C++ 结合 TensorRT 部署深度学习模型有几个关键优势,这些优势在各种工业和商业应用中极其重要:
高效的性能:TensorRT 通过优化深度学习模型来提高推理速度,减少延迟。这对于实时处理应用(如视频分析、机器人导航等)至关重要。
降低资源消耗:TensorRT 优化了模型以在GPU上高效运行,这意味着更低的内存占用和更高的吞吐量。对于资源受限的环境或在多任务并行处理的情况下,这是一个显著优势。
跨平台和硬件兼容性:C++ 是一种跨平台语言,配合 TensorRT,可以在多种硬件和操作系统上部署深度学习模型,包括嵌入式设备和服务器。
准确性和稳定性:TensorRT 提供了精确的数学和统计方法来减少浮点运算误差,这对于确保深度学习应用的准确性和稳定性至关重要。
定制和灵活性:使用 C++ 和 TensorRT,开发者可以高度定制他们的深度学习应用。这包括调整模型结构、优化算法和调节性能参数以满足特定需求。
支持复杂网络和大规模部署:TensorRT 支持最新的深度学习网络结构,并能够处理复杂的计算任务。这对于需要部署大型、复杂网络的工业应用来说是必要的。
易于集成和扩展:C++ 提供了与其他系统和工具(如数据库、网络服务等)集成的灵活性。此外,TensorRT 也可以轻松与其他NVIDIA工具链(如CUDA、cuDNN等)集成。
一、准备
下载YOLOv8项目和Tensorrt部署项目,TensorRT C++代码选择:
https://github.com/xiaocao-tian/yolov8_tensorrt
yolov8参考前几天的ultralytics。
在ultralytics新建weights文件夹,放入yolov8s.pt.
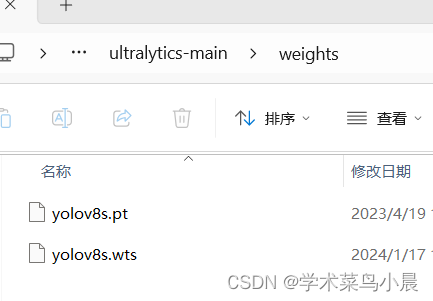
将src的gen_wts.py,复制到ultralytics。
运行gen_wts.py,生成 yolov8s.wts.
再将weights复制到 yolov8 TensorRT。
二、环境准备
1.vs配置
我下载的是vs2022,只安装c++的桌面开发。
踩坑1:特别注意,请先安装Visual Studio 2019,再安装CUDA。这样做的目的是避免在Visual Studio 2019中看不到CUDA runtime模板。CUDA安装过程中,会提供cuda模板插件,如果先下载好Visual Studio 2019的情况下,该插件会自动配置。
平坑1:安装好vs2022后,再重装cuda。
cuda和cudnn安装请看:yolov8实战第一天——yolov8部署并训练自己的数据集(保姆式教程)_yolov8训练自己的数据集-CSDN博客
2.cmake配置
Index of /files
下载:cmake-3.28.0-rc1-windows-x86_64.msi
安装版本,自己添加环境变量。
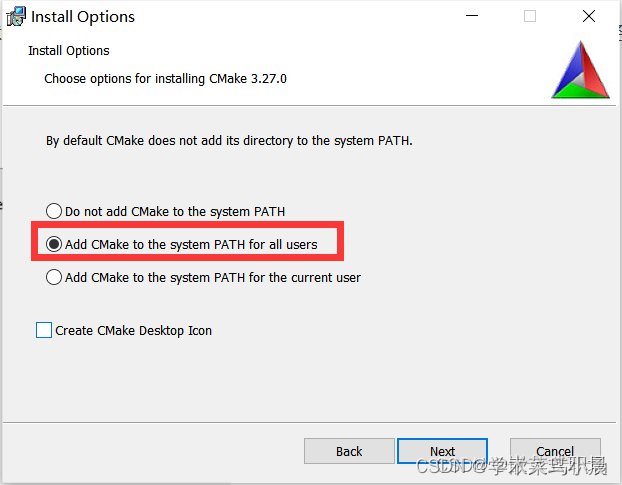
踩坑2:要验证cmake安装是否成功。

cmake成功安装。
3.opencv、tensorrt配置
opencv安装:C++实战Opencv第一天——win11下配置vs,opencv环境和运行第一个c++代码(从零开始,保姆教学)-CSDN博客
tensorrt安装:
yolov8实战第三天——yolov8TensorRT部署(python推理)(保姆教学)_yolov8 tensorrt python部署-CSDN博客
踩坑3:环境变量的配置
平坑3:opencv、tensorrt、cudnn环境变量配置
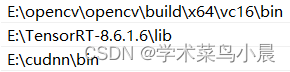
至此,vs,cmake,cuda,cudnn,opencv,tensorrt全部配置完成。
三、编译
在tensorrt项目中新建build文件夹,然后使用cmake编译,注意tensorrt项目中Cmakelist.txt
分别配置自己opencv和tensorrt的地址即可。
cmake_minimum_required(VERSION 3.10)project(yolov8)# Modify to your pathset(OpenCV_DIR "E:/opencv/opencv/build") set(TRT_DIR "E:/TensorRT-8.6.1.6") add_definitions(-std=c++11)add_definitions(-DAPI_EXPORTS)set(CMAKE_CXX_STANDARD 11)set(CMAKE_BUILD_TYPE Debug)# setup CUDAfind_package(CUDA REQUIRED)message(STATUS "libraries: ${CUDA_LIBRARIES}")message(STATUS "include path: ${CUDA_INCLUDE_DIRS}")include_directories(${CUDA_INCLUDE_DIRS})enable_language(CUDA)include_directories(${PROJECT_SOURCE_DIR}/include)include_directories(${PROJECT_SOURCE_DIR}/plugin)# TensorRTset(TENSORRT_ROOT "E:/TensorRT-8.6.1.6")include_directories("${TENSORRT_ROOT}/include")link_directories("${TENSORRT_ROOT}/lib")# OpenCVfind_package(OpenCV)include_directories(${OpenCV_INCLUDE_DIRS})add_library(myplugins SHARED ${PROJECT_SOURCE_DIR}/plugin/yololayer.cu)target_link_libraries(myplugins nvinfer cudart)file(GLOB_RECURSE SRCS ${PROJECT_SOURCE_DIR}/src/*.cpp ${PROJECT_SOURCE_DIR}/src/*.cu)add_executable(yolov8 ${PROJECT_SOURCE_DIR}/src/main.cpp ${SRCS})target_link_libraries(yolov8 nvinfer)target_link_libraries(yolov8 cudart)target_link_libraries(yolov8 myplugins)target_link_libraries(yolov8 ${OpenCV_LIBS})在tensorrt项目中新建build文件夹,然后使用cmake编译,填写如图。
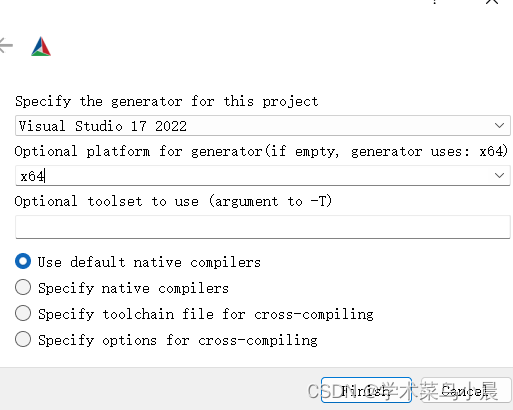
踩坑1:No CUDA toolset found.就是找不到cuda。
The C compiler identification is MSVC 19.38.33133.0The CXX compiler identification is MSVC 19.38.33133.0Detecting C compiler ABI infoDetecting C compiler ABI info - doneCheck for working C compiler: E:/vs2022/Community/VC/Tools/MSVC/14.38.33130/bin/Hostx64/x64/cl.exe - skippedDetecting C compile featuresDetecting C compile features - doneDetecting CXX compiler ABI infoDetecting CXX compiler ABI info - doneCheck for working CXX compiler: E:/vs2022/Community/VC/Tools/MSVC/14.38.33130/bin/Hostx64/x64/cl.exe - skippedDetecting CXX compile featuresDetecting CXX compile features - doneCMake Warning (dev) at CMakeLists.txt:15 (find_package): Policy CMP0146 is not set: The FindCUDA module is removed. Run "cmake --help-policy CMP0146" for policy details. Use the cmake_policy command to set the policy and suppress this warning.This warning is for project developers. Use -Wno-dev to suppress it.Found CUDA: D:/CUDA (found version "12.0") libraries: D:/CUDA/lib/x64/cudart_static.libinclude path: D:/CUDA/includeCMake Error at D:/cmake/share/cmake-3.28/Modules/CMakeDetermineCompilerId.cmake:529 (message): No CUDA toolset found.Call Stack (most recent call first): D:/cmake/share/cmake-3.28/Modules/CMakeDetermineCompilerId.cmake:8 (CMAKE_DETERMINE_COMPILER_ID_BUILD) D:/cmake/share/cmake-3.28/Modules/CMakeDetermineCompilerId.cmake:53 (__determine_compiler_id_test) D:/cmake/share/cmake-3.28/Modules/CMakeDetermineCUDACompiler.cmake:135 (CMAKE_DETERMINE_COMPILER_ID) CMakeLists.txt:20 (enable_language)Configuring incomplete, errors occurred!踩坑3:找不到cudnn。
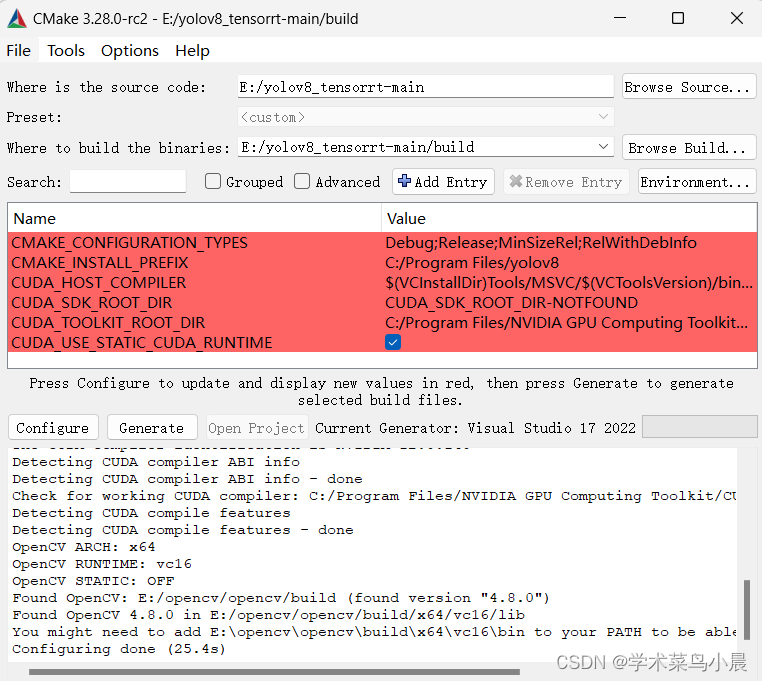
UserTraceback (most recent call last): File "<stdin>", line 1, in <module> File "E:\Anaconda3\Lib\site-packages\tensorrt\__init__.py", line 127, in <module> ctypes.CDLL(find_lib(lib)) ^^^^^^^^^^^^^ File "E:\Anaconda3\Lib\site-packages\tensorrt\__init__.py", line 81, in find_lib raise FileNotFoundError(FileNotFoundError: Could not find: cudnn64_8.dll. Is it on your PATH?Note: Paths searched were:平坑后:警告不用管。configure:
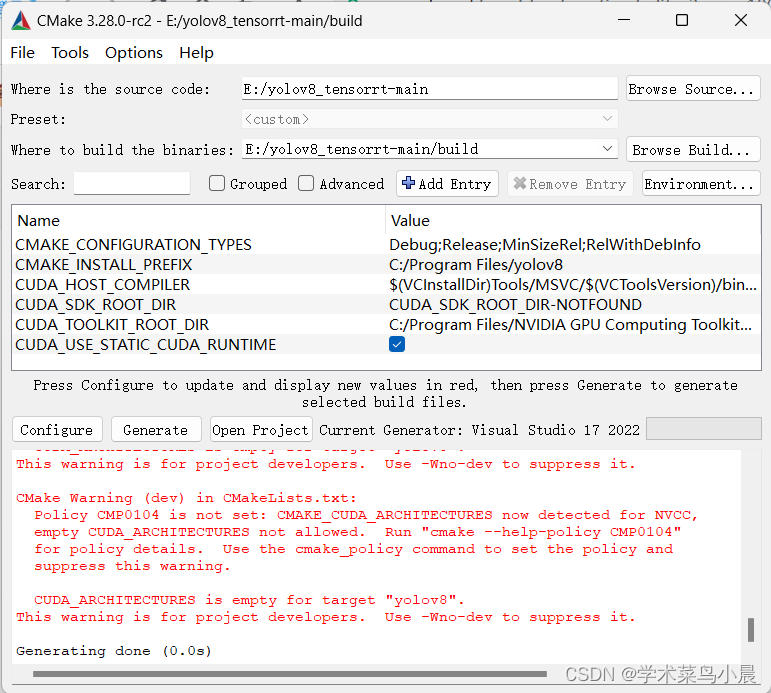
generate:
然后open Project。
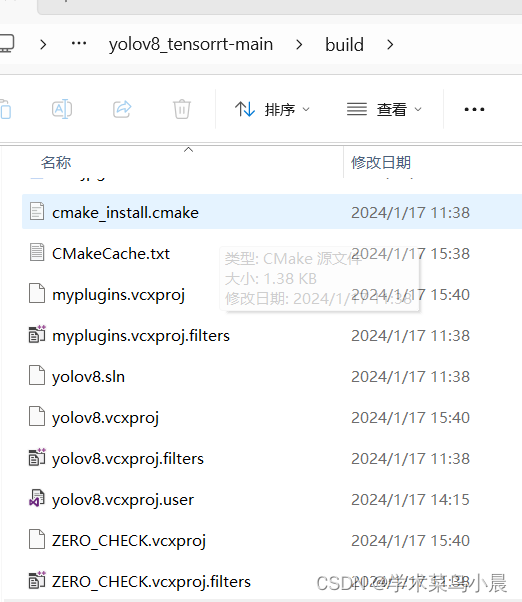
踩坑4:cmake 点 open Project 没反应 。
平坑4:在生成的build中找到yolov8.sln,右键打开方式选择vs2022.
解决方案右键属性->选择yolov8.
打开main.cpp
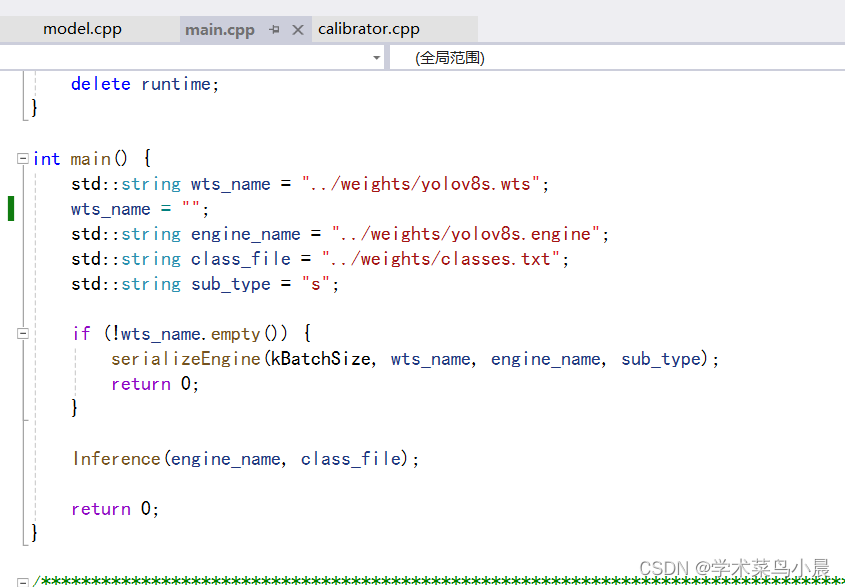
先注释 表示生成.engine文件。
//wts_name = "";注释后直接运行。

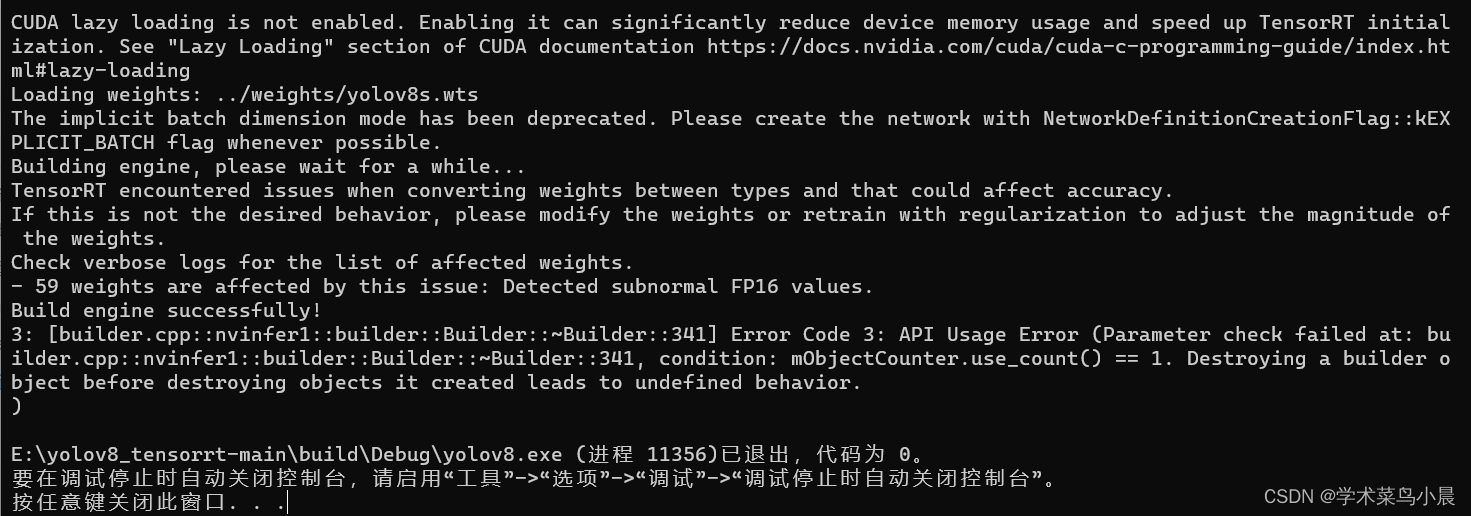
去掉注释,再次执行。
wts_name = "";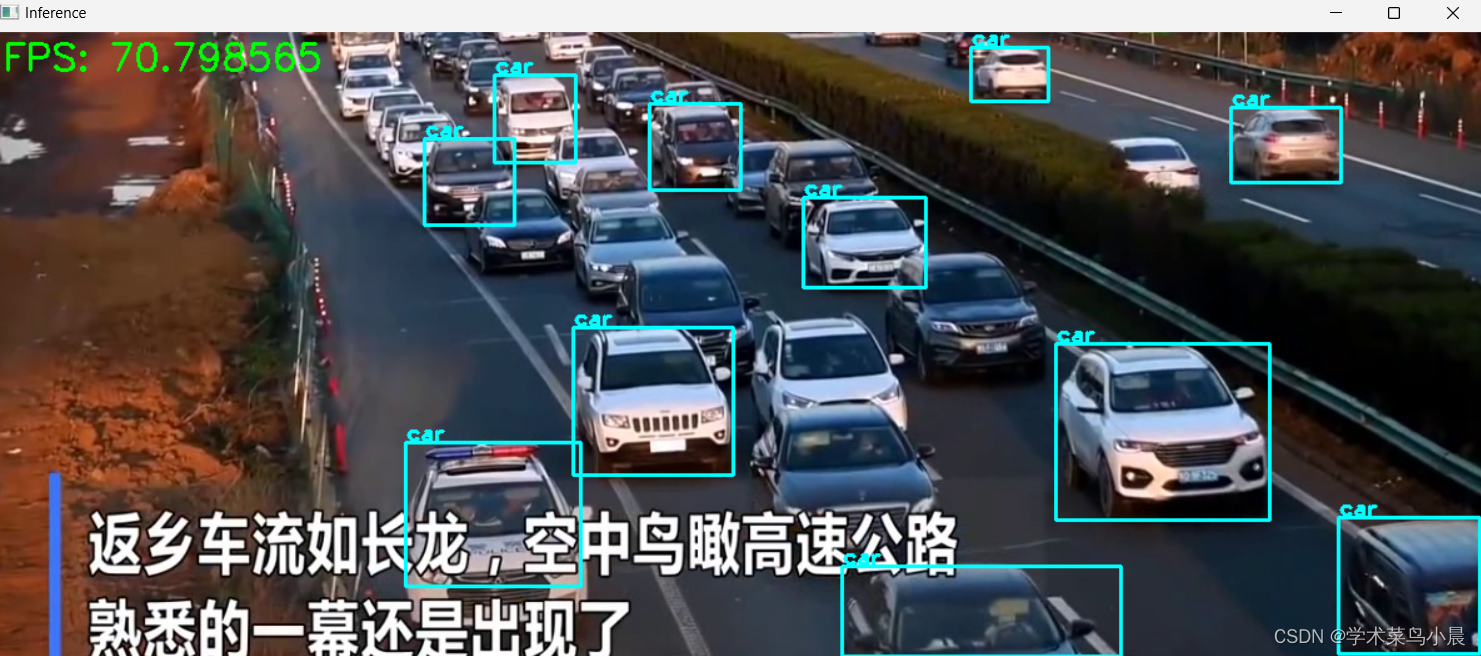
视频太短,长视频fps在100左右。
添加fps代码:
while (char(cv::waitKey(1) != 27)) { cap >> image; if (image.empty()) { std::cerr << "Error: Image not loaded or end of video." << std::endl; break; // or continue based on your logic } auto t_beg = std::chrono::high_resolution_clock::now(); float scale = 1.0; int img_size = image.cols * image.rows * 3; cudaMemcpyAsync(image_device, image.data, img_size, cudaMemcpyHostToDevice, stream); preprocess(image_device, image.cols, image.rows, device_buffers[0], kInputW, kInputH, stream, scale); context->enqueue(kBatchSize, (void**)device_buffers, stream, nullptr); cudaMemcpyAsync(output_buffer_host, device_buffers[1], kBatchSize * kOutputSize * sizeof(float), cudaMemcpyDeviceToHost, stream); cudaStreamSynchronize(stream); std::vector<Detection> res; NMS(res, output_buffer_host, kConfThresh, kNmsThresh); // 计算FPS frame_counter++; if (frame_counter % 10 == 0) { // 每10帧更新一次FPS auto t2 = std::chrono::high_resolution_clock::now(); auto time_span = std::chrono::duration_cast<std::chrono::duration<double>>(t2 - t1); fps = frame_counter / time_span.count(); t1 = t2; frame_counter = 0; } drawBbox(image, res, scale, labels); // 将FPS绘制到图像上 cv::putText(image, "FPS: " + std::to_string(fps), cv::Point(10, 30), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 255, 0), 2); auto t_end = std::chrono::high_resolution_clock::now(); cv::imshow("Inference", image); float total_inf = std::chrono::duration<float, std::milli>(t_end - t_beg).count(); std::cout << "Inference time: " << int(total_inf) << std::endl; } // cv::waitKey(); cv::destroyAllWindows();