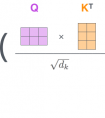今天给大家分享一篇关于深度学习模型Transformer的文章。我愿称之为讲解Transformer模型最好的文章。
文章内容主要介绍 Transformer 模型的具体实现:
Transformer整体架构
Transformer概览
引入张量
自注意力机制Self-Attention
多头注意力机制Mutil-Head Attention
位置反馈网络(Position-wise Feed-Forward Networks)
残差连接和层归一化(Add & Normalize)
位置编码(Positional Encoding)
解码器Decoder
掩码Mask:Padding Mask + Sequence Mask
最后的线性层和Softmax层
嵌入层和最终的线性层
正则化操作
文章有点长,建议收藏
1、Transformer模型架构
2017 年,Google 在论文 Attentions is All you need(论文地址:https://arxiv.org/abs/1706.03762) 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。
相比 RNN 网络结构,其最大的优点是可以并行计算。Transformer 的整体模型架构如图所示:
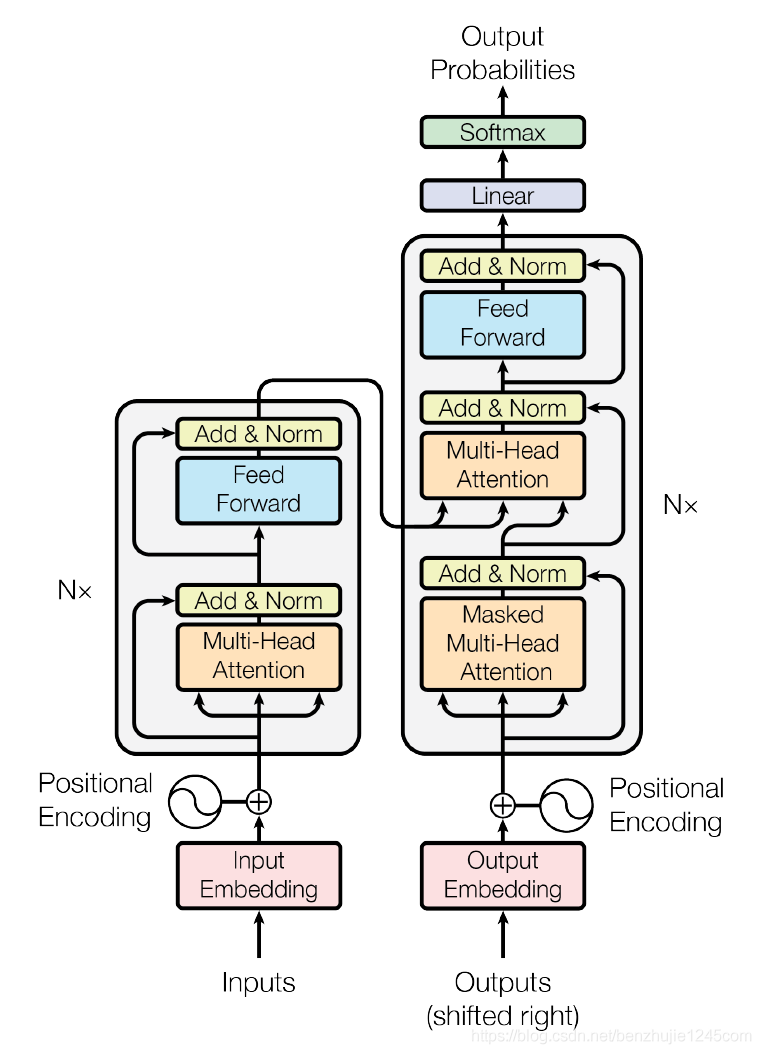
Transformer模型架构
2、Transformer 概览
首先,让我们先将 Transformer 模型视为一个黑盒,如图所示。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出:

Transformer 模型(黑盒模式)
2.1 Encoder-Decoder
Transformer 本质上是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码组件和解码组件
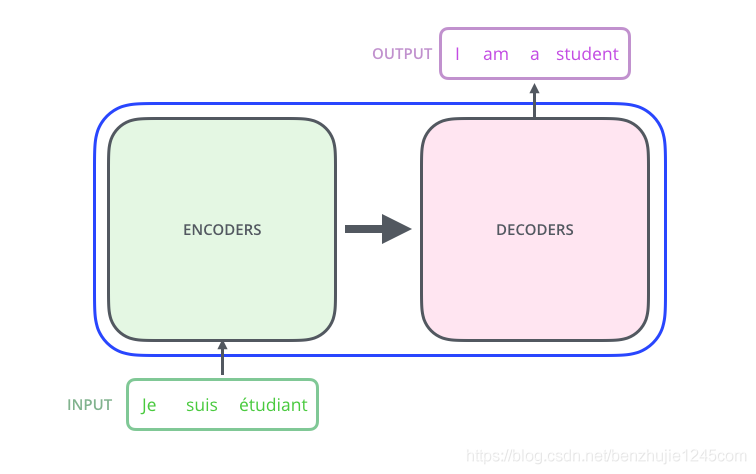
Transformer 模型(Encoder-Decoder 架构模式)
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。
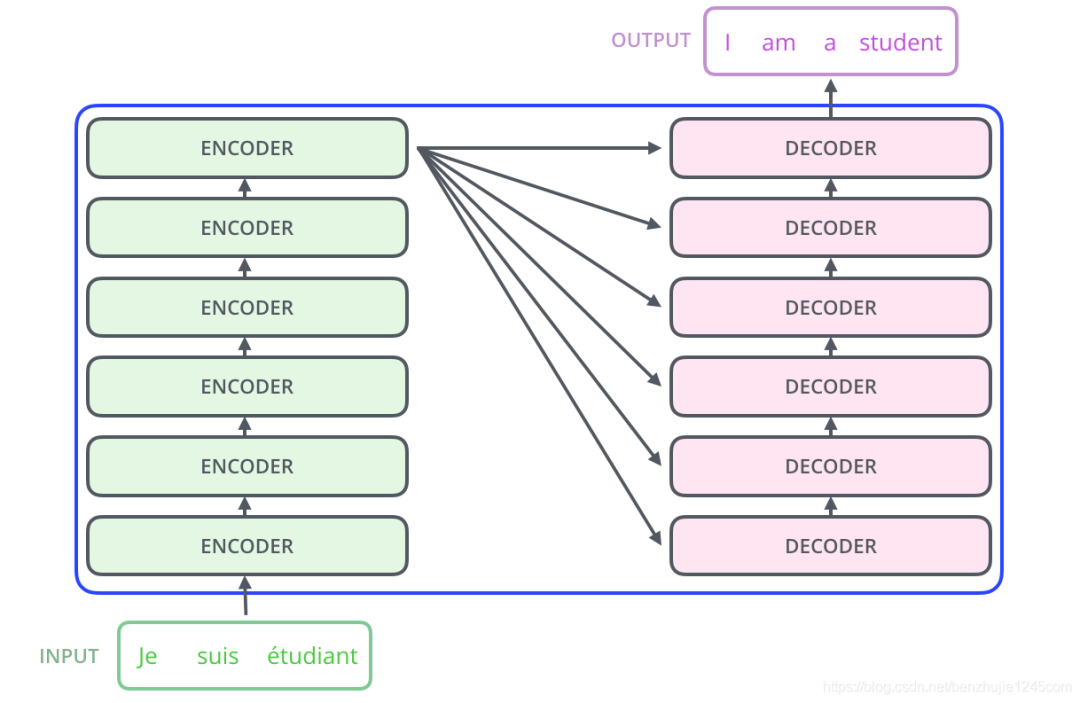
编码器/解码器组成
每个编码器由两个子层组成:
Self-Attention层(自注意力层)
Position-wise Feed Forward Network(前馈网络,缩写为 FFN)
如下图所示:每个编码器的结构都是相同的,但是它们使用不同的权重参数(6个编码器的架构相同,但是参数不同)
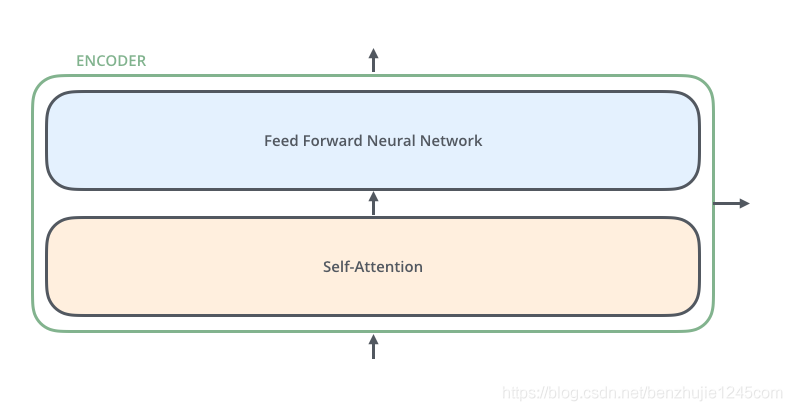
Encoder编码器组成
编码器的输入会先流入 Self-Attention 层。它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息)。
注:关注词语的上下文环境,不仅仅是词语本身
后面我们将会详细介绍 Self-Attention 的内部结构。然后,Self-Attention 层的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),其用来帮忙解码器关注输入句子的相关部分(类似于 seq2seq 模型中的注意力)
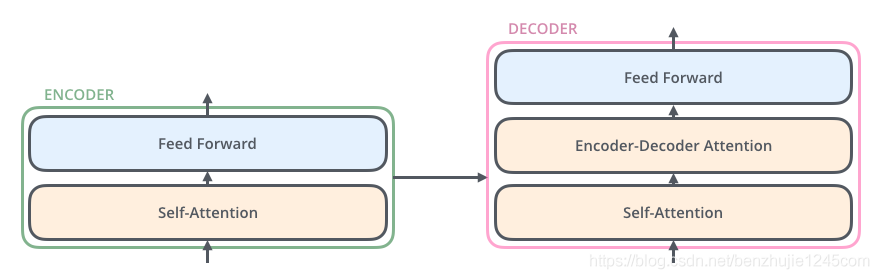
编码器:
self-attention层 + 前馈网络FFN(Position-wise Feed Forward Network)解码器:
self-attention层 +Encoder-Decoder Attention+ 前馈网络FFN(Position-wise Feed Forward Network)
3、引入张量
现在我们已经了解了模型的主要组成部分,让我们开始研究各种向量/张量,以及他们在这些组成部分之间是如何流动的,从而将输入经过已训练的模型转换为输出。
3.1 引入词嵌入Embedding
和通常的 NLP 任务一样,首先,我们使用词嵌入算法(Embedding) 将每个词转换为一个词向量。
在 Transformer 论文中,词嵌入向量的维度是 512。

每个词被嵌入到大小为
512的向量中。我们将用这些简单的框代表这些向量。
词嵌入仅发生在最底层的编码器中。所有编码器都会接收到一个大小为 512 的向量列表:
底部编码器接收的是词嵌入向量
其他编码器接收的是上一个编码器的输出。
这个列表大小是我们可以设置的超参数——基本上这个参数就是训练数据集中最长句子的长度。
3.2 词嵌入后编码
对输入序列完成嵌入操作后,每个词都会流经编码器的两层。
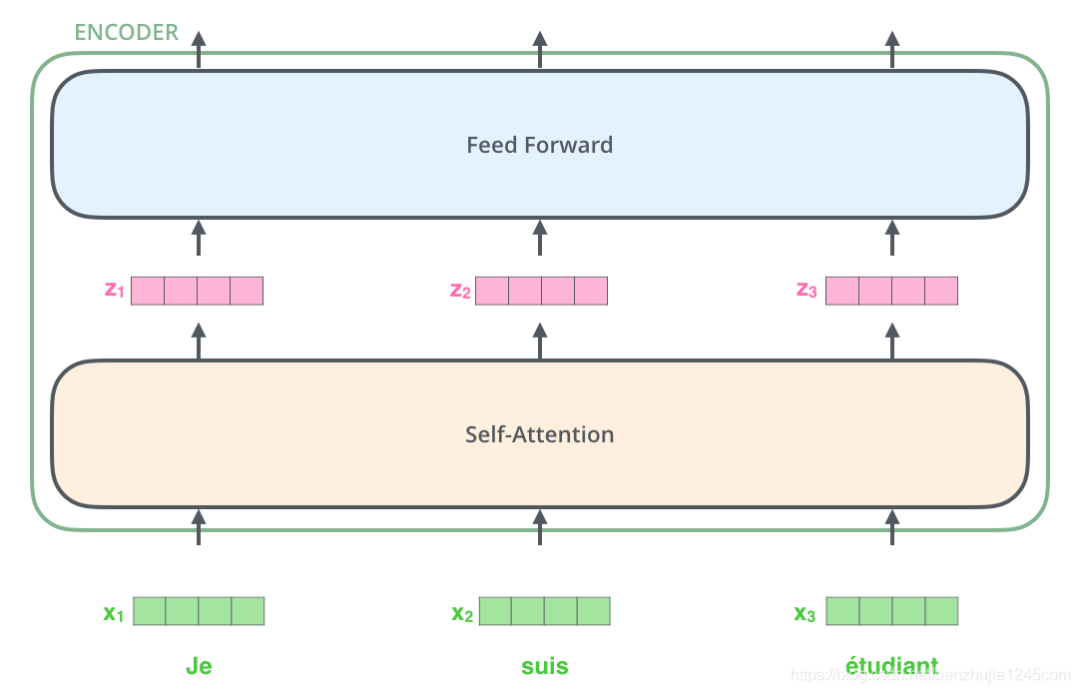
词嵌入与编码
接下来,我们将换一个更短的句子作为示例,来说明在编码器的每个子层中发生了什么。
上面我们提到,编码器会接收一个向量作为输入。编码器首先将这些向量传递到 Self-Attention 层,然后传递到前馈网络,最后将输出传递到下一个编码器。
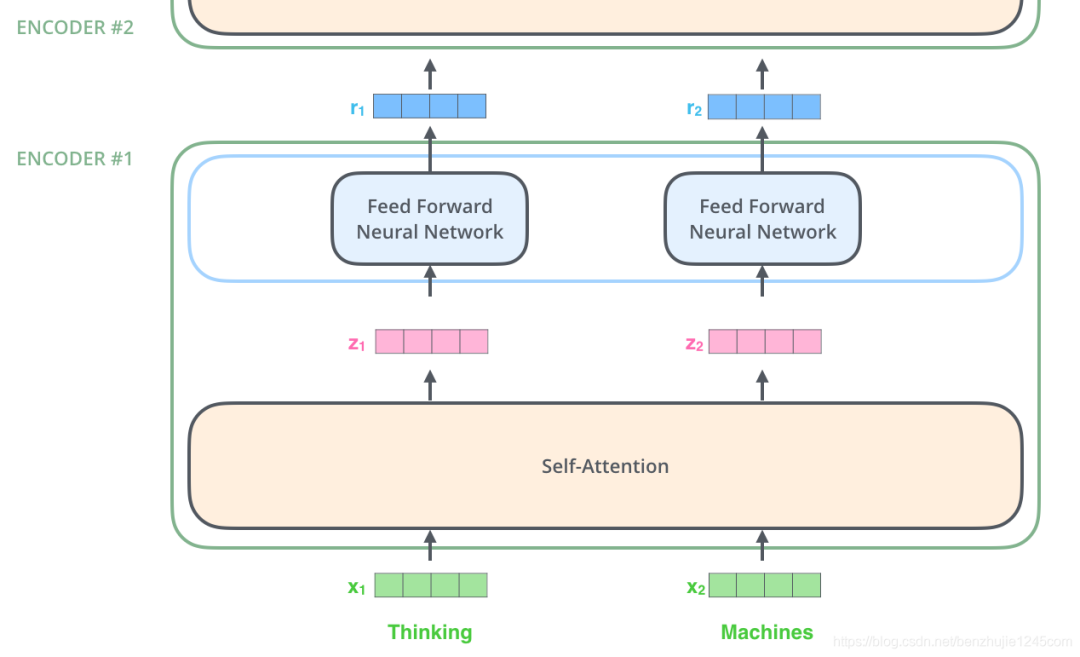
编码器揭秘
4、Self-Attention(自注意力)
4.1 Self-Attention概览
首先我们通过一个例子,来对 Self-Attention 有一个直观的认识。假如我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired 这个句子中的 it 指的是什么?是指 animal 还是 street ?对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention 机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。
如果你熟悉 循环神经网络 RNN,想想如何维护隐状态,使 RNN 将已处理的先前词/向量的表示与当前正在处理的词/向量进行合并。Transformer 使用 Self-Attention 机制将其他词的理解融入到当前词中。

图注:当我们在编码器 #5(堆栈中的顶部编码器)中对单词
it进行编码时,有一部分注意力集中在The animal上,并将它们的部分信息融入到it的编码中。
4.2 Self-Attention机制
下面我们来看一下Self-Attention的具体机制。其基本结构如图所示:
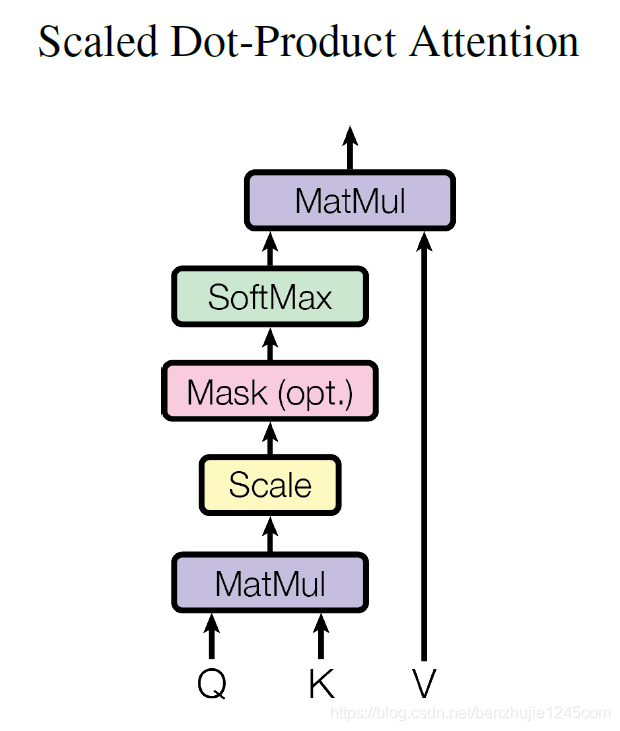
Scaled Dot-Product Attention(缩放点积注意力)
对于 Self Attention 来讲,Q(Query),K(Key)和 V(Value) 三个矩阵均来自同一输入,并按照以下步骤计算:
首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以;其中为 Key 向量的维度。
然后利用Softmax操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。
整个计算过程可以表示为:
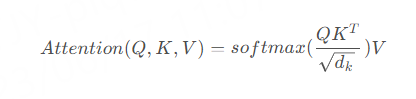
为了更好的理解 Self-Attention,下面我们通过具体的例子进行详细说明。
4.3 Self-Attention详解
下面通过一个例子,让我们看一下如何使用向量计算 Self-Attention。计算Self-Attention的步骤如下:
第 1 步:对编码器的每个输入向量(在本例中,即每个词的词向量)创建三个向量:
Query 向量
Key 向量
Value 向量
它们是通过词向量分别和3个矩阵相乘得到的,这3个矩阵通过训练获得。
请注意,这些向量的维数小于词向量的维数。新向量的维数为
64,而embedding和编码器输入/输出向量的维数为512。新向量不一定非要更小,这是为了使多头注意力计算保持一致的结构性选择。
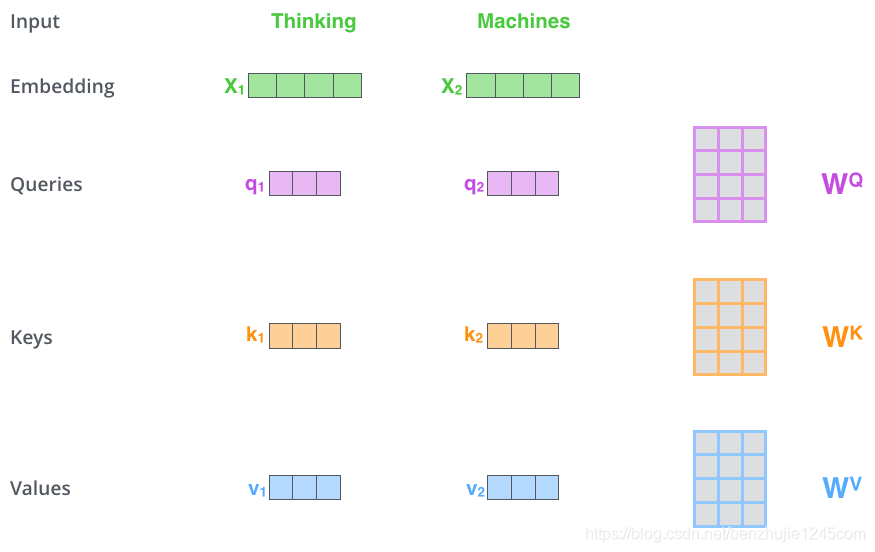
上图中,乘以权重矩阵得到,即与该单词关联的Query向量。
最终会为输入句子中的每个词创建一个 Query,一个 Key 和一个 Value 向量
什么是
Query,Key 和 Value向量?它们是一种抽象,对于注意力的计算和思考非常有用。继续阅读下面的注意力计算过程,你将了解这些向量所扮演的角色。
第 2 步:计算注意力分数。
假设我们正在计算这个例子中第一个词 Thinking 的自注意力。我们需要根据 Thinking 这个词,对句子中的每个词都计算一个分数。这些分数决定了我们在编码 Thinking 这个词时,需要对句子中其他位置的每个词放置多少的注意力。
这些分数,是通过计算 Thinking 的 Query 向量和需要评分的词的Key向量的点积得到的。如果我们计算句子中第一个位置词的注意力分数,则第一个分数是和的乘=点积,第二个分数是和的点积。
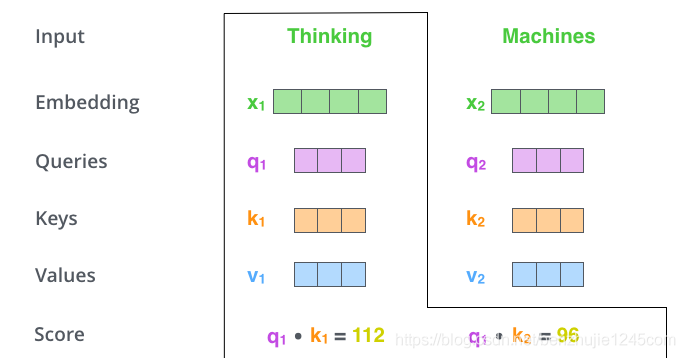
第 3 步:将每个分数除以;其中为 Key 向量的维度。
目的是在反向传播时,求梯度更加稳定。实际上,你也可以除以其他数。
第 4 步:将这些分数进行 Softmax 操作。Softmax 将分数进行归一化处理,使得它们都为正数并且和为1。
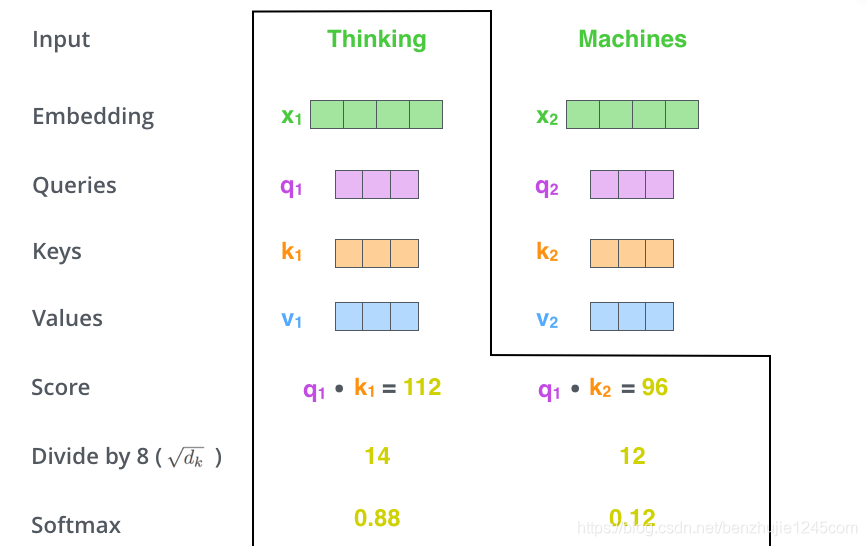
Softmax操作
这些 Softmax 分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力。很明显,当前位置的词汇有最高的分数,但有时注意一下与当前位置的词相关的词是很有用的。
第 5 步:将每个 Softmax 分数分别与每个 Value 向量相乘。
这种做法背后的直觉理解是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放在它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大,我们就可以忽略这些位置的词。
越大越重视
第 6 步:将加权 Value 向量(即上一步求得的向量)求和。这样就得到了自注意力层在这个位置的输出。
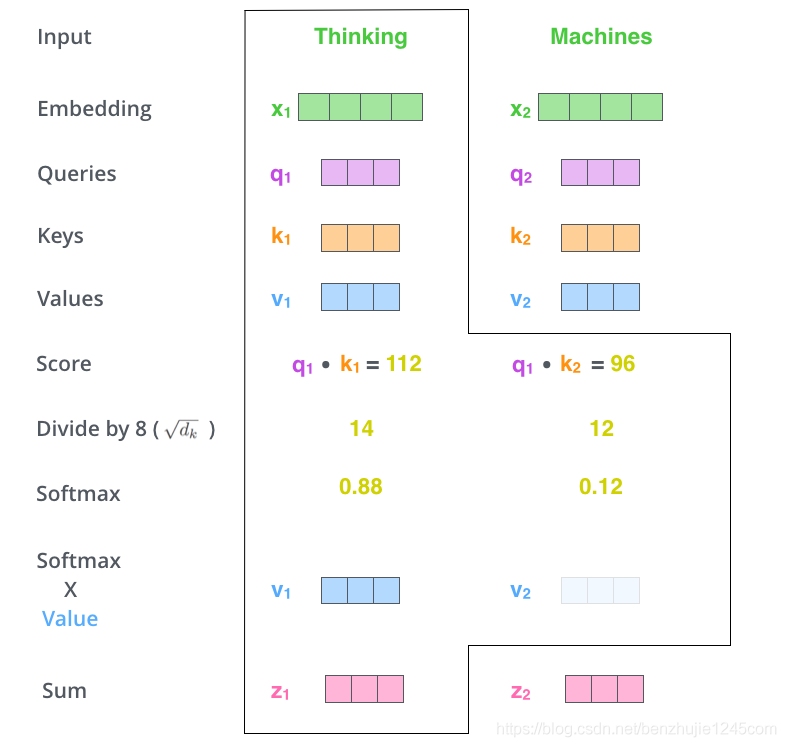
self-attention完整过程
这样就完成了自注意力的计算。生成的向量会输入到前馈网络中。但是在实际实现中,此计算是以矩阵形式进行,以便实现更快的处理速度。下面我们来看看如何使用矩阵计算。
4.4 使用矩阵计算 Self-Attention
第一步:计算Query、Key和Value矩阵。
首先将所有词向量放到一个矩阵X中,然后分别和3个我们训练过的权重矩阵(、、)相乘,即得到、、矩阵。
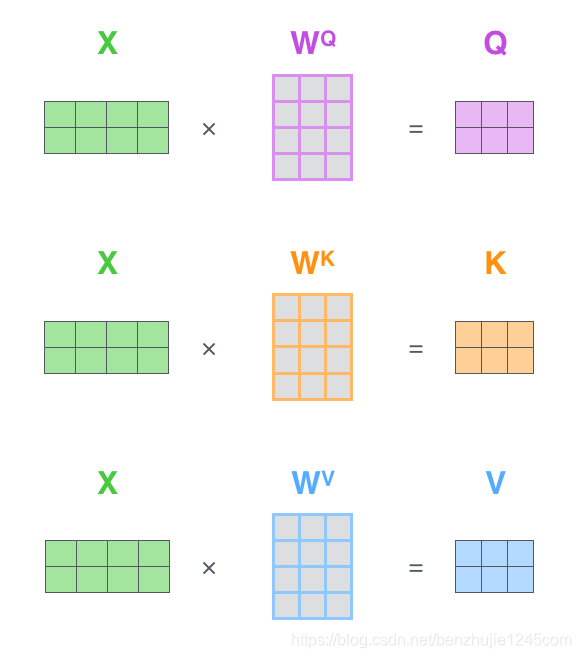
计算QKV矩阵
矩阵 X 中的每一行,表示输入句子中的每一个词的词向量(长度为 512,在图中为 4 个方框)
矩阵Q、K和V 中的每一行,分别表示Query向量,Key向量和Value 向量(它们的长度都为64,在图中为3个方框)。
第2步:计算自注意力。由于这里使用了矩阵进行计算,可以将前面的第 2 步到第 6 步压缩为一步。
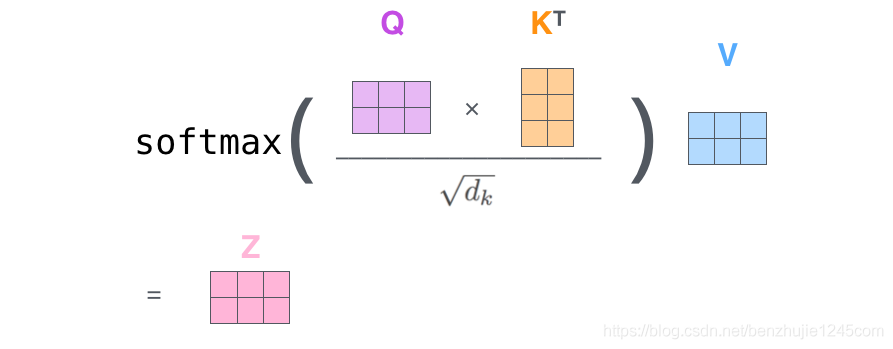
矩阵形式的自注意力计算
5、多头注意力机制(Multi-head Attention)
5.1 多头注意力机制架构
在Transformer论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:
首先,通过个不同的线性变换对Query、Key 和 Value 进行映射;
然后,将不同的 Attention 拼接起来;
最后,再进行一次线性变换。
基本结构如图所示:
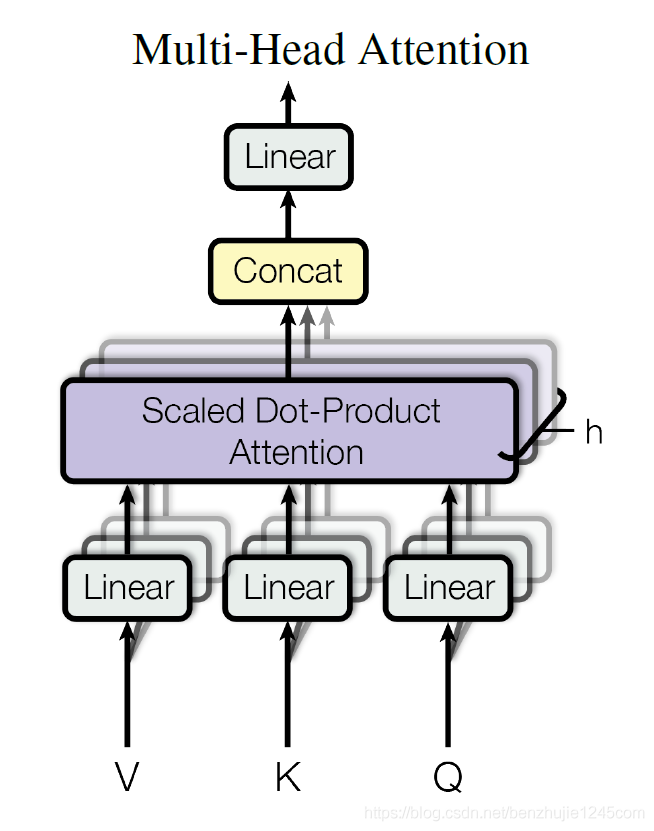
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。整个计算过程可表示为:
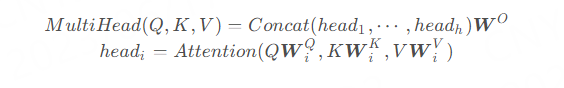
其中:、、和
在论文中,指定h=8,也就是使用8个注意力头,和。
在多头注意力下,我们为每组注意力单独维护不同的Query、Key 和 Value 权重矩阵,从而得到不同的 Query、Key和Value 矩阵。
如前所述,我们将 乘以、、矩阵,得到Query、Key和Value矩阵。
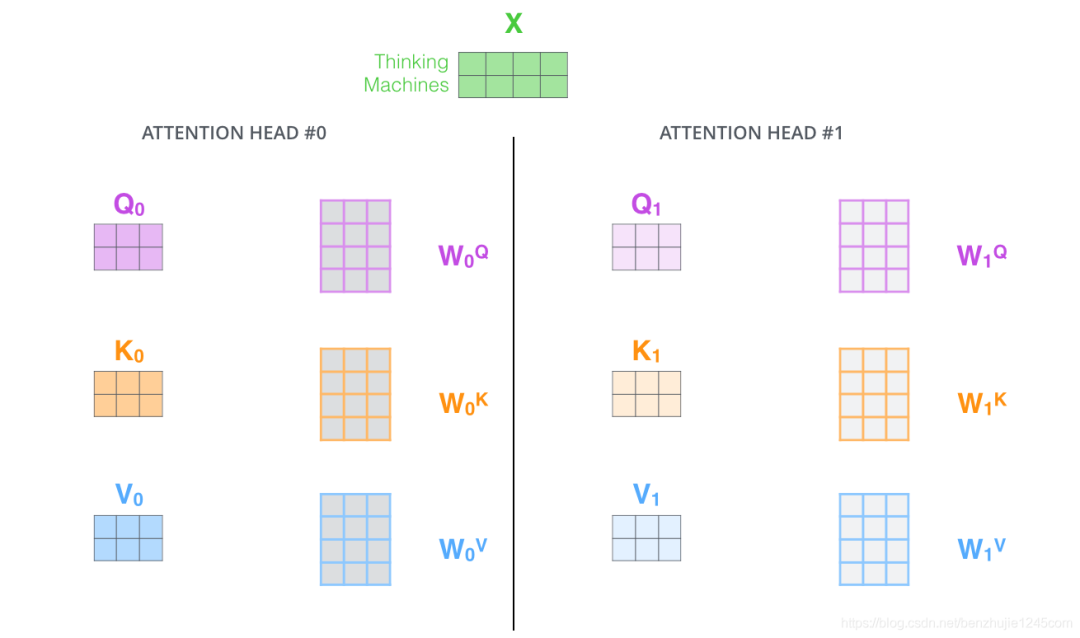
按照上面的方法,使用不同的权重矩阵进行 8 次自注意力计算,就可以得到 8 个不同的 矩阵。
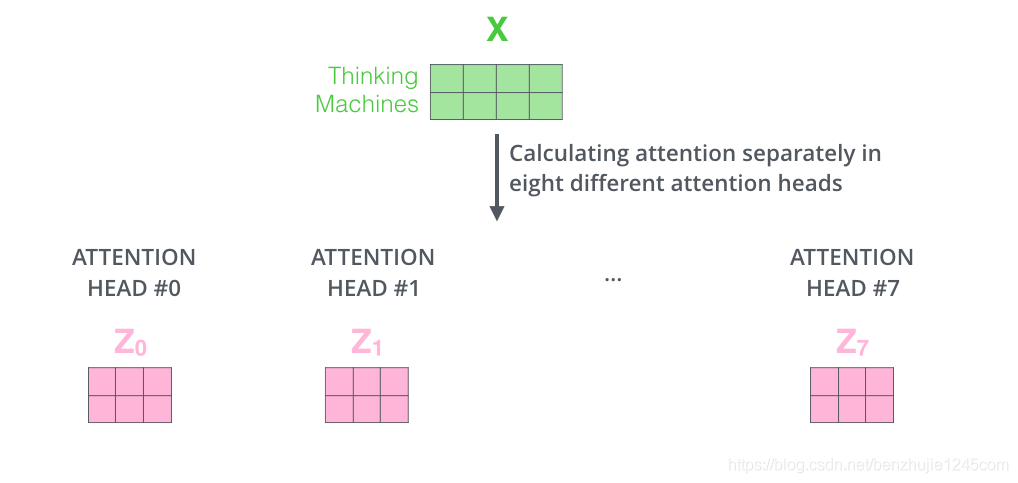
接下来就有点麻烦了。因为前馈神经网络层接收的是 1 个矩阵(每个词的词向量),而不是上面的 8 个矩阵。因此,我们需要一种方法将这 8 个矩阵整合为一个矩阵。具体方法如下:
把8个矩阵拼接起来
把拼接后的矩阵和另一个权重矩阵相乘
得到最终的矩阵,这个矩阵包含了所有注意力头的信息,这个矩阵会输入到FFN层。
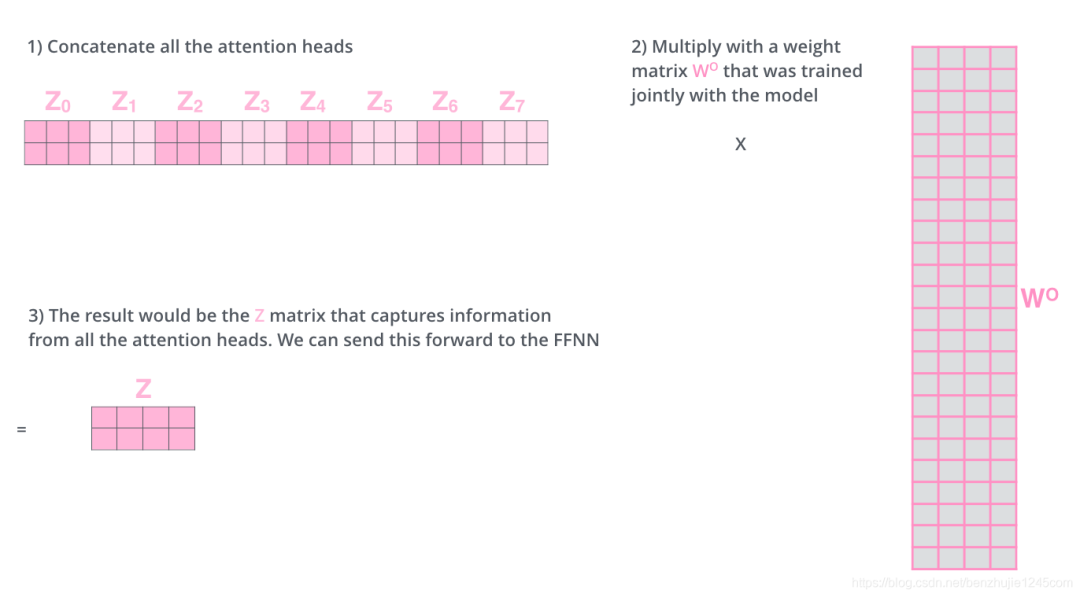
5.2 Multi-head Attention总结
这差不多就是多头注意力的全部内容了。下面将所有内容放到一张图中,以便我们可以统一查看:
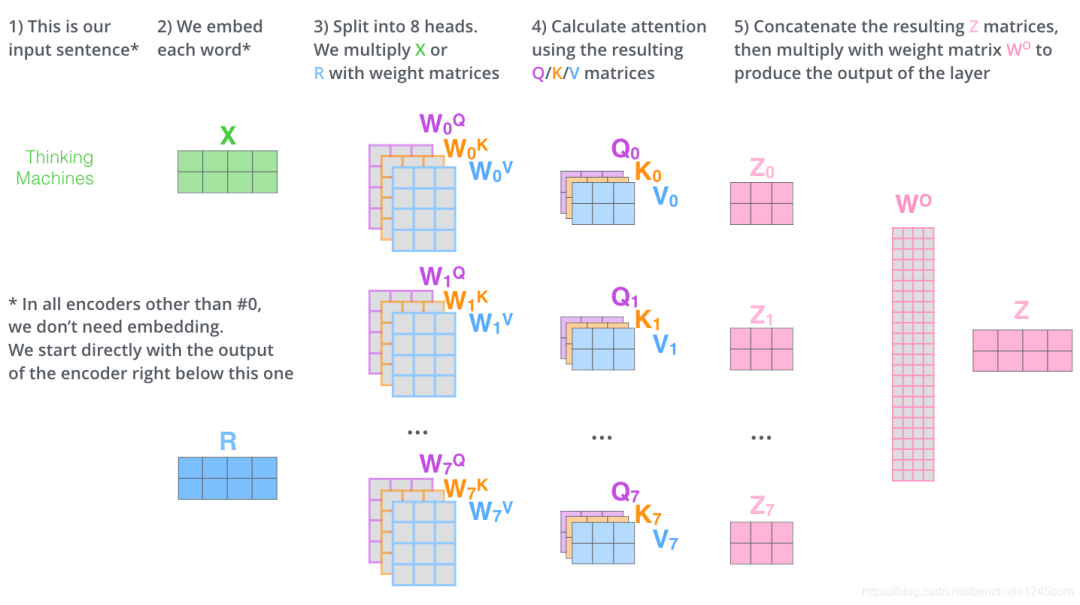
现在让我们重新回顾一下前面的例子,看看在对示例句中的“it”进行编码时,不同的注意力头关注的位置分别在哪:

当我们对it进行编码时,一个注意力头关注The animal,另一个注意力头关注tired。从某种意义上来说,模型对it的表示,融入了animal和tired的部分表达。
Multi-head Attention 的本质是:在参数总量保持不变的情况下,将同样的Query,Key,Value 映射到原来的高维空间的不同子空间中进行Attention的计算,在最后一步再合并不同子空间中的Attention信息。
这样降低了计算每个 head 的 Attention 时每个向量的维度,在某种意义上防止了过拟合。
由于 Attention 在不同子空间中有不同的分布,Multi-head Attention 实际上是寻找了序列之间不同角度的关联关系,并在最后拼接这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
6、位置前馈网络(Position-wise Feed-Forward Networks)
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。
其由两个线性变换组成,即两个全连接层组成,第一个全连接层的激活函数为 ReLU 激活函数。可以表示为:
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。整个前馈网络的输入和输出维度都是,第一个全连接层的输出和第二个全连接层的输入维度为
7、残差连接和层归一化
编码器结构中有一个需要注意的细节:每个编码器的每个子层(Self-Attention 层和 FFN 层)都有一个残差连接,再执行一个层标准化操作,整个计算过程可以表示为:
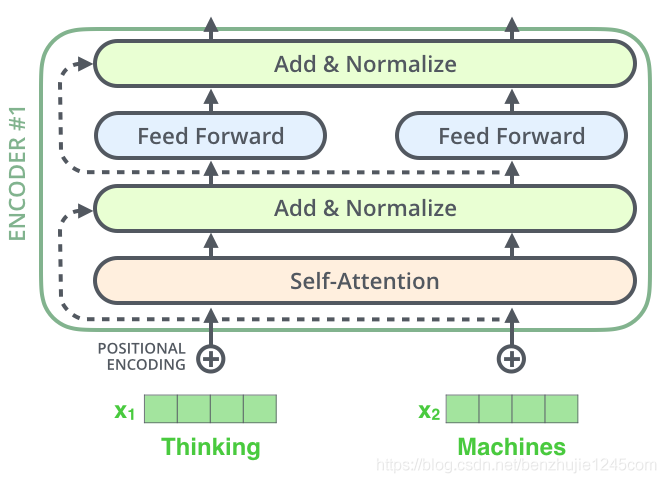
将向量和自注意力层的层标准化操作可视化,如下图所示:
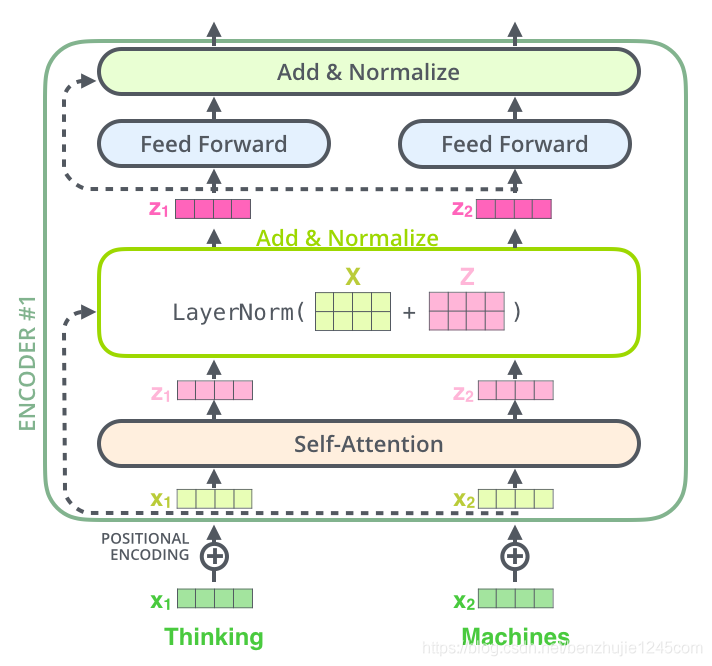
上面的操作也适用于解码器的子层。假设一个 Transformer 是由 2 层编码器和 2 层解码器组成,其如下图所示:
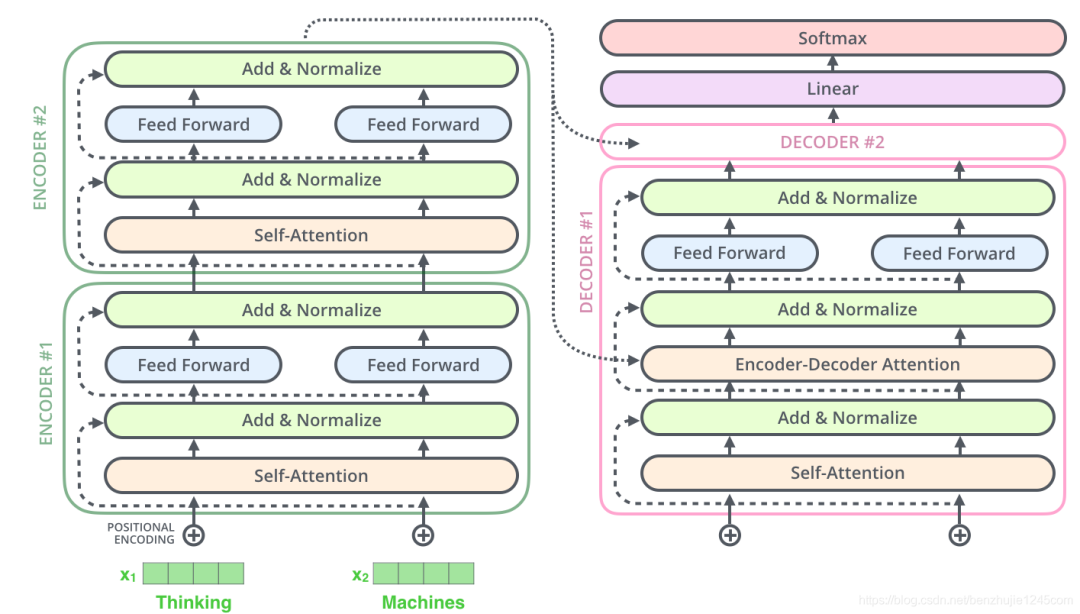
为了方便进行残差连接,编码器和解码器中的所有子层和嵌入层的输出维度需要保持一致,在 Transformer 论文中
8、位置编码
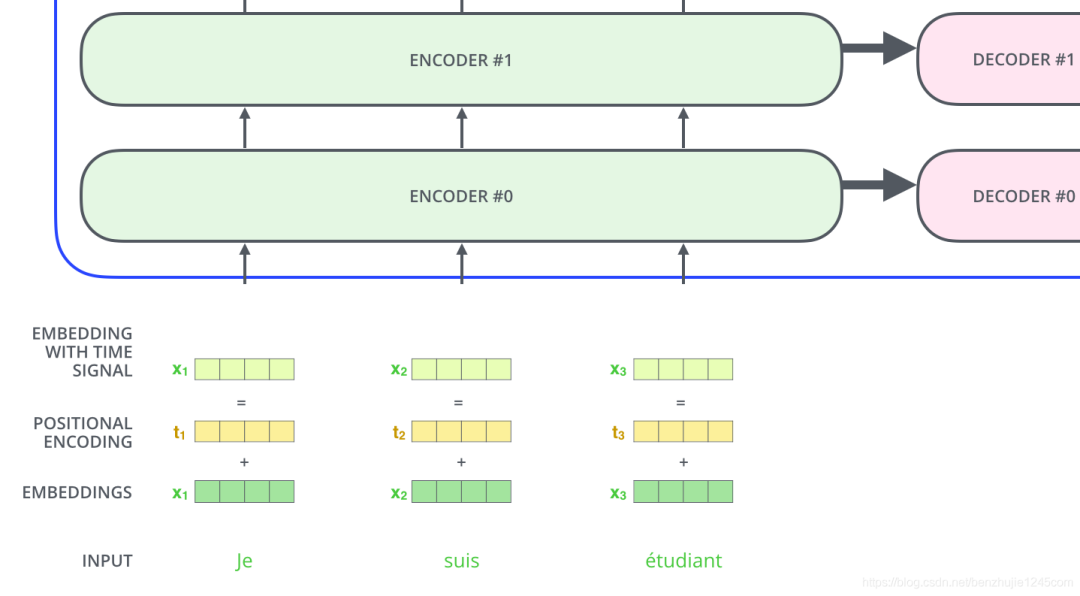
到目前为止,我们所描述的模型中缺少一个东西:表示序列中词顺序的方法。为了解决这个问题,Transformer 模型为每个输入的词嵌入向量添加一个向量。
这些向量遵循模型学习的特定模式,有助于模型确定每个词的位置,或序列中不同词之间的距离。
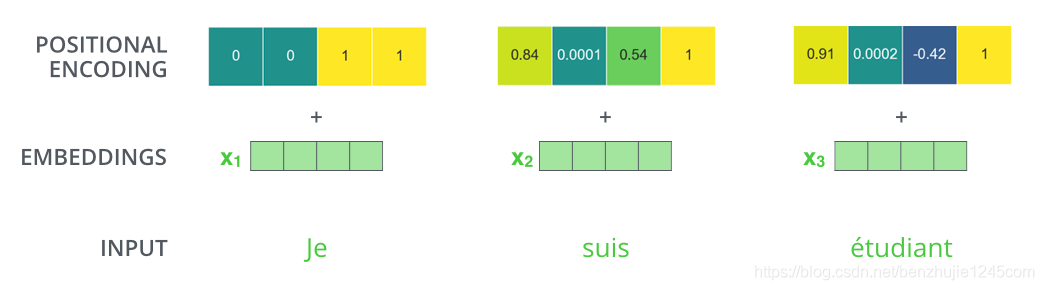
如果我们假设词嵌入向量的维度是 4,那么实际的位置编码如下:
那么位置编码向量到底遵循什么模式?其具体的数学公式如下:
其中表示位置,表示维度。上面的函数使得模型可以学习到 之间的相对位置关系:任意位置的都可以被的线性函数表示:
在下图中,我们将这些值进行可视化。每一行对应一个向量的位置编码。所以第一行对应于输入序列中第一个词的位置编码。每一行包含 64 个值,每个值的范围在 -1 和 1 之间
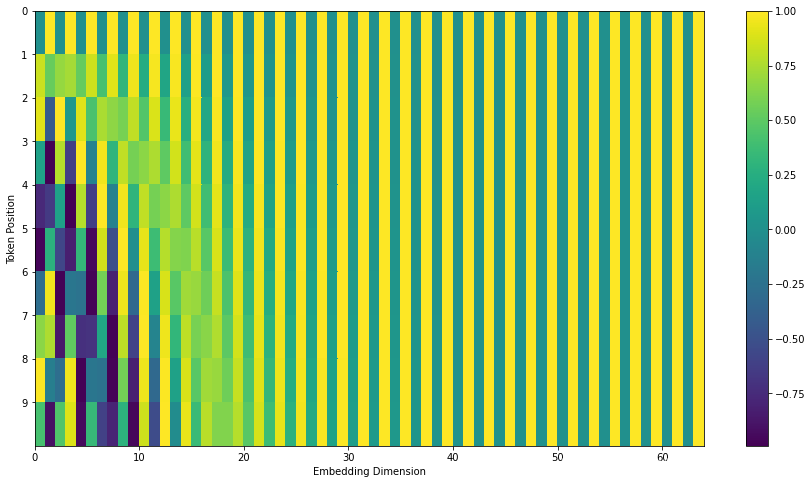
需要注意的是,官方提供的示例代码(TensorFlow 1.x 版本中的 get_timing_signal_1d() 函数和 TensorFlow 2.x 版本 中的 call() 函数)与 Transformer 论文中的方法稍微存在一定差异:
Transformer 论文中,sine 函数和 cosine 函数产生的值交织在一起;
而官方提供的代码中,左半部分的值全是由 sine 函数产生的,右半部分的值全是由 cosine 函数产生的,然后将它们拼接起来。
官方代码生成的位置编码值的可视化图如下:
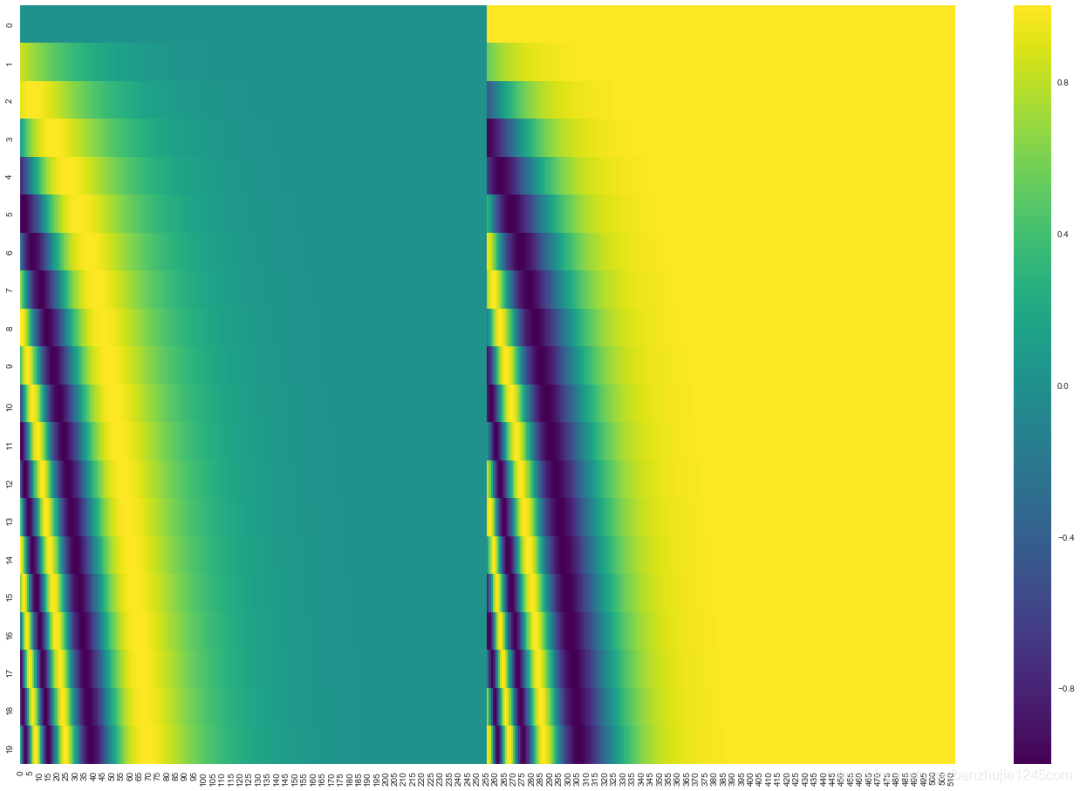
这不是唯一一种生成位置编码的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如,当我们训练后的模型被要求翻译一个句子,而这个句子的长度大于训练集中所有句子的长度。
9、解码器Decoder
现在我们已经介绍了编码器的大部分概念,我们也了解了解码器的组件的原理。现在让我们看下编码器和解码器是如何协同工作的。
通过上面的介绍,我们已经了解第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置。
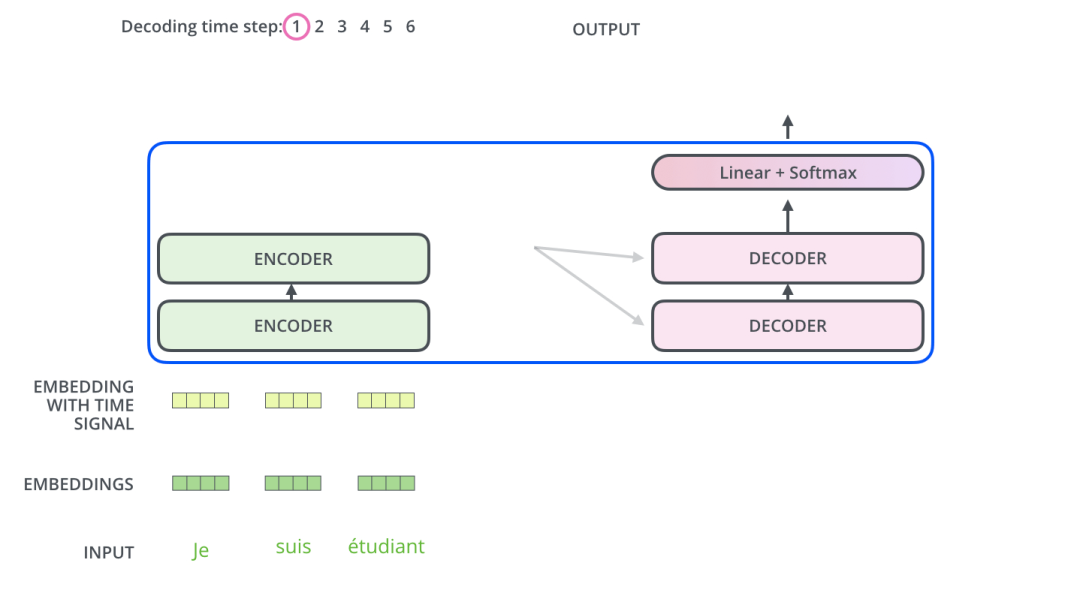
在完成了编码阶段后,我们开始解码阶段。解码阶段的每个时间步都输出一个元素。
接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入加上位置编码,来指示每个词的位置。
Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于编码器栈的输出。
10、掩码Mask
Mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 Padding Mask 和 Sequence Mask。
Padding Mask 在所有的 scaled dot-product attention 里面都需要用到
而Sequence Mask 只有在解码器 Decoder 的 Self-Attention 里面用到。
10.1 Padding Mask
什么是 Padding mask 呢?因为每个批次输入序列的长度是不一样的,所以我们要对输入序列进行对齐。
具体来说:就是在较短的序列后面填充 0(但是如果输入的序列太长,则是截断,把多余的直接舍弃)。因为这些填充的位置,其实是没有什么意义的,所以我们的 Attention 机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法:把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过Softmax 后,这些位置的概率就会接近0。
10.2 Sequence Mask
Sequence Mask是为了使得 Decoder 不能看见未来的信息。也就是对于一个序列,在时刻,我们的解码输出应该只能依赖于时刻之前的输出,而不能依赖之后的输出。因为我们需要想一个办法,把之后的信息给隐藏起来。
具体的做法:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每个序列上,就可以达到我们的目的。
总结:对于Decoder的Self-Attention,里面使用到的scaled dot-product attention,同时需要Padding Mask 和Sequence Mask,具体实现就是两个Mask相加。其他情况下,只需要Padding Mask。
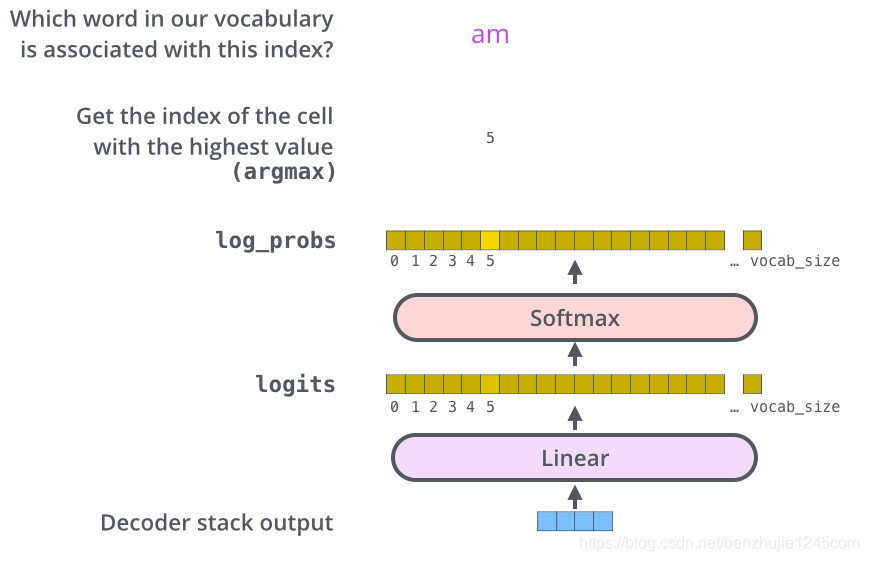
11、最后的线性层和 Softmax 层
解码器栈的输出是一个 float向量。我们怎么把这个向量转换为一个词呢?通过一个线性层再加上一个Softmax层实现。
11.1 线性层
线性层是一个简单的全连接神经网络,其将解码器栈的输出向量映射到一个更长的向量,这个向量被称为logits向量。
11.2 Softmax层
现在假设我们的模型有 10000 个英文单词(模型的输出词汇表)。因此 logits 向量有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。最后选择最高概率所对应的单词,作为这个时间步的输出。
12、嵌入层和最后的线性层
在 Transformer 论文,提到一个细节:编码组件和解码组件中的嵌入层,以及最后的线性层共享权重矩阵。
需要注意的是:在嵌入层中,会将这个共享权重矩阵乘以
13、正则化操作
为了提高 Transformer 模型的性能,在训练过程中,使用了以下的正则化操作:
Dropout。对编码器和解码器的每个子层的输出使用Dropout 操作,是在进行残差连接和层归一化之前。词嵌入向量和位置编码向量执行相加操作后,执行Dropout操作。Transformer 论文中提供的参数
Label Smoothing(标签平滑)。Transformer论文中提供的参数是。
14、参考
英文原地址:The Illustrated Transformer
Attentions Is All You Need
图解Transformer
详解Transformer (Attention Is All You Need)
理解语言的Transformer
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓