这段代码首先提示用户输入一个字符串,然后使用fgets函数读取输入的字符串。接下来,使用一个循环遍历输入字符串中的每个字符,如果字符是英文字符(使用isalpha函数进行判断),则计数器 count 加一。最后,打印出统计结果。
#include <stdio.h>#include <ctype.h>int main() { char input[100]; printf("请输入一个字符串: "); fgets(input, sizeof(input), stdin); int count = 0; for (int i = 0; input[i] != '\0'; i++) { if (isalpha(input[i])) { count++; } } printf("英文字符数: %d\n", count); return 0;}请注意,上述代码将包括所有的英文字母(包括大写和小写字母),如果你只想统计小写字母或者大写字母,可以在判断字符时,使用islower()函数(统计小写字母)或者isupper()函数(统计大写字母)来代替isalpha()函数。
要统计C语言中26个英文字母的字符数,你可以使用C语言的字符处理函数来实现。下面是一个简单的示例代码:
#include <stdio.h>#include <ctype.h>int main() { char input[100]; printf("请输入一个字符串: "); fgets(input, sizeof(input), stdin); int count = 0; for (int i = 0; input[i] != '\0'; i++) { if (isalpha(input[i]) && islower(input[i])) { count++; } } printf("小写英文字母数: %d\n", count); count = 0; for (int i = 0; input[i] != '\0'; i++) { if (isalpha(input[i]) && isupper(input[i])) { count++; } } printf("大写英文字母数: %d\n", count); return 0;}
这段代码首先提示用户输入一个字符串,然后使用fgets函数读取输入的字符串。接下来,使用两个循环分别遍历输入字符串中的每个字符,如果字符满足条件(小写字母或大写字母),则相应计数器加一。最后,打印出统计结果。
请注意,上述代码中的两个循环分别用于统计小写字母和大写字母的数量。你可以根据需要进行修改,只保留其中一个循环来统计所需的英文字母数量。
要分别统计C语言中每个26个英文字母的字符数,你可以使用C语言的字符处理函数来实现。下面是一个示例代码:
代码分析
首先,定义了一个字符数组 input 来存储用户输入的字符串。然后,使用 fgets 函数获取用户输入的字符串,并存储在 input 中。
接下来,定义了一个大小为 26 的整数数组 count,用于存储每个字母的个数。初始时,将数组中的每个元素初始化为 0。
然后,使用一个 for 循环遍历输入字符串中的每个字符。若字符是字母(使用 isalpha 函数进行判断),则将其转换为小写字母(使用 tolower 函数)。接着,通过将字符减去小写字母 ‘a’ 的 ASCII 码值来计算该字母在 count 数组中的索引位置。然后,将相应索引位置处的计数器加一,以统计该字母的个数。
最后,使用另一个 for 循环遍历 count 数组,依次输出每个字母及其对应的个数。在输出时,通过将索引位置加上小写字母 ‘a’ 的 ASCII 码值来还原出具体的字母。
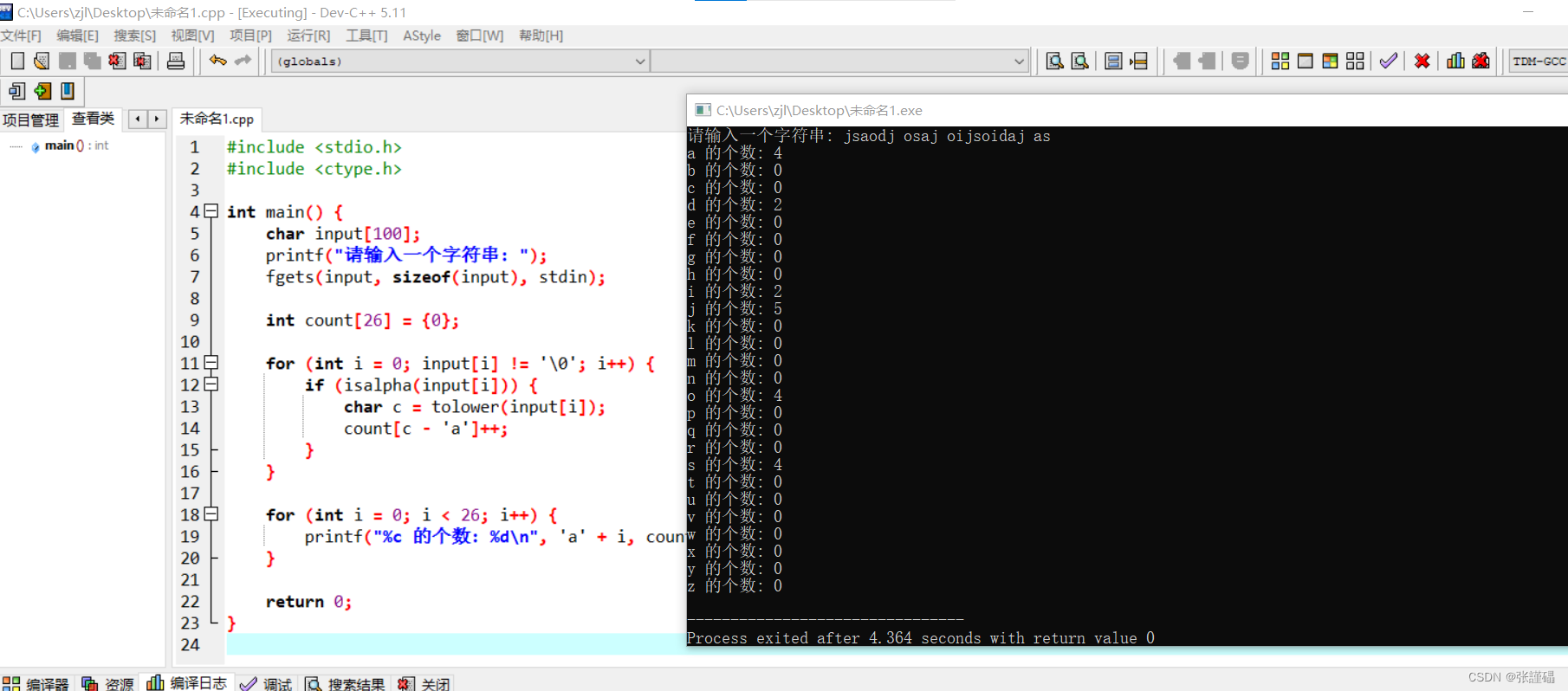
这段代码的运行结果是,首先要求用户输入一个字符串,然后输出每个字母在输入字符串中出现的个数。例如,如果用户输入字符串 “Hello, World!”,则输出结果会告诉我们字母 ‘e’ 在字符串中出现了 1 次,字母 ‘l’ 出现了 3 次,字母 ‘o’ 出现了 2 次,等等。
#include <stdio.h>#include <ctype.h>int main() { char input[100]; printf("请输入一个字符串: "); fgets(input, sizeof(input), stdin); int count[26] = {0}; for (int i = 0; input[i] != '\0'; i++) { if (isalpha(input[i])) { char c = tolower(input[i]); count[c - 'a']++; } } for (int i = 0; i < 26; i++) { printf("%c 的个数: %d\n", 'a' + i, count[i]); } return 0;}
这段代码首先提示用户输入一个字符串,然后使用fgets函数读取输入的字符串。接下来,定义一个大小为26的整数数组 count 用于分别统计每个英文字母的个数,初始值设为0。然后,使用一个循环遍历输入字符串中的每个字符,如果字符是英文字符(使用isalpha函数进行判断),则将该字符转换为小写字母(使用tolower函数),并根据其ASCII码值减去 ‘a’ 的ASCII码值来计算在 count 数组中的索引位置,然后将相应的计数器加一。最后,使用另一个循环遍历 count 数组,分别打印出每个英文字母和其对应的个数。
请注意,上述代码中利用了字符的ASCII码值进行索引计算。在ASCII码中,小写字母 ‘a’ 的值为97,大写字母 ‘A’ 的值为65,通过减去相应的ASCII码值,可以得到其在 count 数组中的正确索引位置。这样,最终输出时可以根据索引位置还原出具体的英文字母。
这段代码的功能是统计输入字符串中每个英文字母的个数,并按字母顺序输出每个字母的个数。
内容补充:
fgets(input, sizeof(input), stdin); 这行代码是用来从标准输入流 stdin 中读取一行字符,并将其存储到字符数组 input 中。具体解释如下:
input 是存储输入字符串的字符数组,通过 char input[100] 定义。sizeof(input) 是用来获取 input 数组的大小,即可容纳的最大字符数。stdin 是标准输入流,通常是指键盘输入。 因此,这行代码的作用是从用户键盘输入中读取一行字符串,保存在 input 数组中。如果输入的字符串超出了数组的长度,可能会导致溢出,因此在实际应用中需要谨慎处理边界情况。
希望能帮到你,如果有任何其他问题,欢迎继续提问。
sizeof
sizeof 是一个在 C 和 C++ 中的操作符,用来计算数据类型或变量在内存中所占的字节数。在使用时可以有两种形式:
sizeof(type):返回数据类型 type 所占的字节数。sizeof(expr):返回表达式 expr 计算结果所占的字节数。 例如,sizeof(int) 返回 int 类型的字节数,一般情况下是 4 个字节;sizeof(char) 返回 char 类型的字节数,一般情况下是 1 个字节。在数组的情况下,sizeof 也可以用来计算整个数组所占内存的大小。
在 C 和 C++ 中,sizeof 的返回值是 size_t 类型,这是一个无符号整数类型,其大小足以表示任意对象的大小。
isalpha
isalpha 是C语言标准库 <ctype.h> 中定义的函数,用于判断一个字符是否为字母。
函数原型如下:
int isalpha(int c);
isalpha 函数接受一个整型参数 c,它是要进行判断的字符,通常以 ASCII 码的形式表示。如果 c 是一个字母(大写或小写),则函数返回非零值(通常为1),否则返回零。
例如,isalpha('a') 和 isalpha('A') 都会返回非零值,而 isalpha('1') 则会返回零。
这个函数通常用于判断输入的字符是否为字母,以便在处理字符串时进行相应的操作。
tolower
tolower 是 C 语言标准库 <ctype.h> 中定义的函数,用于将一个字符转换为小写形式。
函数原型如下:
int tolower(int c);
tolower 函数接受一个整型参数 c,它是要进行转换的字符,通常以 ASCII 码的形式表示。如果 c 是一个大写字母,则函数返回相应的小写字母;否则,返回原始的字符值。
例如,tolower('A') 会返回小写字母 ‘a’,而 tolower('3') 则会返回 ‘3’,因为 ‘3’ 实际上不是一个字母。
这个函数通常用于将输入的字符串中的字母统一转换为小写形式,便于进行大小写不敏感的比较和处理。