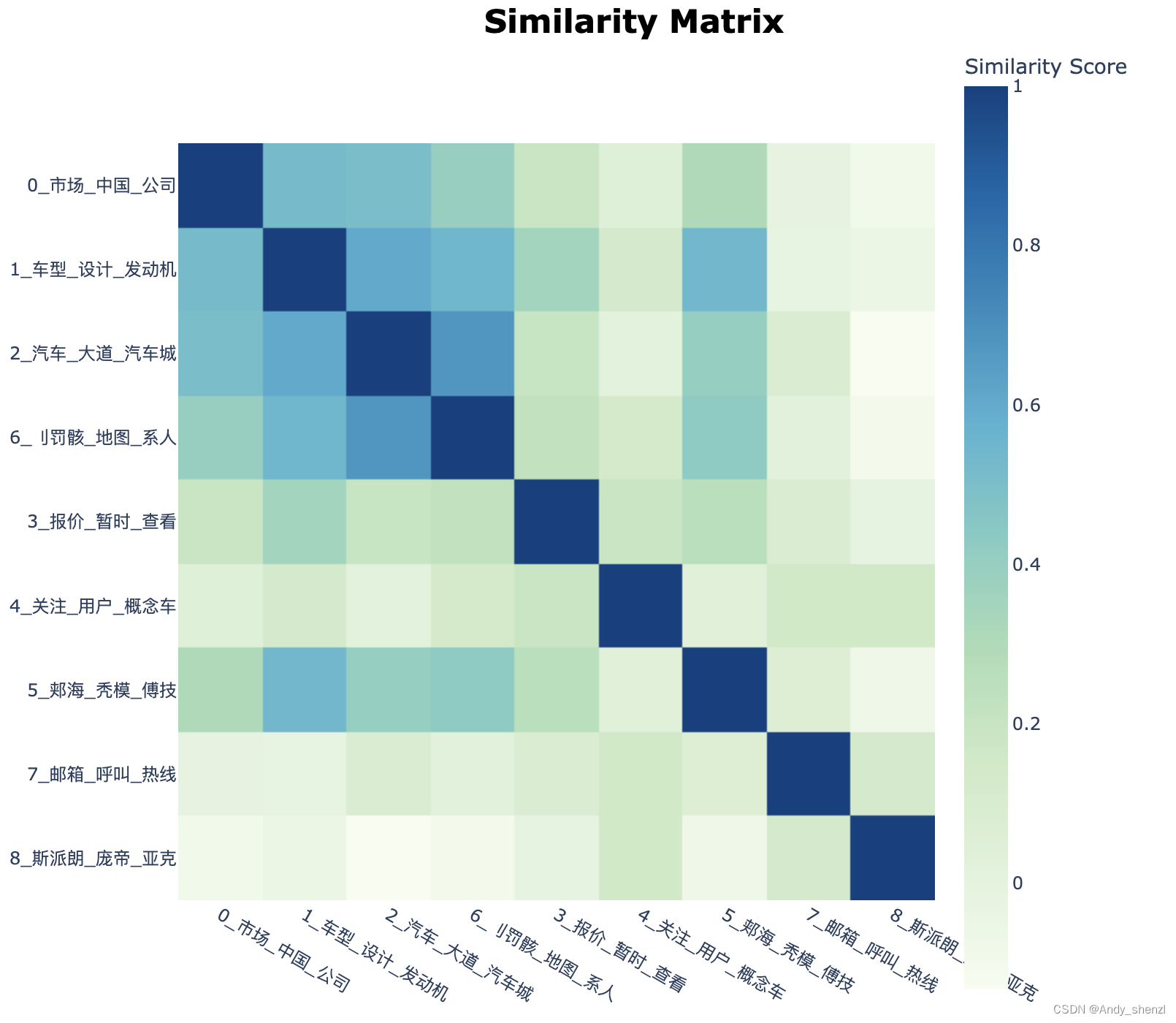
topic_model.visualize_heatmap() 主题相似度热力图