[嵌入式AI从0开始到入土]嵌入式AI系列教程
注:等我摸完鱼再把链接补上
可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。
第1期 昇腾Altas 200 DK上手
第2期 下载昇腾案例并运行
第3期 官方模型适配工具使用
第4期 炼丹炉的搭建(基于Ubuntu23.04 Desktop)
第5期 炼丹炉的搭建(基于wsl2_Ubuntu22.04)
第6期 Ubuntu远程桌面配置
第7期 下载yolo源码及样例运行验证
第8期 在线Gpu环境训练(基于启智ai协作平台)
第9期 转化为昇腾支持的om离线模型
第10期 jupyter lab的使用
第11期 yolov5在昇腾上推理
第12期 yolov5在昇腾上应用
第13期_orangepi aipro开箱测评
第14期 orangepi_aipro小修补含yolov7多线程案例
第15期 orangepi_aipro欢迎界面、ATC bug修复、镜像导出备份
第16期 ffmpeg_ascend编译安装及性能测试
第17期 Ascend C算子开发
未完待续…
文章目录
[嵌入式AI从0开始到入土]嵌入式AI系列教程前言一、环境配置1、CANN包安装2、配置ssh密钥(可选)3、配置git(可选) 二、获取sample样例1、add算子1、KernelLaunch2、Framework3、AclNN 2、Addcdiv算子 三、编写自己的算子1、搭建框架2、 KernelLaunch编写1、myCustom.cpp2、main.cpp3、scripts/gen_data.py 3、 framework编写4、 Aclnn测试 四、torch_npu重新编译(可选)五、常用api问题1、fatal error: register/tilingdata_base.h: No such file or directory 总结
前言
我在24年3月和我的小伙伴一起参加了第一届昇腾AI原生创新精英挑战赛,在这里做一下总结。这里以orangepi Ai Pro为例。
注:我们的代码仓最早将于24.05.10开放,大家可以直接看op_kernel内的compute,kernelLaunch内可能有错,实在来不及改了
代码仓地址:https://gitee.com/toolsmanhehe/acl_ops
一、环境配置
我们基于正常能够使用的镜像作为基础镜像。这里我推荐使用minimal镜像。这样就不用先卸载cann了,甚至你可以直接删除/opt/compress目录,反正咱后面直接远程连接敲代码了,也用不上。
1、CANN包安装
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC702/Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.runchmod +x Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run#卸载旧的CANN./Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run --uninstallsudo rm -rf /usr/local/Ascend/ascend-toolkit/*#安装指定版本的CANN./Ascend-cann-toolkit_8.0.RC1.alpha002_linux-aarch64.run --install#安装依赖pip install protobuf==3.20.0#添加环境变量echo “source /usr/local/Ascend/ascend-toolkit/set_env.sh” >> /home/HwHiAiUser/.bashrcsource /home/HwHiAiUser/.bashrc2、配置ssh密钥(可选)
主要是vscode等ide连接时都需要输入密码,比较麻烦。
这里可以参考我之前的文章来实现免密登录,在七、问题 的第5点
3、配置git(可选)
因为我们三个人在三个城市,因此为了方便讨论和开发,我们建立了代码仓库,但是每次推送和拉取都需要账号密码(在完赛前是不可能公开的),这不符合本懒人的性格啊。
这里我们需要在开发环境上执行
cd ~touch .git-credentialsvim .git-credentials#输入以下内容,请自行替换username和passwordhttps://username:password@gitee.comgit config --global credential.helper store二、获取sample样例
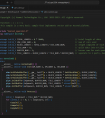
cd git clone https://gitee.com/ascend/samples.git在不修改算子名称,输入输出的时候,我们只需要关注图中框出来的文件即可。
1、add算子
打开目录operator/AddCustomSample
1、KernelLaunch
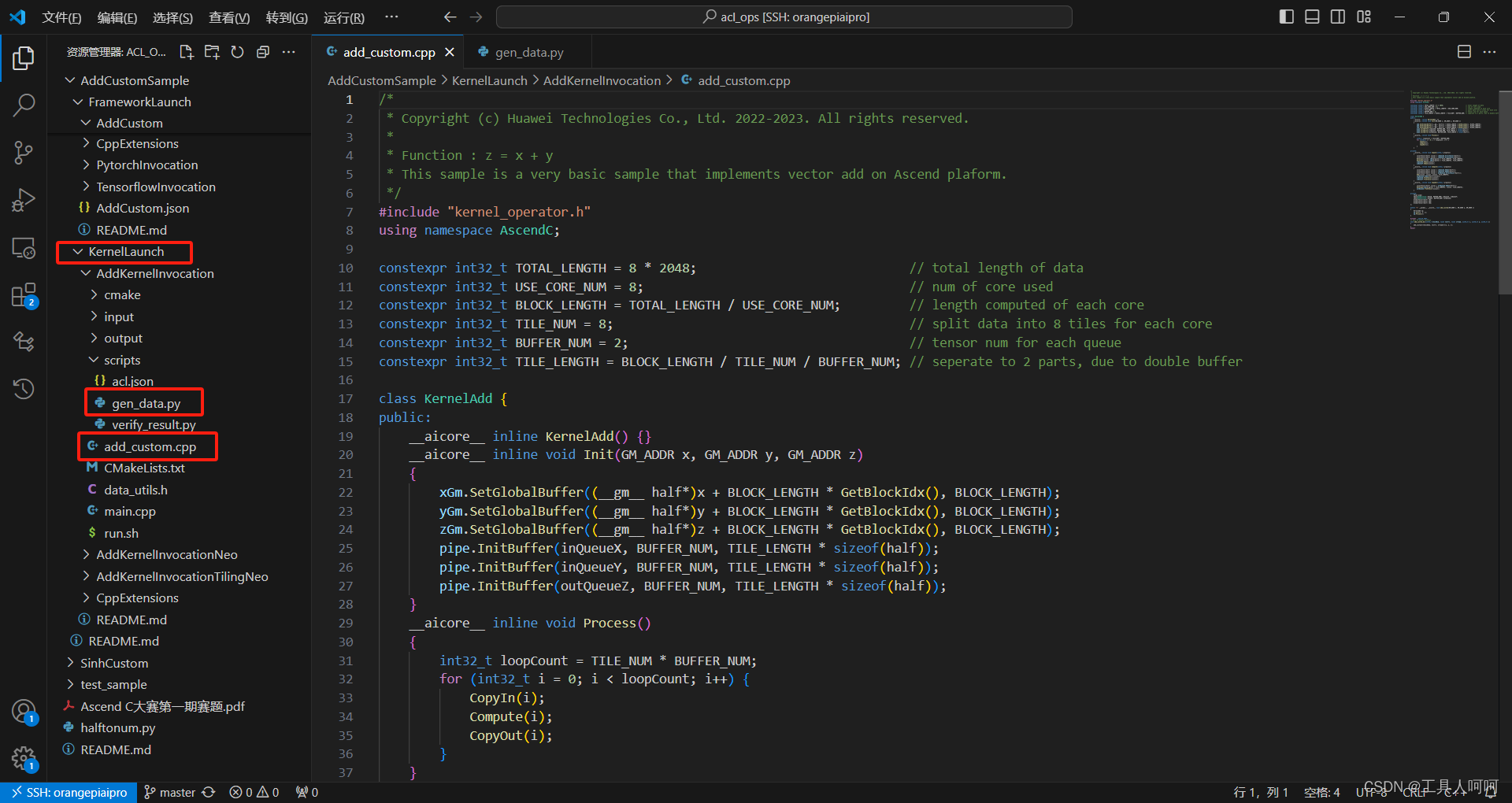
我们的调用顺序是main.cpp->add_custom_do->add_custom->op.Init->op.Process。
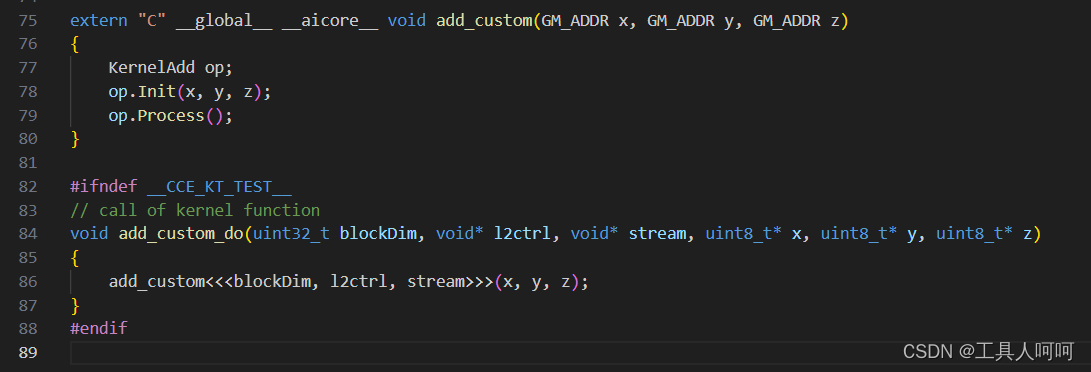
因为我们要实现的算子的Z=X+Y,因此我们需要将这三个变量传入计算过程。
虽然这里只有2个输入,但是输出也需要申请内存,因此是3个输入参数
然后我们需要申明相关的变量和常量(这里使用静态shape)。
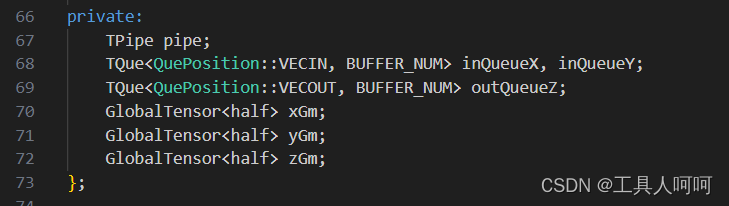

接着就是初始化,为各个张量申请内存
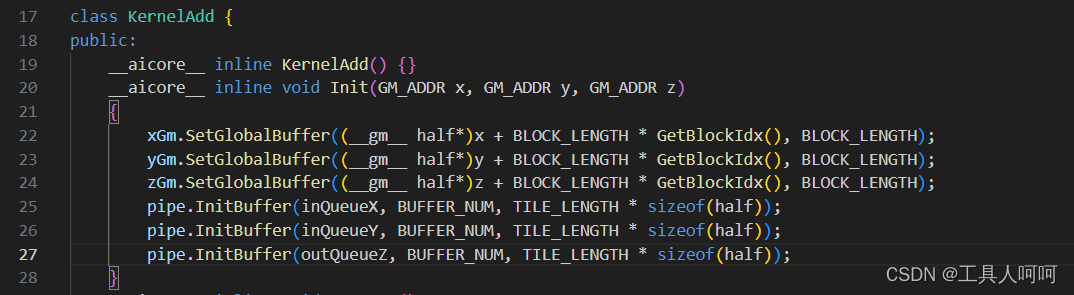
接着就是计算过程,这里因为使用的是静态shape,因此循环次数是定值(芯片内存空间有限,不可能一次性全部计算完成)
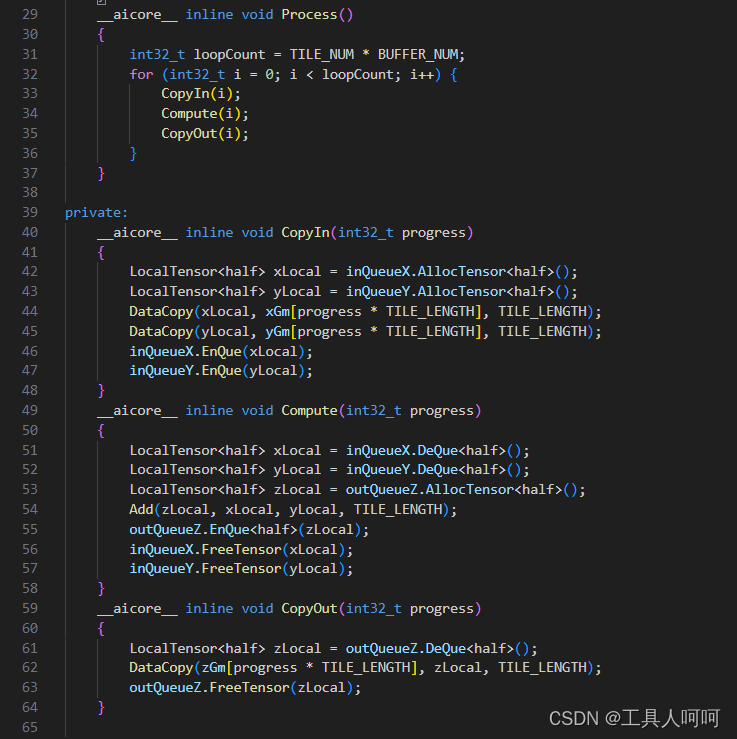
在copyin的时候从xGM和yGM分别取出TILE_LENGTH个数据,存入xLocal和yLocal以供compute使用。
在compute结束以后,我们需要先使用outQueueZ.EnQue来表示计算完成,但是此时不能释放zLocal的内存,因为我们还没有保存到zGM。
在copyout环节,将输出结果存入zGM。
接着我们看生成测试数据的程序,这里我们生成了2条16384个1~100随机half格式的数据。我们最后可以直接对比output/golden.bin和output/output_z.bin的md5值来判断算子正确与否。或者修改scripts/verify_result.py直接打印误差数量。
最后来到KernelLaunch目录执行以下命令,测试核函数正确性。
务必先进行cpu测试,通过后执行npu测试,在npu下有些报错不显示
su #使用root用户执行,否则可能报错bash run.sh -r cpu -v ascend310B1 #cpu测试bash run.sh -r npu -v ascend310B1 #npu测试以下为cpu测试结果
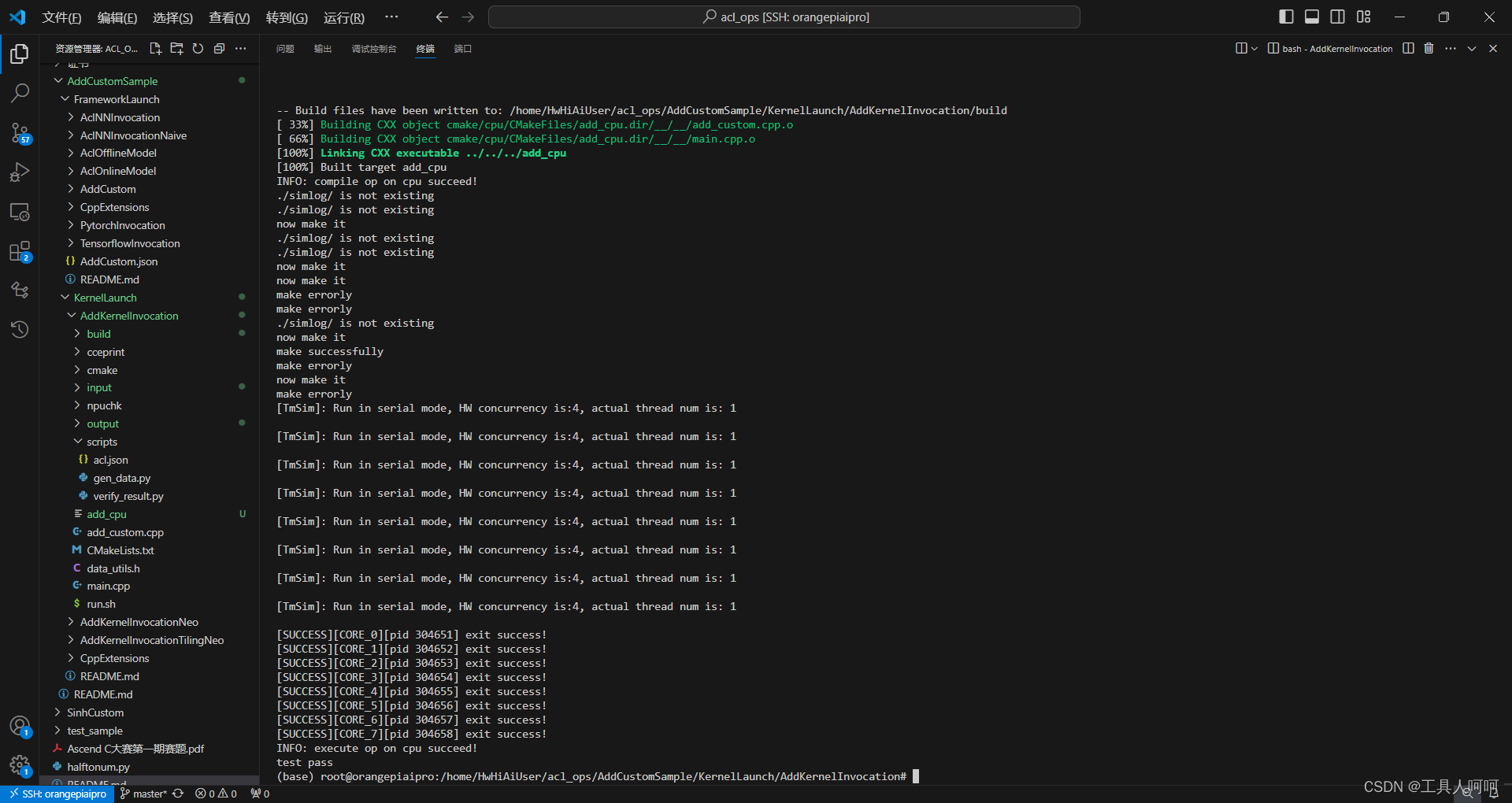
以下为npu测试结果
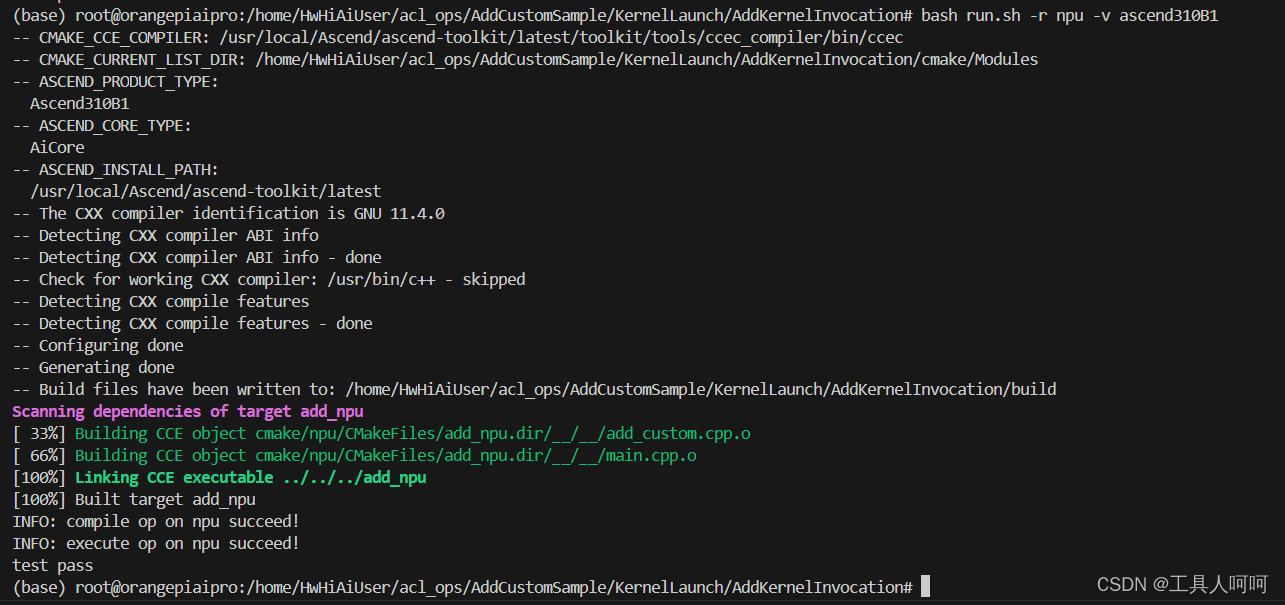
测试均通过的情况下,我们就可以进行下一步的framework的编写了
2、Framework
我们先看AddCustomSample/FrameworkLaunch/AddCustom.json这个文件,上面为输入变量,下面为输出变量。我们需要使用这个配置文件来生成framework工程。此处的变量应该和工程内的一致。
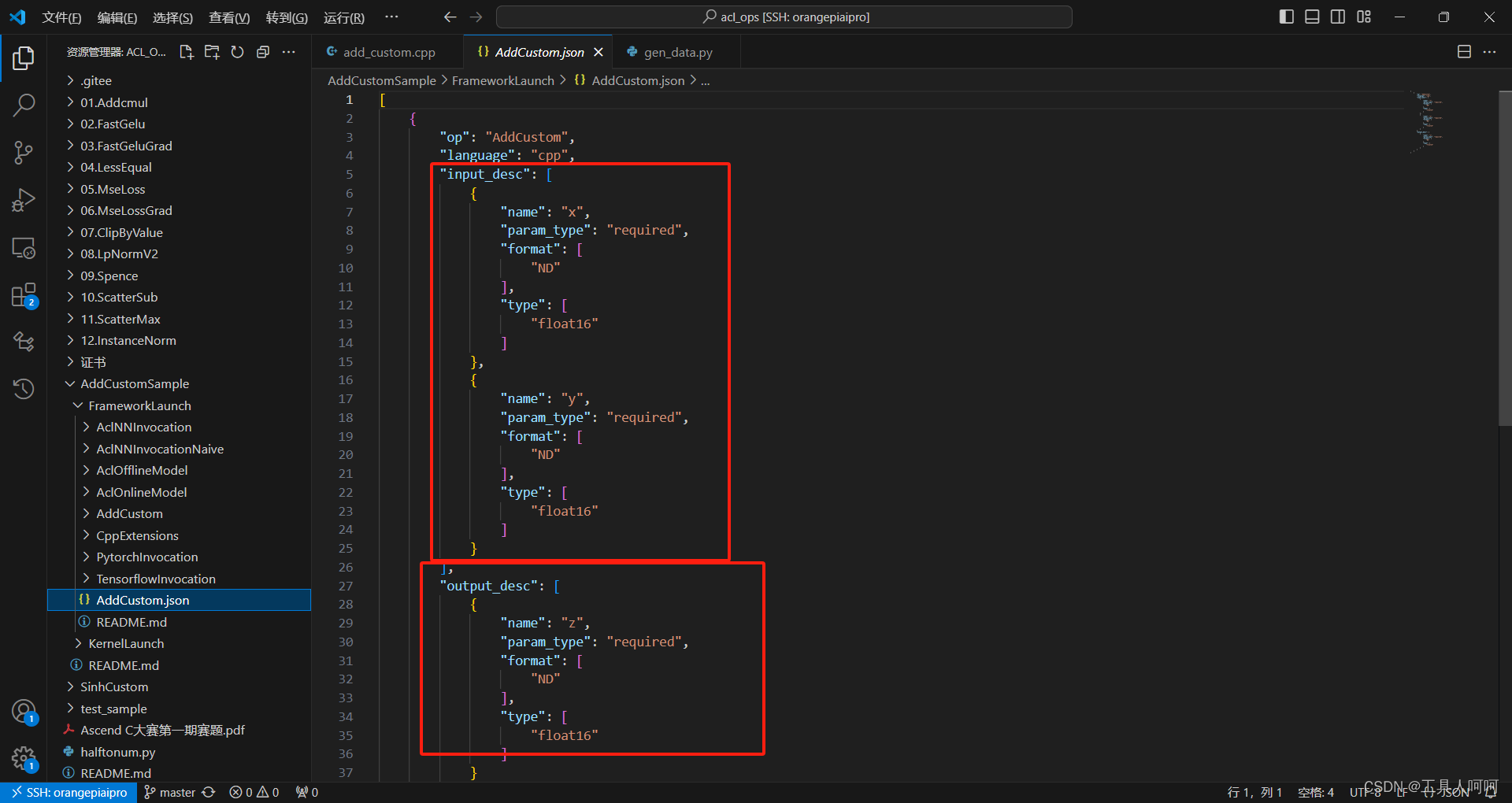
接着我们看工程。
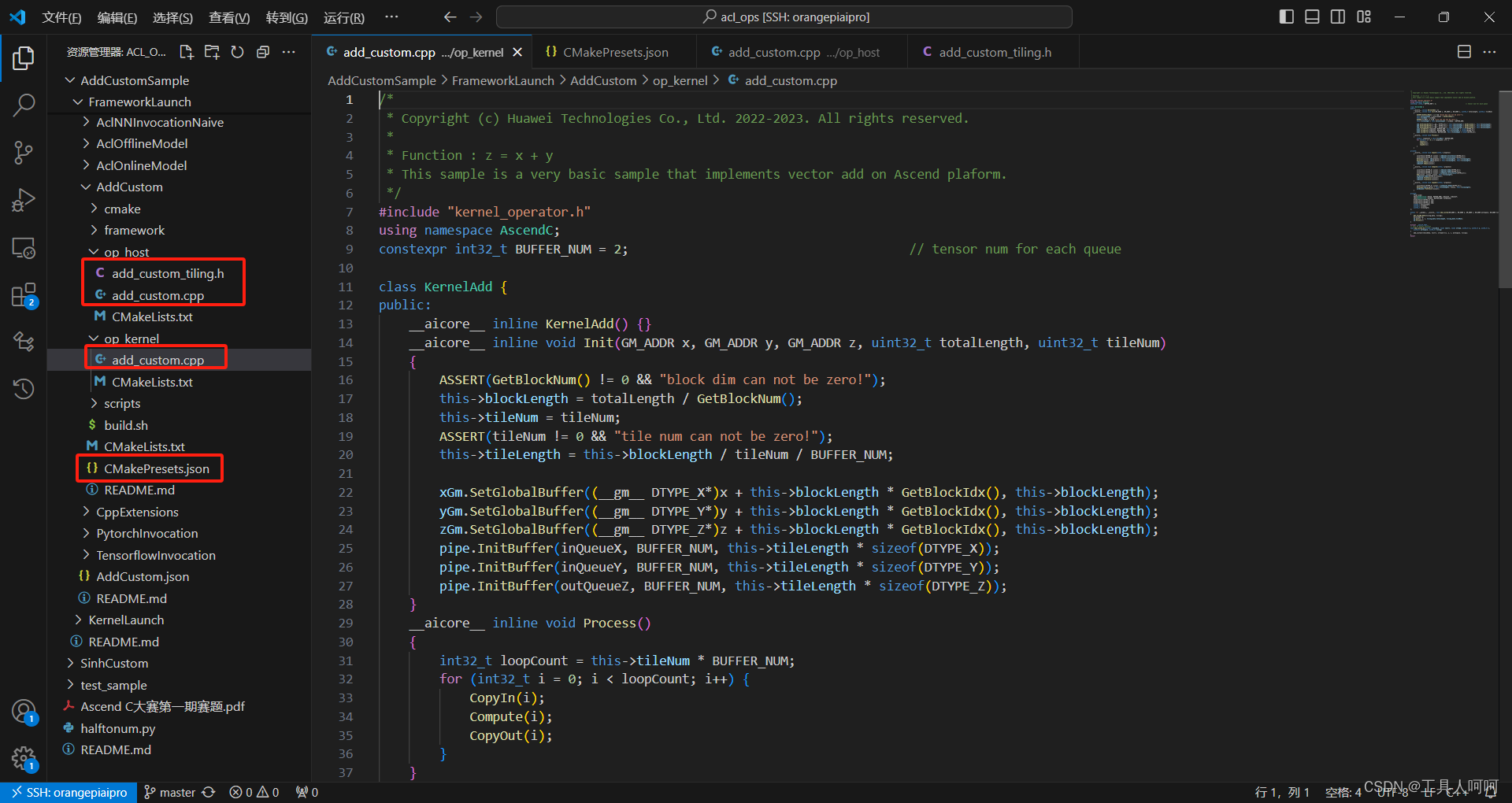
op_host没什么可说的,可以去看本文下一个案例Addcdiv。
op_kernel基本上就是把上面在kernelLaunch中测试通过的代码cv过来。
注意图中的地方就可以了,这个tiling是从host侧传入的。然后在开头将静态shape删除了,因为这里我们是通过op_host实现的动态shape的切分,然后传入kernel侧的。
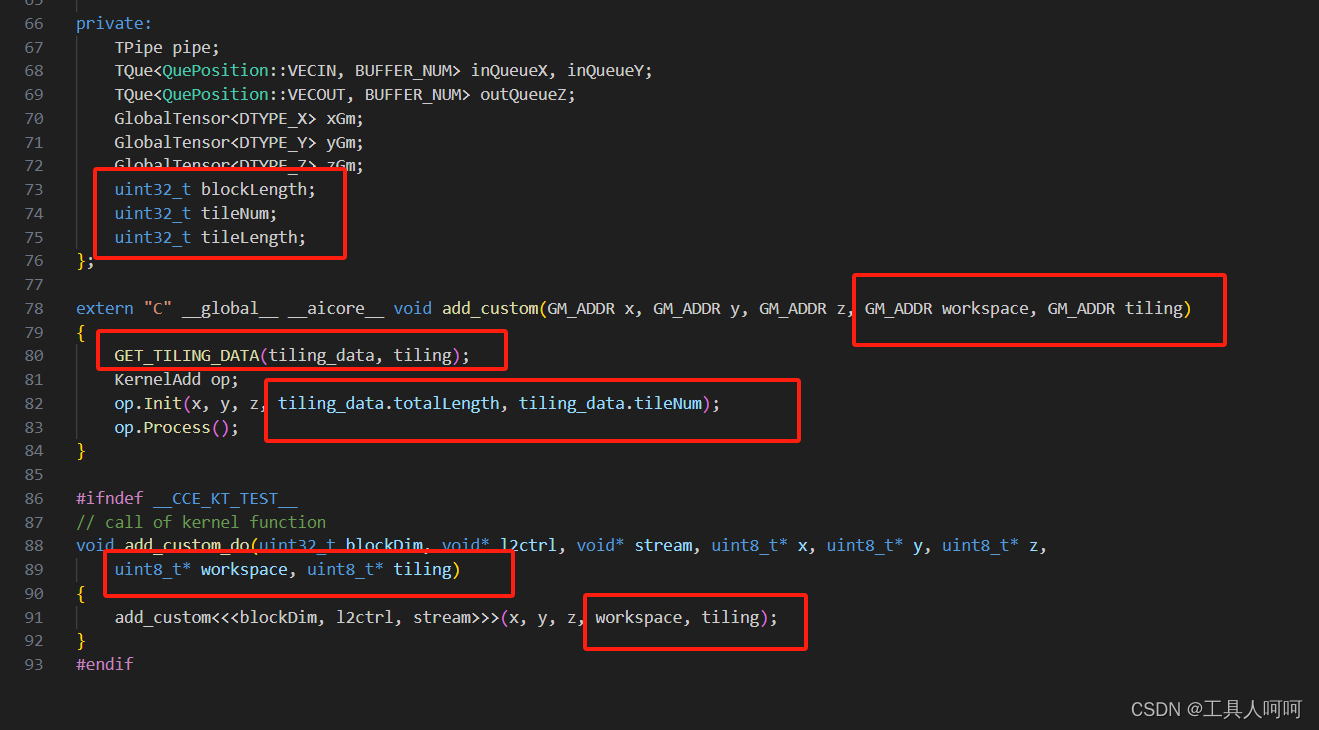
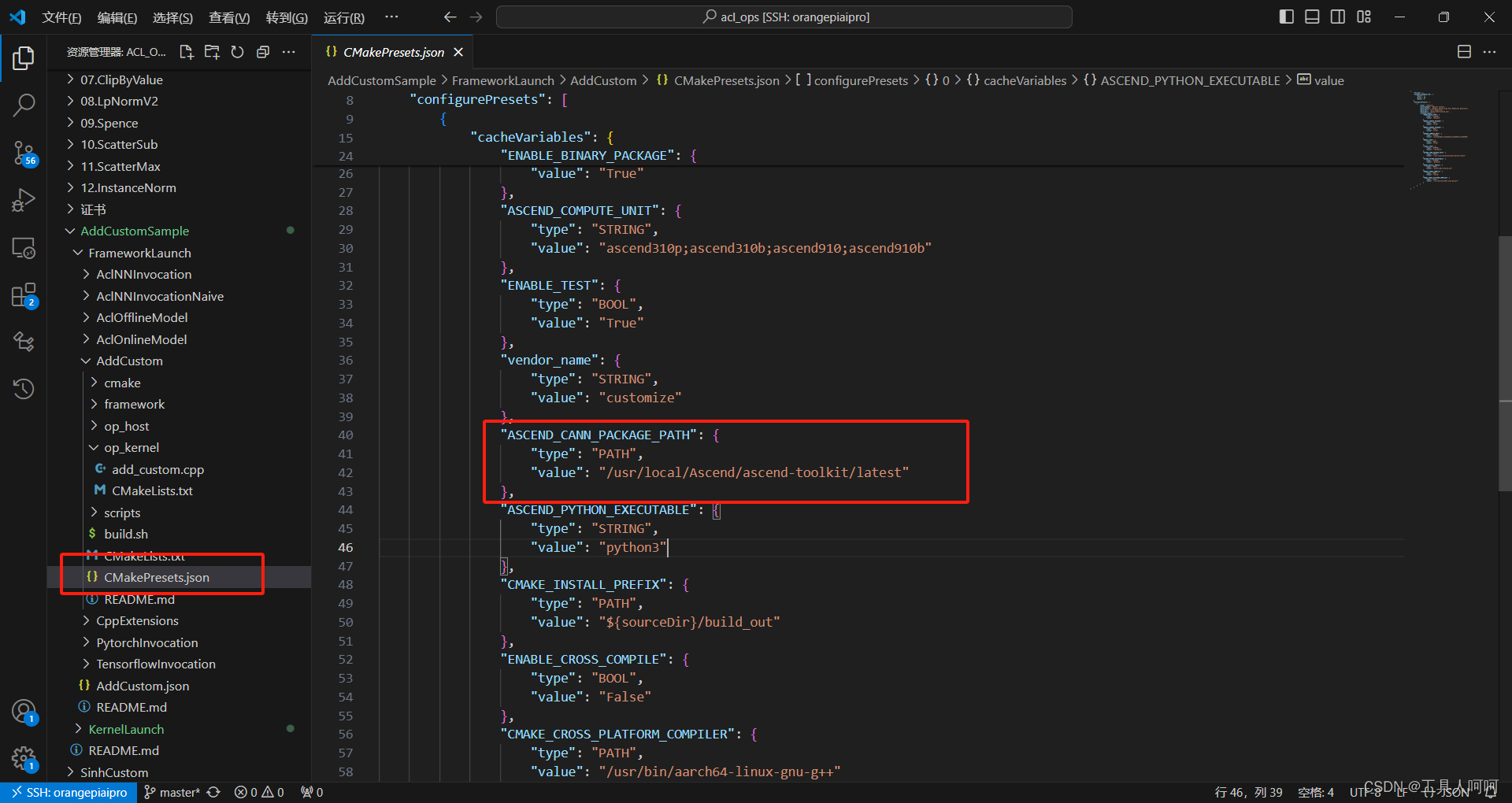
接下来修改CMakePresets.json,将框出来的地方改成你的CANN路径。
最后,我们进入framework目录,编译算子并安装
bash build.sh./build_out/custom_opp_ubuntu_aarch64.run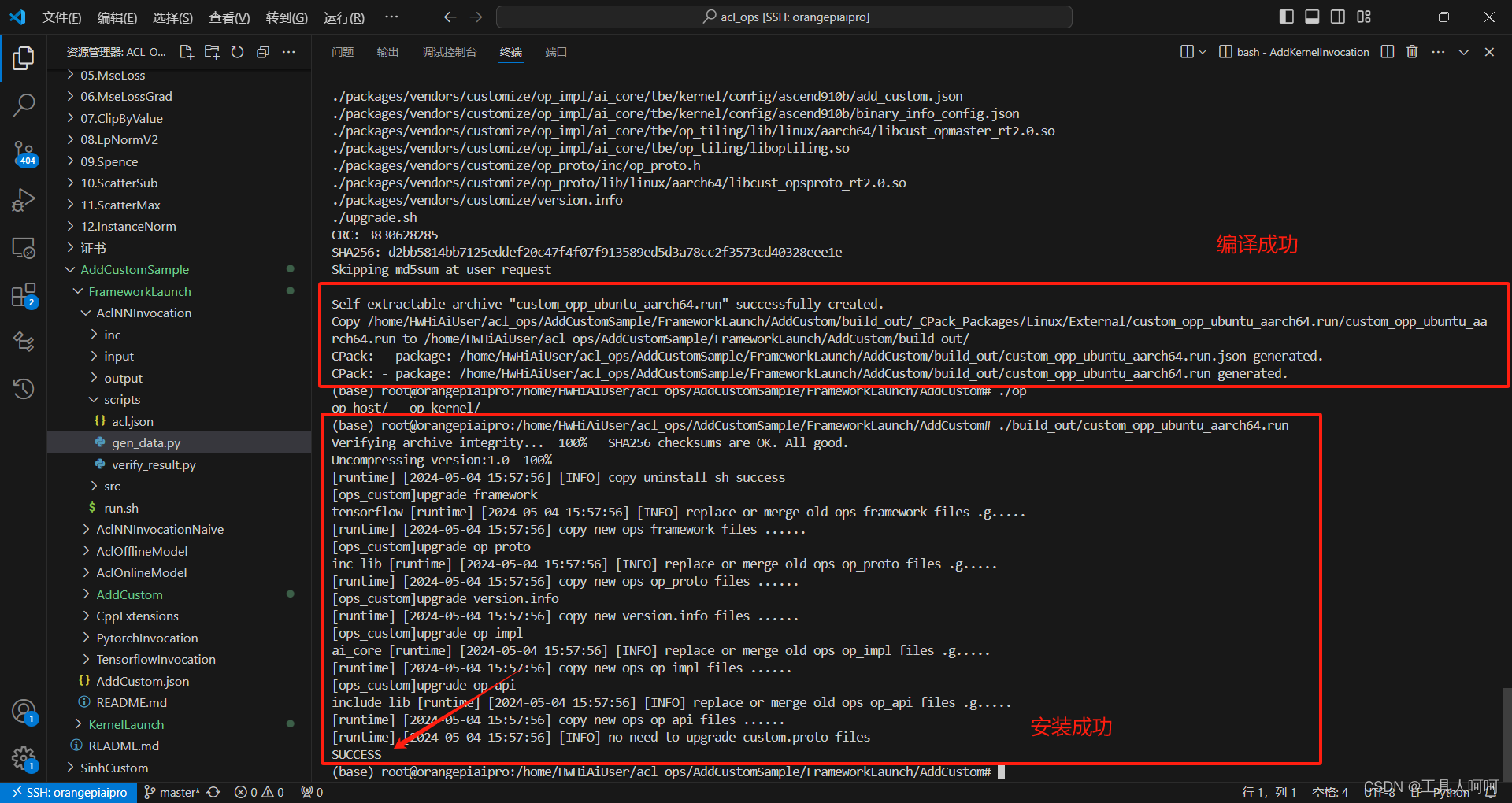
3、AclNN
在算子大赛的时候,这个是由官方发布的(就是可能有错误),我们直接使用即可,一般测试能通过,就会有4-8分(10分满分)。
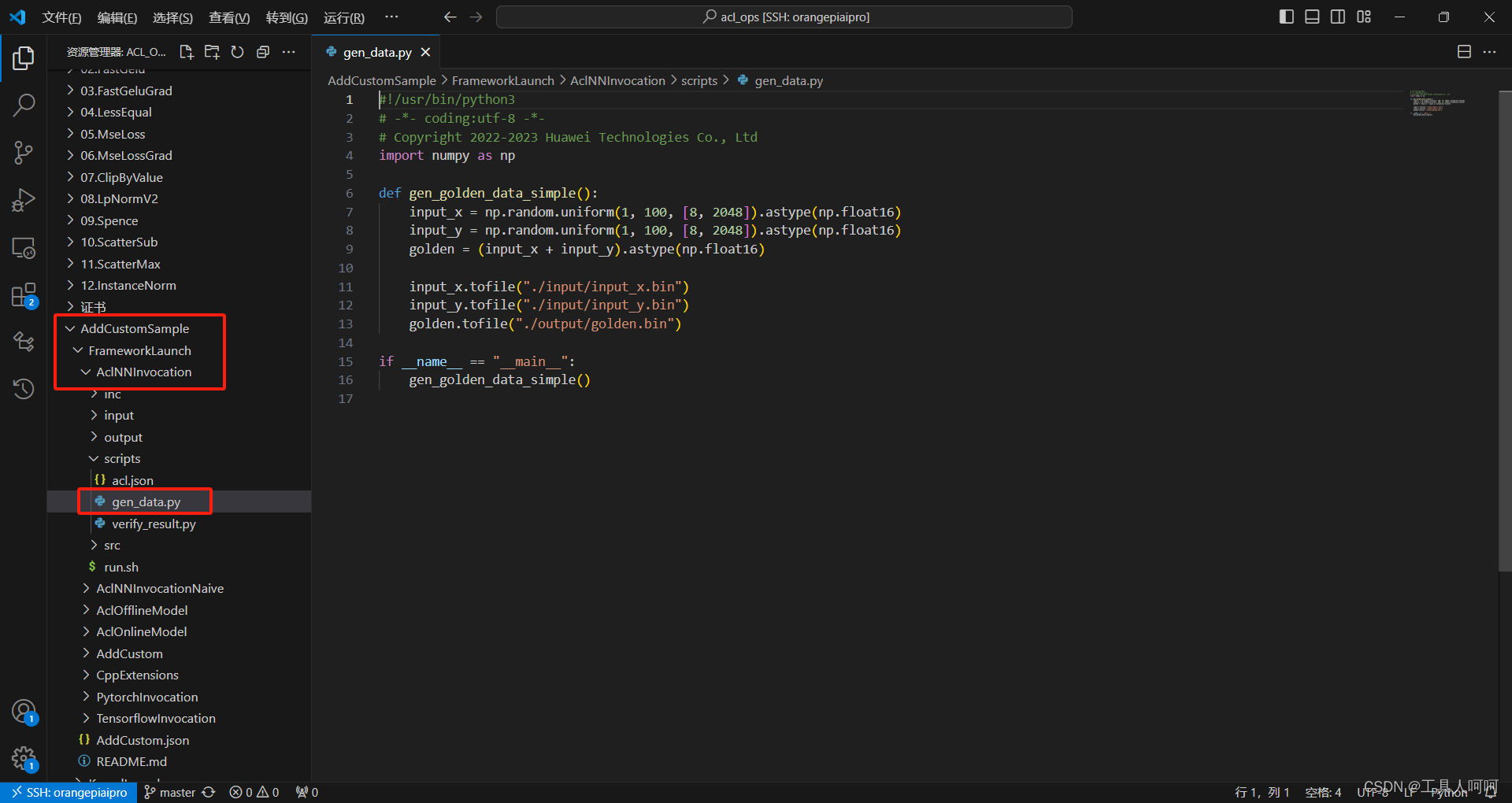
这里的gen_data和kernelLaunch里是一样的,我们执行以下命令,验证算子正确与否。
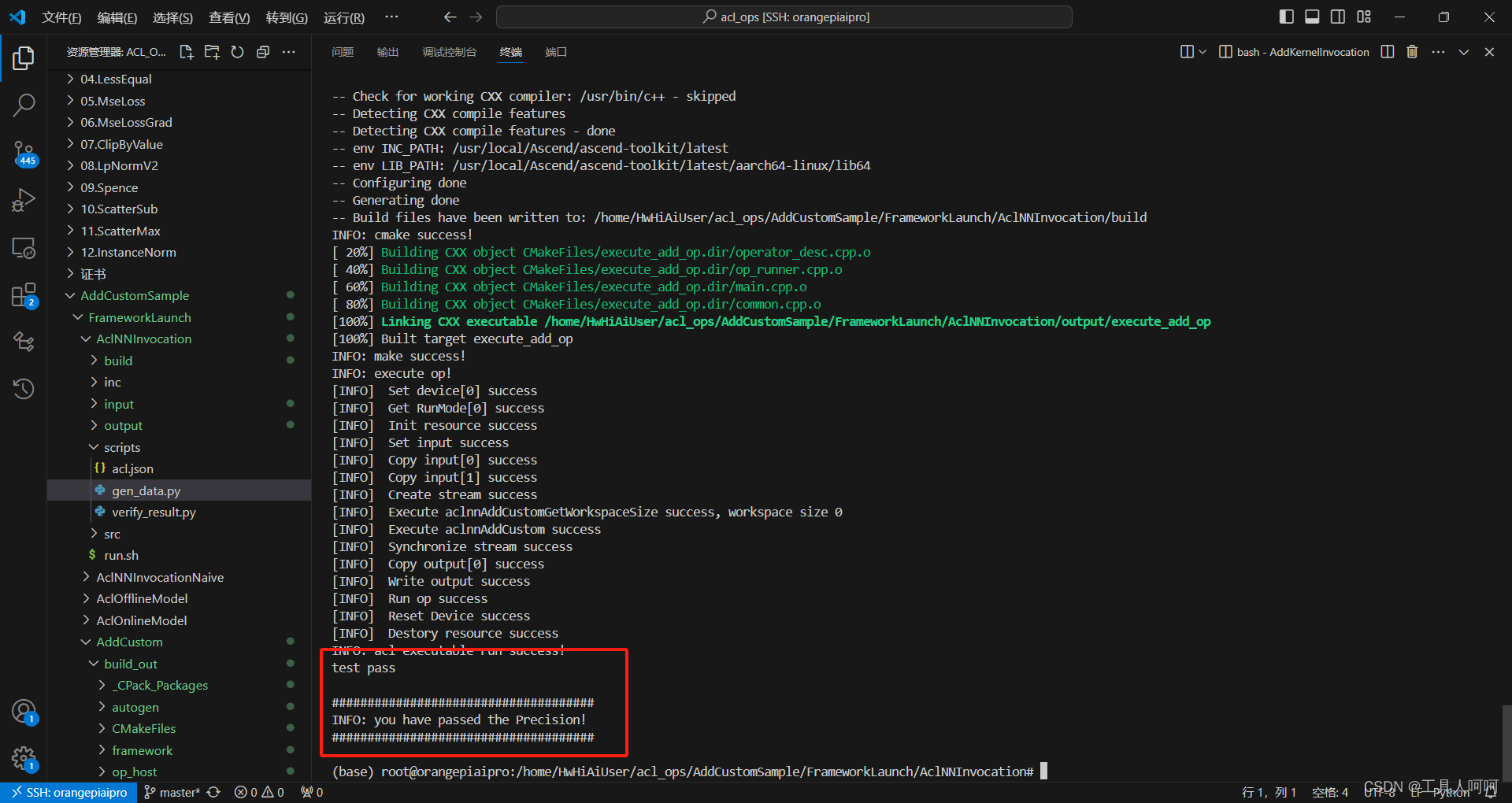
bash run.sh测试通过会有如下提示
2、Addcdiv算子
打开目录operator/AddcdivCustomSample
大部分与add算子相似,因此我们这里只看op_host和op_kernel部分。
在头文件中你会发现多了许多东西,所有的东西我们都需要传入kernel侧。具体实现过程就去阅读代码吧,就是这个案例也是赶出来的,可能里面的切分策略不是最好的,但是确实是能用的。
#ifndef ADDCDIV_CUSTOM_TILING_H#define ADDCDIV_CUSTOM_TILING_H#include "register/tilingdata_base.h"namespace optiling {BEGIN_TILING_DATA_DEF(AddcdivCustomTilingData) TILING_DATA_FIELD_DEF(float, value); //参与计算的标量 TILING_DATA_FIELD_DEF(uint32_t, blockLength); TILING_DATA_FIELD_DEF(uint32_t, tileNum); TILING_DATA_FIELD_DEF(uint32_t, tileLength); TILING_DATA_FIELD_DEF(uint32_t, lasttileLength); TILING_DATA_FIELD_DEF(uint32_t, formerNum); TILING_DATA_FIELD_DEF(uint32_t, formerLength); TILING_DATA_FIELD_DEF(uint32_t, formertileNum); TILING_DATA_FIELD_DEF(uint32_t, formertileLength); TILING_DATA_FIELD_DEF(uint32_t, formerlasttileLength); TILING_DATA_FIELD_DEF(uint32_t, tailNum); TILING_DATA_FIELD_DEF(uint32_t, tailLength); TILING_DATA_FIELD_DEF(uint32_t, tailtileNum); TILING_DATA_FIELD_DEF(uint32_t, tailtileLength); TILING_DATA_FIELD_DEF(uint32_t, taillasttileLength); END_TILING_DATA_DEF;REGISTER_TILING_DATA_CLASS(AddcdivCustom, AddcdivCustomTilingData)}#endif // ADDCDIV_CUSTOM_TILING_H以下为op_kernel内的部分代码
private: TPipe pipe; // TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY, inQueueZ; TQue<QuePosition::VECIN, BUFFER_NUM> inQueueIN; TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueOUT; GlobalTensor<half> xGm; GlobalTensor<half> yGm; GlobalTensor<half> zGm; GlobalTensor<half> outGm; half value; uint32_t blockLength; uint32_t tileNum; uint32_t tileLength; uint32_t lasttileLength; uint32_t formerNum; uint32_t formerLength; uint32_t formertileNum; uint32_t formertileLength; uint32_t formerlasttileLength; uint32_t tailNum; uint32_t tailLength; uint32_t tailtileNum; uint32_t tailtileLength; uint32_t taillasttileLength;};extern "C" __global__ __aicore__ void addcdiv_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR out, GM_ADDR workspace, GM_ADDR tiling) { GET_TILING_DATA(tiling_data, tiling); // TODO: user kernel impl KernelAddcdiv op; uint32_t tilingKey = 1; if (TILING_KEY_IS(1)) { tilingKey = 1; } else if (TILING_KEY_IS(2)) { tilingKey = 2; } else { tilingKey = 1; } op.Init(x, y, z, out, tiling_data.value, tiling_data.blockLength, tiling_data.tileNum, tiling_data.tileLength, tiling_data.lasttileLength, tiling_data.formerNum, tiling_data.formerLength, tiling_data.formertileNum, tiling_data.formertileLength, tiling_data.formerlasttileLength, tiling_data.tailNum, tiling_data.tailLength, tiling_data.tailtileNum, tiling_data.tailtileLength, tiling_data.taillasttileLength, tilingKey); op.Process();}#ifndef __CCE_KT_TEST__// call of kernel functionvoid addcdiv_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z, uint8_t* out, uint8_t* workspace, uint8_t* tiling) { addcdiv_custom<<<blockDim, l2ctrl, stream>>>(x, y, z, out, workspace, tiling);}#endif三、编写自己的算子
1、搭建框架
我们可以使用参考add算子搭建以下目录结构。以下文件夹内的文件没有特别说明就直接从add算子工程内复制。
myCustom├── AclNNInvocation│ ├── inc│ ├── scripts│ └── src│ ├── run.sh├── myCustom <-由msopgen工具生成├── KernelLaunch│ ├── myCustom.cpp│ ├── cmake│ ├── CMakeLists.txt│ ├── data_utils.h│ ├── run.sh│ └── scripts└── myCustom.json2、 KernelLaunch编写
1、myCustom.cpp
我们直接cv add算子的,对输入做下修改,然后修改compute就行了。
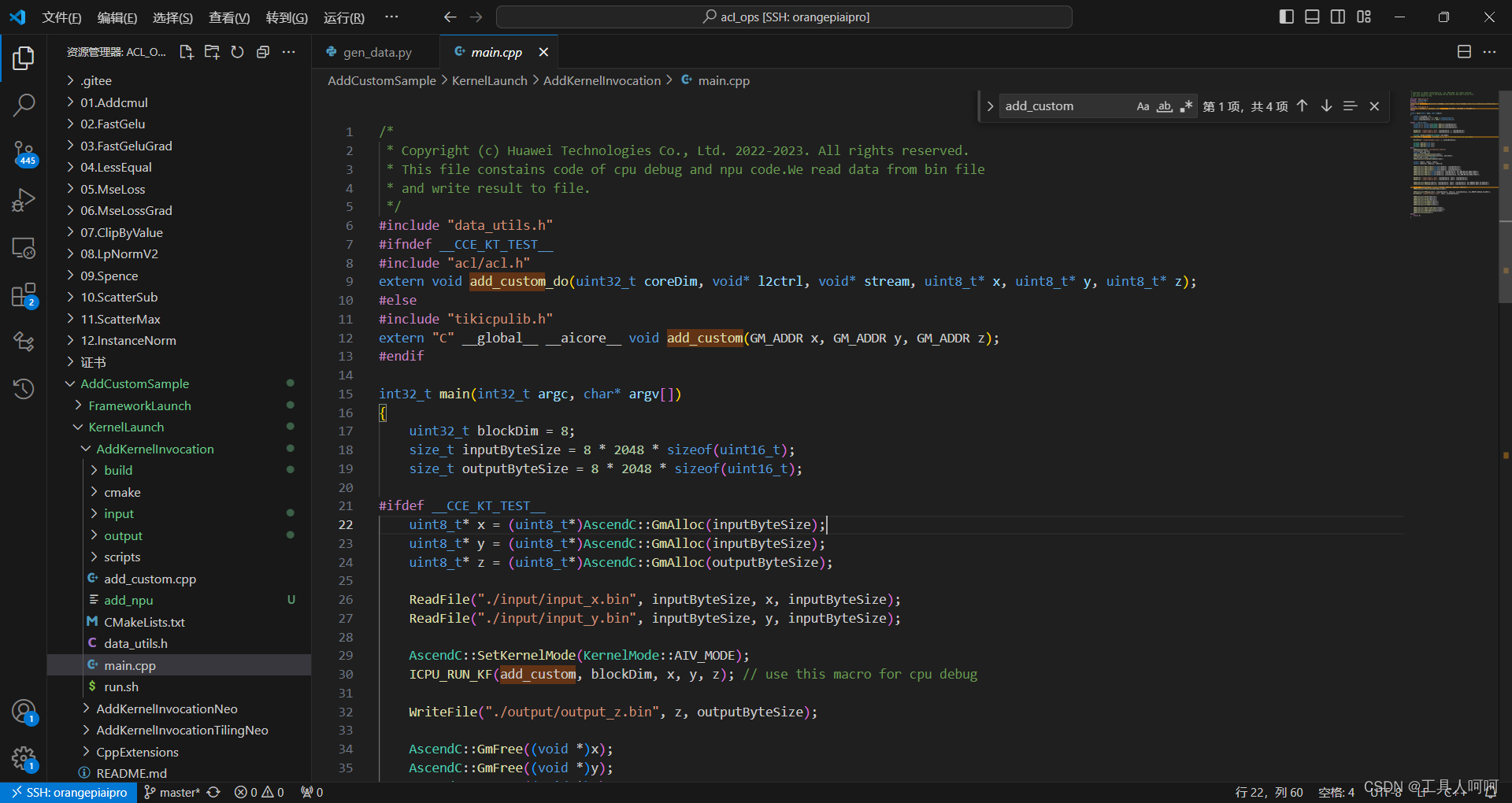
2、main.cpp
这里主要是将算子名称以及传入的参数修改下
3、scripts/gen_data.py
这里根据你要实现的代码编写生成数据和真值的程序就行了,在比赛时,我们可以直接从官方给出的AclNN中取。
3、 framework编写
在kernelLaunch测试通过后我们直接修改myCustom.json。如果是多个数据类型,如下所示。
[ { "op": "myCustom", "language": "cpp", "input_desc": [ { "name": "x", "param_type": "required", "format": [ "ND","ND" ], "type": [ "fp16","fp32" ] } ], "output_desc": [ { "name": "y", "param_type": "required", "format": [ "ND","ND" ], "type": [ "fp16","fp32" ] } ] }]然后生成工程(具体目录请自行修改)
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/bin/msopgen gen -i /home/HwHiAiUser/myCustom/myCustom.json -c ai_core-ascend310B1 -lan cpp -out /home/HwHiAiUser/myCustom/myCustom接着就是参考add和addcdiv算子在op_host中实现tiling策略,将kernelLaunch中测试通过的代码加上tiling相关的代码后搬运到op_kernel。编译安装算子。
4、 Aclnn测试
这里因为我做的是比赛里给出的题目,因此直接使用官方给的案例进行测试。对于自定义算子,除修改gen_data外,我们还需要修改op_runner以及main.cpp。
四、torch_npu重新编译(可选)
参考仓库说明:https://gitee.com/ascend/op-plugin
五、常用api
为了简化使用,以下仅列出常用的2级接口,如需高性能实现,请使用0级接口。310b系列似乎不支持高级api,因此也不列出了。详细内容请直接看api文档
| 名称 | 功能 | 表达式 | 二级接口样例 |
|---|---|---|---|
| Exp | 按元素取自然指数 | 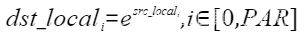 | Exp(dstLocal, srcLocal, 512); |
| Abs | 按元素取绝对值 | 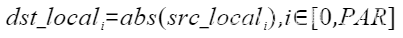 | Abs(dstLocal, srcLocal, 512); |
| Reciprocal | 按元素取倒数 | 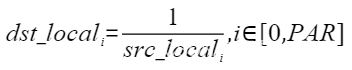 | Reciprocal(dstLocal, srcLocal, 512); |
| Sqrt | 按元素做开方 | 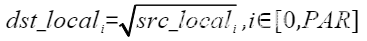 | Sqrt(dstLocal, srcLocal, 512); |
| Ln | 按元素取自然对数 | 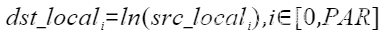 | Ln(dstLocal, srcLocal, 512); |
| Add | 按元素求和 | 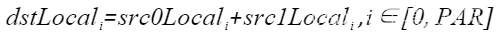 | Add(dstLocal, src0Local, src1Local, 512); |
| Mul | 按元素求积 | 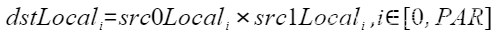 | Mul(dstLocal, src0Local, src1Local, 512); |
| Adds/Muls | 矢量内每个element与标量求和/积 | 同上 | Adds(dstLocal, srcLocal, half(2), 512); |
| Sub | 按元素求差 | 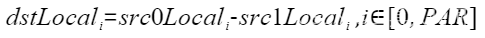 | Sub(dstLocal, src0Local, src1Local, 512); |
| Div | 按element求商 | 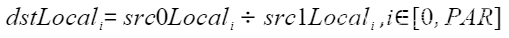 | Div(dstLocal, src0Local, src1Local, 512); |
| Max | 按element求最大值 | 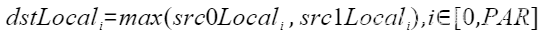 | Max(dstLocal, src0Local, src1Local, 512); |
| Min | 按element求最小值 | 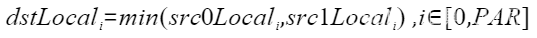 | Min(dstLocal, src0Local, src1Local, 512); |
| Duplicate | 将一个变量或一个立即数,复制多次并填充到向量 | 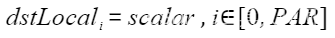 | Duplicate(dstLocal, half(18.0), 512); |
注意:标量双目指令中没有减法和除法,基础api没有log只有ln。
问题
一句话,多看文档,有问题就先去社区搜一下。160001,error code 0这种就直接查代码吧,没有具体原因。
1、fatal error: register/tilingdata_base.h: No such file or directory
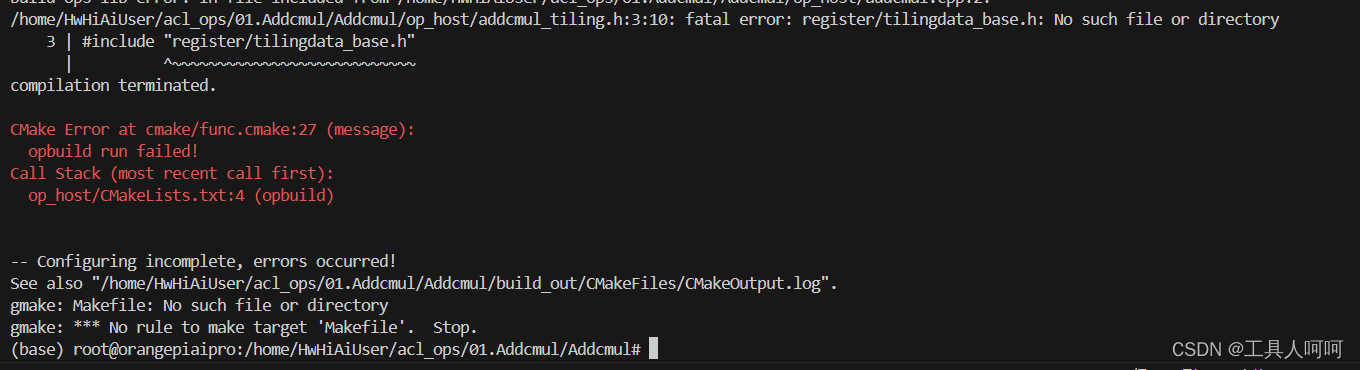
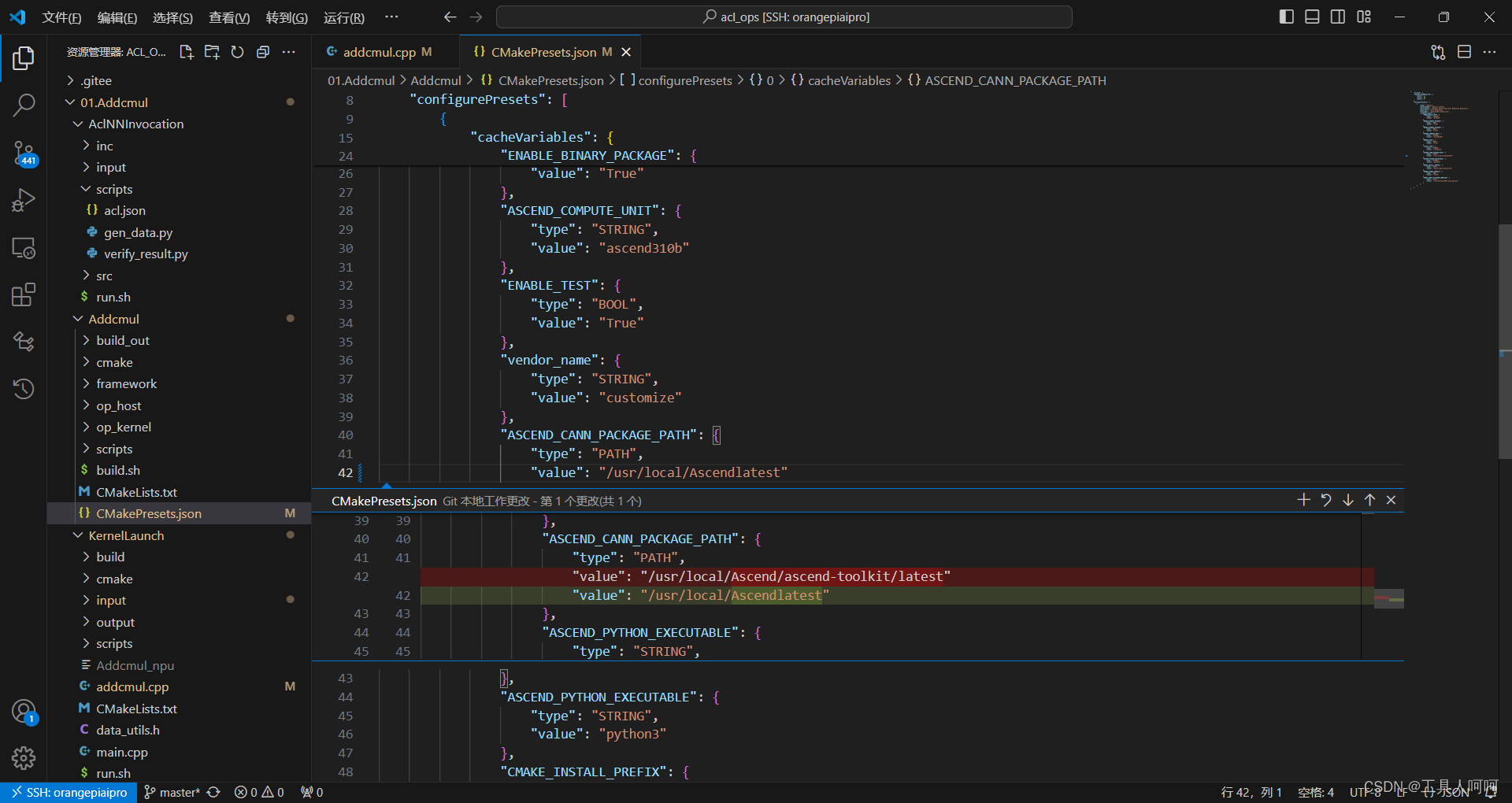
检查一下CANN路径
其他能稳定复现的bug等我后面遇到了再补充解决办法吧。
总结
也许,有时歪门邪道比正道更简单。不要被文档和案例限制了,不要问能不能,跑下试试最快。
就像adds直接乘标量不好使,那就直接把这个标量填满整个local,直接用张量去计算嘛。而且这样能用的api还更多呢。